Hace veinte años, era sencillo para el kernel de un sistema operativo entrar en estado de inactividad o idle: cuando no había tareas que ejecutar, se programaba el llamado “bucle de inactividad” (idle loop). Los primeros bucles de inactividad eran básicamente bucles infinitos vacíos que no hacían nada mientras esperaban a que ocurriera la siguiente interrupción. Esto ahorraba energía simplemente evitando la ejecución de instrucciones que necesitaban componentes que consumen mucha energía, como la memoria caché o la unidad de punto flotante (FPU).
Con el paso del tiempo, la tecnología cambiante ha permitido la introducción de múltiples mecanismos de hardware adicionales para reducir el consumo de energía. Con estas nuevas opciones disponibles en la actualidad, el bucle de inactividad es el responsable de elegir y desplegar la “mejor” forma de quedar inactivo.
Como breve recordatorio, entrar y regresar de un estado de inactividad tiene un costo, y ese costo puede medirse tanto en tiempo como en energía. Normalmente, el estado de inactividad más superficial es “casi gratuito” de entrar y salir, mientras que los estados de inactividad más profundos tienen costos cada vez más altos para entrar y salir. Si el sistema entra en un estado de inactividad profundo y se despierta poco después de dormir, entonces se habrá desperdiciado energía porque el costo energético para entrar en el estado de inactividad profundo es mayor que la energía ahorrada mientras se residía en ese estado.
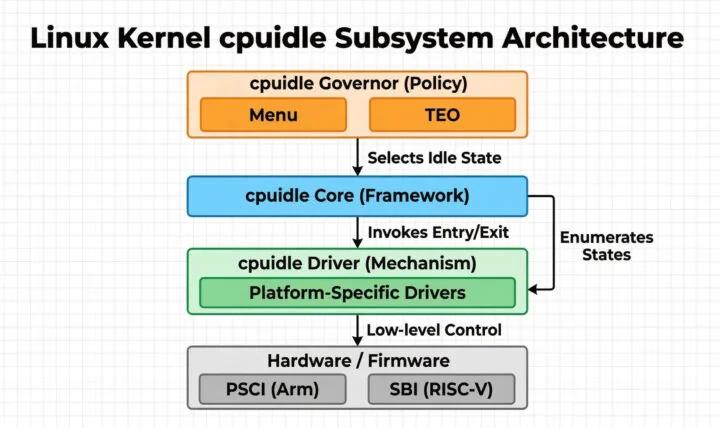
cpuidle es el subsistema del kernel que gobierna las transiciones de los estados de inactividad. Al igual que cpufreq, el mecanismo se separa de la política mediante el uso de drivers y gobernadores.
- Drivers de *cpuidle*: proporcionan el mecanismo necesario para entrar y salir de los estados de inactividad. Estos enumeran los estados de inactividad disponibles para el gobernador. Como parte de eso, describen al gobernador las propiedades de ahorro de energía de cada estado. Finalmente, los drivers son capaces de entrar en los estados de inactividad a petición del gobernador. Los drivers pueden personalizarse completamente para las propiedades únicas de cada System-on-Chip (SoC). Sin embargo, los estados de inactividad de la CPU suelen estar bien soportados por el firmware de la plataforma de bajo nivel y se ponen a disposición del kernel mediante interfaces estándar como PSCI (Power State Coordination Interface) en Arm y SBI (Supervisor Binary Interface) en RISC-V. Por lo tanto, aunque existe margen para drivers por cada SoC, en realidad, estos se están volviendo inusuales. La mayoría de las arquitecturas modernas, incluidas Arm y RISC-V, definen interfaces estandarizadas que permiten que un único driver de Arm y un único driver de RISC-V sean compartidos por una amplia gama de familias de SoC.
- Gobernadores de *cpuidle*: proporcionan la política y son responsables de elegir el “mejor” estado de inactividad de entre los disponibles. Los gobernadores utilizan la información de los drivers, junto con los datos recopilados sobre eventos históricos o futuros conocidos (como los despertares por temporizador o timers), para realizar una “conjetura educada” sobre cuándo la CPU necesitará abandonar el estado de inactividad debido a una interrupción. Basándose en el tiempo estimado de despertar, puede seleccionar el estado de inactividad que probablemente ahorre la mayor cantidad de energía.

¿Cómo toman decisiones los gobernadores de cpuidle?
Los gobernadores de cpuidle reciben datos sobre las características físicas del sistema a través del driver de cpuidle. Esto toma la forma de una lista de estados de inactividad, donde cada estado está anotado con una residencia objetivo (target residency). La residencia objetivo es el tiempo mínimo que una CPU debe pasar en un estado de inactividad para ahorrar energía en comparación con los estados más superficiales. En otras palabras, aunque la residencia objetivo se mide en tiempo, en realidad proporciona datos que permiten al gobernador comparar el costo energético de entrar y salir de los diferentes estados de inactividad. Existen tres posibilidades cuando un sistema abandona un estado de inactividad:
- Si un sistema se despierta antes de alcanzar el tiempo de residencia objetivo, entonces el sistema desperdició energía al seleccionar un estado de inactividad que era demasiado profundo.
- Si un sistema permanece en un estado de inactividad durante más tiempo que el tiempo de residencia objetivo de un estado de inactividad más profundo (si lo hay), entonces el sistema desperdició energía porque el estado de inactividad más profundo habría ahorrado más energía.
- Si el sistema se despertó después de alcanzar el tiempo de residencia objetivo para nuestro estado seleccionado, pero antes de alcanzar la residencia objetivo de un estado más profundo, entonces la elección fue óptima.
Todos los gobernadores de cpuidle mantienen un seguimiento de los tiempos históricos de entrada y salida de inactividad; de hecho, los hacen visibles para cada CPU en /sys/devices/system/cpu/cpu/cpuidle, ¡así que puede revisarlos usted mismo!
Los gobernadores asumen que la duración de los períodos de inactividad recientes puede utilizarse para predecir el futuro. De hecho, el gobernador ladder (utilizado en sistemas con un tick de planificador regular) y el gobernador haltpoll (un gobernador especializado para máquinas virtuales) funcionan exclusivamente utilizando datos históricos.
Otros gobernadores, como menu y teo (orientado a eventos de temporizador), reciben un vistazo al futuro, aunque esa visión es bastante limitada. En general, los drivers no informan cuándo esperan que se activen sus interrupciones, pero hay una interrupción que se puede predecir “perfectamente”: siempre sabemos cuándo vence la próxima interrupción del temporizador o timer. Por lo tanto, el límite superior para cualquier período de inactividad es el tiempo hasta la próxima interrupción del temporizador. Para muchos casos de uso, las interrupciones del temporizador son significativamente más frecuentes que cualquier otra. Eso significa que, siempre que el seguimiento histórico de entrada/salida sugiera que estamos ejecutando un caso de uso dominado por la interrupción del temporizador, entonces este es un excelente predictor del tiempo de inactividad.
El factor final en juego en las decisiones de gobernanza es el costo energético de la toma de decisiones en sí misma. Toda computación tiene un costo energético. No importa si el gobernador toma la mejor decisión si quema demasiada energía tomándola. Esto es especialmente cierto cuando el sistema experimenta períodos de inactividad cortos. En ese caso, ¡tomar una decisión rápida para entrar en el estado de inactividad más superficial es extremadamente deseable!
Los gobernadores menu y teo utilizan el temporizador para informar las decisiones, pero adoptan estrategias diferentes:
- El gobernador menu busca generar un tiempo de sueño predicho tomando el próximo tiempo de despertar y aplicando un factor de corrección derivado de la historia reciente para ajustarlo. Una vez que ha hecho una predicción, puede buscar el mejor estado de inactividad.
- El gobernador teo cuantifica la información histórica en contenedores o “bins” basados en los tiempos de residencia objetivo para cada estado de inactividad. Los datos cuantizados no permiten la predicción del tiempo de inactividad, pero debido a que cada contenedor corresponde a un estado de inactividad específico, ¡aún es capaz de predecir qué estado de inactividad será el mejor! Luego utiliza el próximo tiempo de despertar para mejorar la elección seleccionando un modo más superficial si el temporizador se activará pronto.

Detalles adicionales sobre los gobernadores menu y teo se encuentran en la documentación del kernel de Linux.
Ajuste del comportamiento de inactividad para un menor consumo de energía
Todos los gobernadores de cpuidle comparten algo en común con el gobernador schedutil: los gobernadores en sí mismos no ofrecen ningún valor ajustable o tunable para modificar sus heurísticas. Como vimos antes, eso no significa que no haya nada que podamos ajustar, solo que para conservar energía (o mejorar el rendimiento), tenemos que mirar fuera del propio gobernador. Hoy discutiremos algunas de esas opciones.
Pasar a modo tickless
Durante muchos años, Linux gestionó el flujo del tiempo estableciendo un temporizador que se activaba 100 veces por segundo y utilizando este “scheduler tick” o tick del planificador para intercambiar procesos y manejar la expiración del temporizador en los drivers. Este tick es configurable, y el tick del planificador se puede establecer en 100, 250 o 1000 Hz. Cambiar CONFIG_HZ puede tener efectos profundos en el comportamiento del sistema, y es un parámetro ajustable del kernel interesante cuando se busca equilibrar el consumo de energía y la interactividad (aunque qué valor resulta en el menor consumo de energía varía según la carga de trabajo).
Cuando CONFIG_HZ se establece en el valor mínimo y el sistema se despierta 100 veces por segundo, el sistema nunca puede estar inactivo por más de 10 ms. Despertarse con esta frecuencia puede reducir la efectividad de los estados de inactividad profundos y debe evitarse en sistemas que buscan conservar energía de esta manera. Los kernels tickless desactivan el tick del planificador cuando el sistema entra en inactividad (CONFIG_NO_HZ_IDLE=y) o cuando solo hay una única tarea ejecutándose en la CPU (CONFIG_NO_HZ_FULL=y). Configurar cualquiera de las dos opciones permite una residencia más larga en los estados de inactividad. La diferencia exacta entre estas opciones es sutil y no entra en el alcance de este artículo. Consulte NO_HZ: Reducing Scheduling-Clock Ticks si está interesado en aprender más.

Finalmente, debemos notar que tiene poco sentido pasar a modo tickless si hay un driver que se despierta 100 veces por segundo para realizar un sondeo o polling, por ejemplo, de un periférico SPI. Si ha pasado a modo tickless, también debe asegurarse de que el código que se ejecuta en su sistema no introduzca ticks periódicos innecesarios mediante el sondeo de estado. Tenga en cuenta también que si el sondeo no se puede evitar, sigue siendo importante asegurarse de que el driver detenga el sondeo cuando no haya clientes.
Probar un gobernador de cpuidle diferente
Si tiene un sistema tickless, existe la opción de elegir entre dos gobernadores: menu y teo (orientado a eventos de temporizador).
El gobernador menu es el predeterminado y funciona prediciendo cuánto tiempo estará inactivo el sistema. Monitorea los intervalos históricos de despertar y el tiempo de vencimiento de la próxima interrupción del temporizador, filtrándolos para identificar el intervalo de despertar “típico”. Luego utiliza esa predicción para elegir del menú de opciones ofrecidas por el driver de cpuidle.
El gobernador teo utiliza las mismas fuentes de datos, pero realiza un seguimiento de los datos estadísticos para predecir directamente el mejor estado de inactividad, sin predecir exactamente cuánto tiempo espera que el sistema permanezca inactivo. Cuando el sistema se despierta con frecuencia, esto le permite evitar el vistazo (relativamente costoso) a la cola del temporizador, reduciendo los costos energéticos de su toma de decisiones.
El gobernador puede ser inspeccionado y cambiado a través de sysfs en: /sys/devices/system/cpu/cpuidle/current_governor.
Solicitudes de Calidad de Servicio en la Gestión de Energía (PM QoS)
Como se mencionó en las secciones introductorias, entrar o salir del estado de inactividad tiene un costo que puede medirse tanto en tiempo como en energía. El gobernador de cpuidle suele tomar decisiones basadas en el costo energético, pero hay situaciones en las que tenemos que considerar también el costo de tiempo. Por ejemplo, si estamos en un estado de inactividad profundo, puede tomar mucho tiempo volver a poner la CPU en funcionamiento. ¿Qué pasa si llega una interrupción importante durante un estado de inactividad profundo y no respondemos lo suficientemente rápido? No queremos que el sistema inactivo nos haga perder plazos de tiempo real, como rellenar un búfer de audio.
Una forma de resolver esto es desactivar el estado de inactividad profundo, pero hacerlo de forma global causará que se queme energía innecesariamente cuando no se ejecuten aplicaciones sensibles al tiempo. Una mejor manera de abordar esto es asegurar que todos los drivers y el espacio de usuario registren su tolerancia a la latencia con el framework PM QoS. La tolerancia a la latencia es un valor en microsegundos que expresa cuánta latencia adicional debida al estado de inactividad de la CPU puede tolerar un driver o un proceso de espacio de usuario antes de que su rendimiento se degrade. cpuidle elige los valores más bajos entre todos los drivers y procesos y evita que el gobernador adopte estados de inactividad profundos si el tiempo de entrada/salida es demasiado largo. Esto es excelente para sistemas modales donde entrar en estados de inactividad profundos es útil para conservar energía, pero no es apropiado entrar en dichos estados en todos los modos.
Conclusión
En este artículo de blog, hemos cubierto cómo funciona cpuidle y también hemos analizado las formas en que podemos ajustar los sistemas utilizando características modernas basadas en schedutil y el gobernador de inactividad de CPU orientado a eventos de temporizador (teo).
Vía CNX Software.



