Un boletín reciente de AINews, la sección de curaduría diaria de Latent Space, sintetizó una idea que viene circulando en Twitter desde hace semanas: la disciplina de ingeniería con agentes ya no pasa por escribir el mejor prompt, sino por diseñar loops que prompteen agentes en tu lugar. Tres voces la resumen mejor que cualquier otra.
¿Quiénes están empujando la tesis?
Peter Steinberger, más conocido como Steipete y ex fundador del cliente iOS PSPDFKit, lanzó el recordatorio con más eco:
"Aquí va tu recordatorio mensual: no deberías estar prompteando a los coding agents nunca más. Deberías estar diseñando los loops que prompteen a tus agentes."
Boris Cherny, ingeniero de Anthropic detrás de Claude Code, remató con la misma tesis en menos palabras:
"Ya no prompteo a Claude. Escribo loops, los loops hacen el trabajo."
Andrej Karpathy, en su explicación sobre Autoresearch, llevó el argumento al terreno investigativo, con foco en cómo escalar el uso de las herramientas actuales.
"Para sacar el máximo de las herramientas disponibles hay que quitarse a uno mismo como cuello de botella. No podés estar ahí para promptear la siguiente cosa. Tenés que sacarte del medio. El juego ahora es maximizar tu throughput de tokens y no estar en el loop. La pregunta es cómo refactorizar todas las abstracciones para que yo tenga que arreglarlo una vez y darle go."
¿Por qué la idea gana tracción?
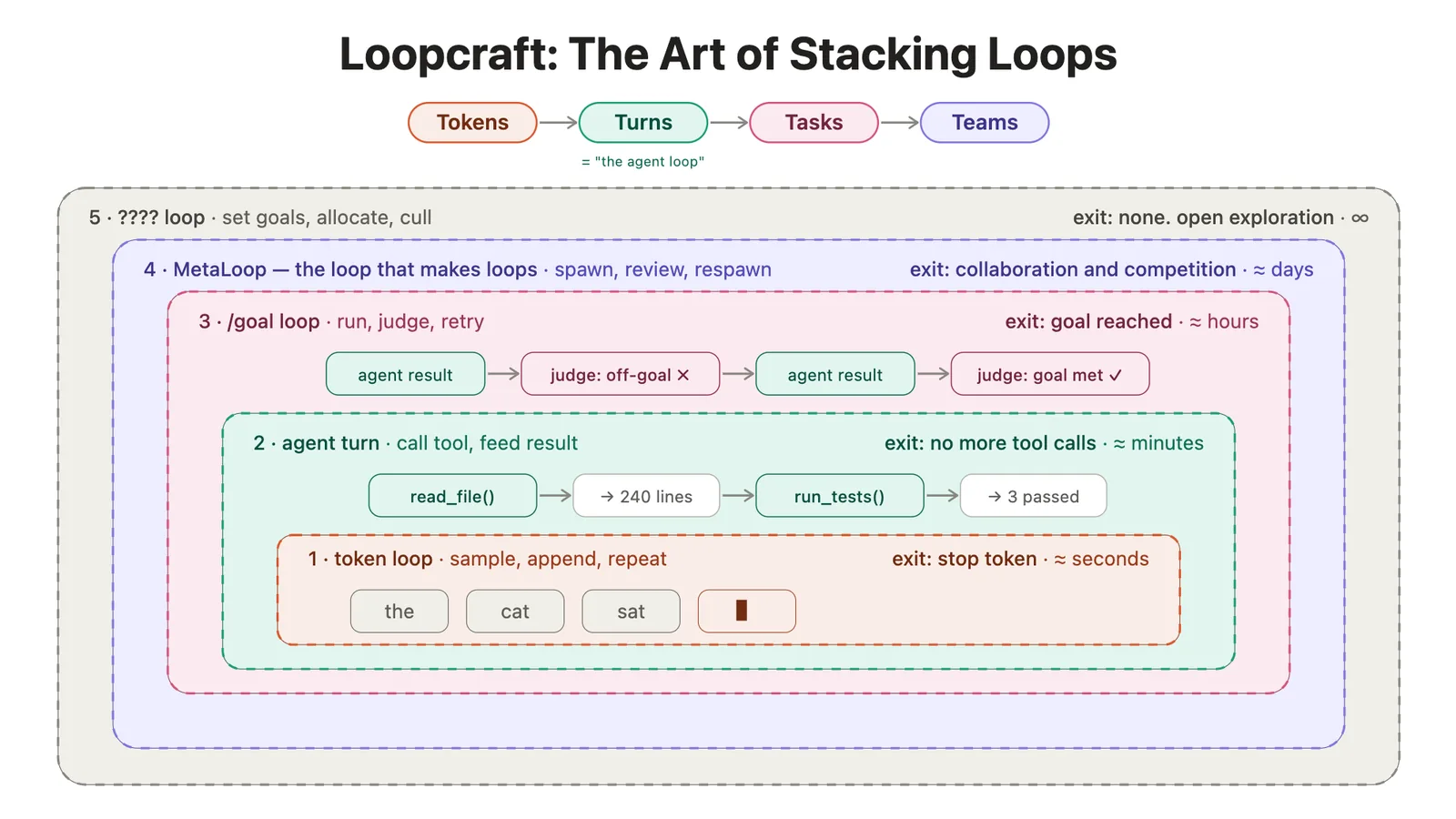
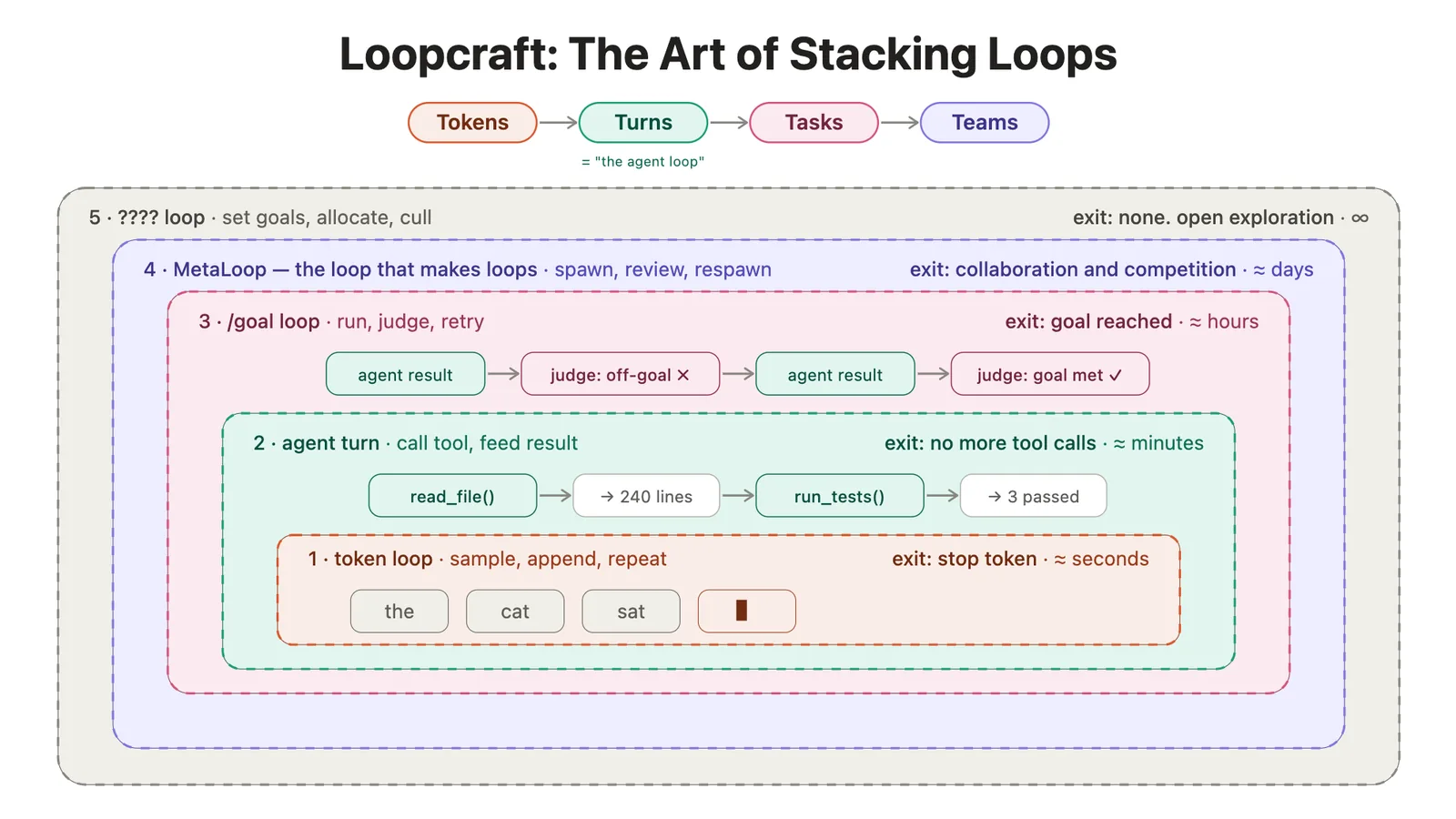
La observación central del boletín es que la mayoría de la industria subestima cuántos loops ya están corriendo en paralelo cuando un equipo despliega agentes en producción. AINews lo grafica con una ilustración de un stack de loops anidados: cada capa orquesta la de abajo, y el operador humano queda relegado a definir objetivos y validar la salida final.

La tesis del newsletter es que el juego del próximo siglo será apilar loops de forma tan efectiva como sea posible.
En las primeras etapas de cada fase será valioso saber cuándo bajar un nivel para tomar el control manual (por confiabilidad), pero a medida que los modelos mejoran será mucho más rentable saber cuándo subir uno más (por leverage).
La Salty Lesson
Richard Sutton, referente del reinforcement learning, dejó registrada la Bitter Lesson: los métodos que se benefician del cómputo escalado terminan ganando a las técnicas cuidadosamente diseñadas por humanos. AINews propone su corolario para agentes y lo llama Salty Lesson:
"No arregles cosas vos mismo, como venís haciendo hasta ahora. En cambio, enfocate en sistemas que escalan con más agentes, como objetivos y orquestación."
La idea es que el operador que insiste en meterse en cada bucle interno pierde frente al que arma la abstracción una sola vez y deja correr. La analogía que usa Geoffrey Huntley, uno de los oradores del AI Engineer World's Fair, va en la misma dirección: el desarrollador termina pareciéndose a un ingeniero de locomotoras, cuya tarea es mantener el tren en las vías, no fabricar cada durmiente a mano.
¿Qué implica para equipos técnicos?
Para equipos que usan Claude Code, Cursor, Codex u otras herramientas de agente, la implicancia práctica es concreta:
- Dejar de invertir horas en el prompt "perfecto" para cada tarea.
- Empezar a modelar el bucle: qué evento gatilla al agente, qué señales le dan feedback, cuándo se detiene y qué agente supervisa a otros.
- Aceptar que el rol humano se corre hacia arriba de la pila: definir metas, validar salidas, dosificar el gasto de tokens.
En equipos que ya operan sobre esta lógica —Anthropic con Claude Tag, OpenAI con Codex, y proyectos del ecosistema Warp o Factory— el cuello de botella pasa a ser el diseño del sistema, no la calidad del prompt individual.