
El auge de los modelos de generative AI de código abierto está superando los centros de datos para llegar a máquinas que operan en el mundo físico. Los desarrolladores están ansiosos por desplegar estos modelos en el edge, permitiendo que agentes de IA física y robots autónomos automaticen tareas pesadas.
Un desafío clave es ejecutar de manera eficiente modelos de miles de millones de parámetros en edge devices con memoria limitada. Ante las constantes limitaciones en el suministro de memoria y el aumento de los costos, los desarrolladores se centran en lograr más con menos.
La plataforma NVIDIA Jetson soporta modelos abiertos populares mientras ofrece un sólido rendimiento en tiempo de ejecución y optimización de memoria en el borde. Para los desarrolladores de edge, el footprint de memoria determina si un sistema funciona. A diferencia de los entornos de nube, los dispositivos de borde operan bajo estrictos límites de memoria, donde la CPU y la GPU comparten recursos restringidos.
El uso ineficiente de la memoria puede provocar cuellos de botella, picos de latencia o fallas del sistema. Mientras tanto, las aplicaciones modernas de borde a menudo ejecutan múltiples pipelines —como detección, seguimiento y segmentación— lo que hace que la gestión eficiente de la memoria sea crítica para un rendimiento estable y en tiempo real bajo restricciones de potencia y temperatura.
Optimizar el uso de la memoria ofrece beneficios claros. Los desarrolladores pueden mejorar el rendimiento en el mismo hardware al reducir la sobrecarga y aumentar la concurrencia, permitiendo cargas de trabajo más complejas como LLMs, sistemas multicámara y fusión de sensores. También reduce el costo del sistema al ajustarse a configuraciones de memoria más pequeñas y mejora la eficiencia (rendimiento por vatio) al minimizar los cuellos de botella y maximizar la utilización de la GPU.
Este blog explora estrategias de optimización para ayudar a los desarrolladores a maximizar el rendimiento, la eficiencia y la capacidad en sistemas de borde con recursos limitados.
Edge AI software stack
Profundicemos en la pila de software de tiempo de ejecución para edge devices. Esta no es una guía exhaustiva para la optimización completa de la memoria, sino un framework de referencia para generar ideas y ayudar a los desarrolladores a identificar nuevas formas de mejorar sus pilas. Los ahorros de memoria muestran lo que los equipos de NVIDIA han logrado. Los usuarios experimentados pueden alcanzar eficiencias mayores, mientras que otros pueden usar estos ejemplos como punto de partida para aprovechar mejor los recursos en las plataformas NVIDIA Jetson y NVIDIA IGX.
Este blog explora cinco capas clave, comenzando desde la base con Jetson BSP y NVIDIA JetPack, y subiendo a través del pipeline de inferencia, los frameworks de inferencia y las técnicas de cuantización. Analicemos cada capa paso a paso.
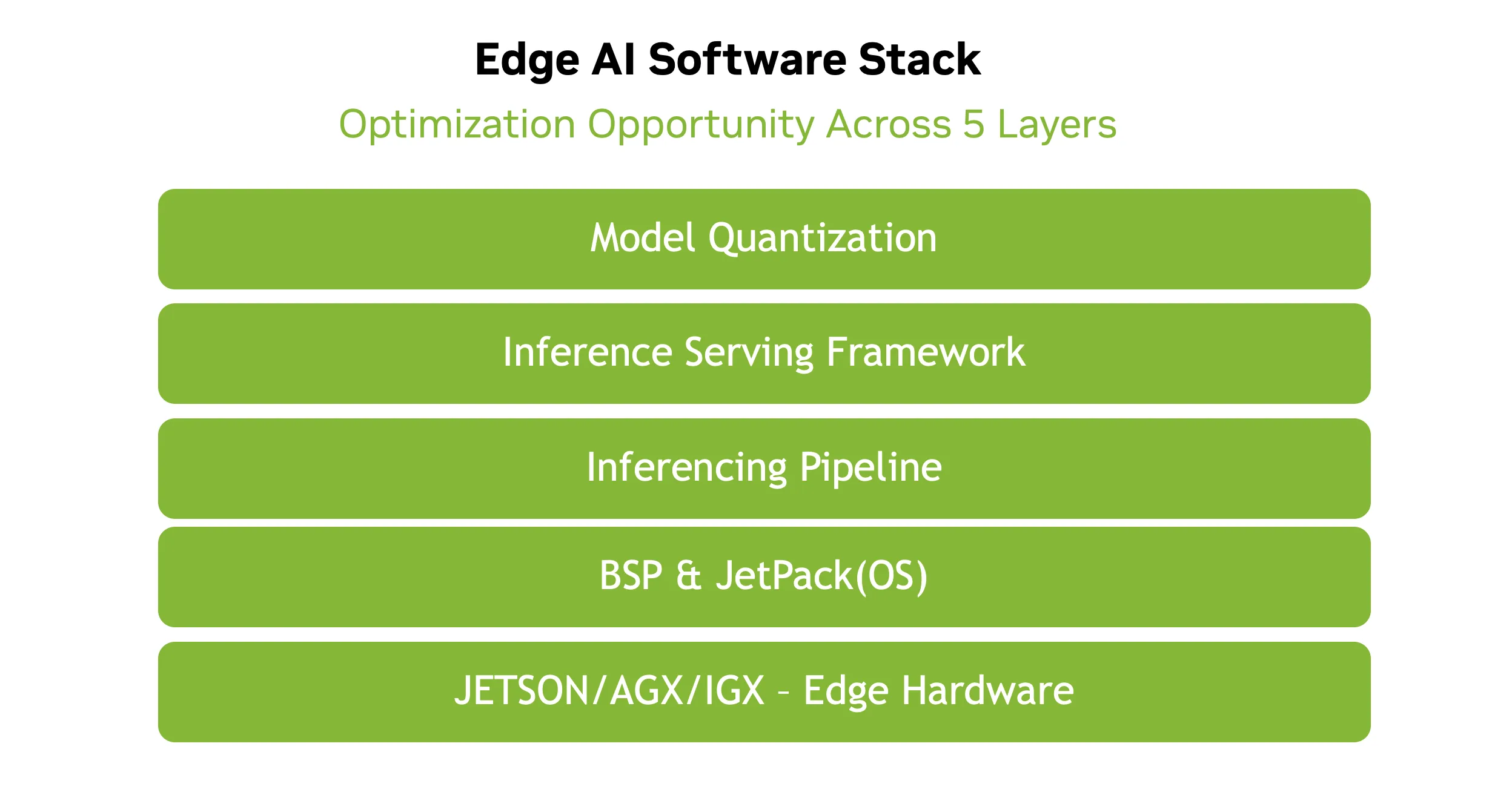
Capas fundamentales: Board Support Package y pila de software
La capa del NVIDIA Jetson Board Support Package (BSP) y NVIDIA JetPack forman la base de la pila de software, interactuando con el hardware. Incluye el kernel de Linux, controladores de dispositivos, firmware y el JetPack SDK con componentes que habilitan el cómputo, multimedia e I/O acelerado. Esta capa abstrae la complejidad del hardware —GPUs, CPUs, memoria y periféricos— proporcionando una base estable y optimizada para servicios y aplicaciones de nivel superior.
En esta capa, se pueden lograr ahorros de memoria desactivando servicios no utilizados y reclamando regiones de carveout reservadas. Estas optimizaciones reducen la sobrecarga y liberan DRAM para las cargas de trabajo de las aplicaciones sin afectar la funcionalidad principal. Las siguientes secciones destacan técnicas clave para habilitar estas optimizaciones.
Las pautas de optimización de la capa BSP y JetPack funcionan para Jetson Orin NX y Jetson Orin Nano.
Las regiones de carveout en NVIDIA Jetson Orin NX, junto con las optimizaciones del espacio de kernel y de usuario, son áreas clave para mejorar la eficiencia general del sistema. Las siguientes secciones exploran técnicas prácticas para optimizar estas capas.
Optimización de Carveout
Las regiones de carveout en NVIDIA Jetson Orin NX y NVIDIA Jetson Orin Nano son memoria física reservada apartada en el arranque para motores de hardware específicos, firmware y subsistemas de tiempo real. No son accesibles para Linux ni para las aplicaciones NVIDIA CUDA y son utilizadas por microcontroladores y aceleradores integrados en el chip. Estas actúan como pools de memoria dedicados para garantizar el aislamiento, la seguridad y el comportamiento determinista. Dependiendo de las necesidades de su pipeline y aplicación, algunos carveouts pueden desactivarse para optimizar aún más el uso de la memoria.
Nota 1: El siguiente ejemplo muestra cómo un usuario puede realizar una optimización de memoria cuando no se requiere pantalla. Agregue el fragmento de código dentro del nodo /misc/carveout/ de Linux_for_Tegra/bootloader/generic/BCT/tegra234-mb1-bct-misc-p3767-0000.dts
// Carveouts relacionados con la pantalla
aux_info@CARVEOUT_BPMP_DCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>; // 0MB
alignment = <0x0 0x0>; // 0MB
};
aux_info@CARVEOUT_DCE_TSEC {
pref_base = <0x0 0x0>;
size = <0x0 0x0>; // 0MB
alignment = <0x0 0x0>; // 0MB
};
aux_info@CARVEOUT_DCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>; // 0MB
alignment = <0x0 0x0>; // 0MB
};
aux_info@CARVEOUT_DISP_EARLY_BOOT_FB {
pref_base = <0x0 0x0>;
size = <0x0 0x0>; // 0MB
alignment = <0x0 0x0>; // 0MB
};
aux_info@CARVEOUT_TSEC_DCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>; // 0MB
alignment = <0x0 0x0>; // 0MB
};Actualice el contenido del nodo /mb2-misc/auxp_controls@3/ de Linux_for_Tegra/bootloader/tegra234-mb2-bct-common.dtsi a:
/* Campos de control para el cluster DCE. */
auxp_controls@3 {
enable_init = <0>;
enable_fw_load = <0>;
enable_unhalt = <0>;
reset_vector = <0x40000000>;
};Elimine los nodos completos /mb2-misc/auxp_ast_config@6 y /mb2-misc/auxp_ast_config@7 de Linux_for_Tegra/bootloader/tegra234-mb2-bct-common.dtsi
Use la herramienta dtc para descompilar el dtb del kernel a dts, marque el estado del nodo /display@13800000 como disabled, luego vuelva a compilar el dts a dtb del kernel:
display@13800000 {
status = "disabled";
};Nota 2: El siguiente ejemplo muestra cómo un usuario puede realizar una optimización de memoria cuando no se necesita una cámara. Agregue el fragmento de código dentro del nodo /misc/carveout/ de Linux_for_Tegra/bootloader/generic/BCT/tegra234-mb1-bct-misc-p3767-0000.dts:
aux_info@CARVEOUT_CAMERA_TASKLIST {
pref_base = <0x0 0x0>;
size = <0x0 0x0>; // 0MB
alignment = <0x0 0x0>; // 0MB
};Vía NVIDIA Developer.



