Las organizaciones grandes de datos y analítica suelen tener problemas para que el acceso a sus datos sea verdaderamente self-service. La industria intentó resolverlo durante décadas sin éxito, pero ahora la IA ofrece un camino creíble.
A escala de GitHub, dar soporte analítico dedicado a decenas de equipos de producto es difícil, y por eso muchos terminan resolviendo el problema por su cuenta. Aunque existe mucha telemetría de producto valiosa que ingeniería y producto pueden usar para decidir, definir qué modelo de datos, qué grano, qué filtro, escribir la consulta y validar el resultado siempre ha sido complejo sin el apoyo de un analista.
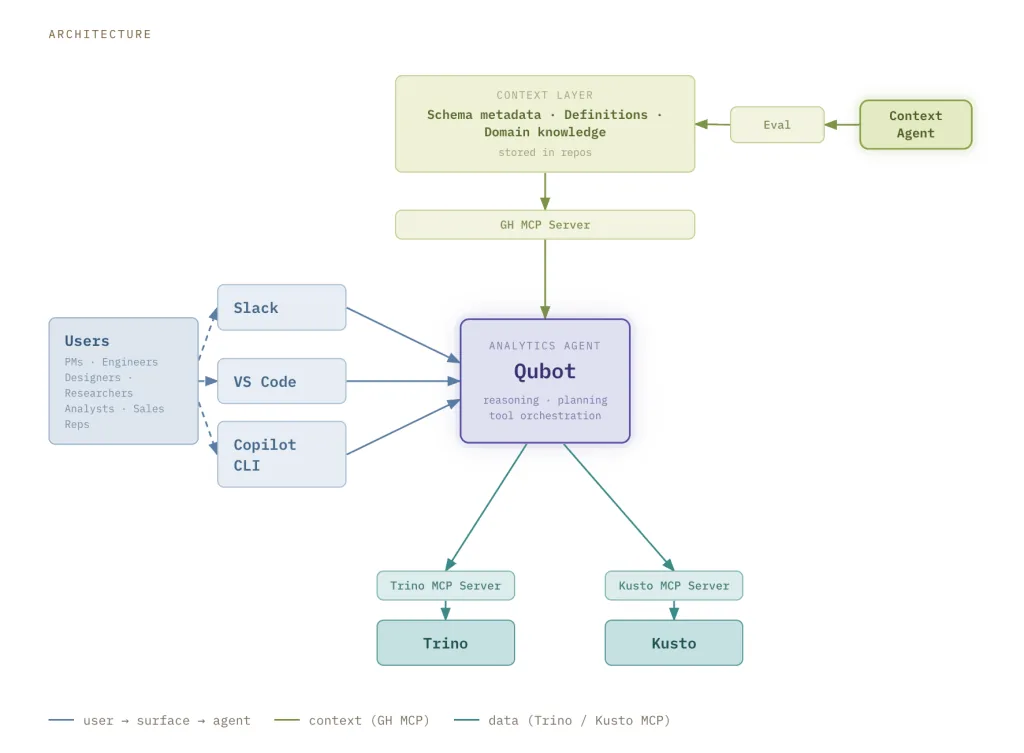
Acá entra Qubot, el agente analítico interno potenciado por GitHub Copilot. Permite a cualquier Hubber (así se llaman los empleados de GitHub) preguntar en lenguaje natural sobre cualquier modelo de datos del warehouse y obtener una respuesta en segundos.
Qubot no es una herramienta de reportería ni un reemplazo de dashboards. Está pensado para preguntas exploratorias del tipo "¿qué cohorte de usuarios tiene la mayor retención en esta feature?" o "¿qué producto contribuyó más a mover esta métrica la semana pasada?". El costo de mantenimiento es cero y ayuda a los equipos a ponerse al día con datasets que no conocen.
¿Cómo funciona Qubot por dentro?
La arquitectura tiene tres componentes principales: interfaz de usuario, capa de contexto y motor de consultas.
Interfaz de usuario
Qubot es accesible vía Slack, VS Code y la CLI de Copilot. La interfaz de Slack no requiere configuración y es la herramienta de colaboración preferida de los Hubbers. Cuando alguien publica una pregunta en el canal de Qubot, una instancia se levanta como Copilot Cloud Agent corriendo en github.com. La respuesta se entrega directo en Slack, lo que permite al usuario compartirla con otros y también iterar dentro del hilo para refinar la pregunta. Todos los resultados quedan además guardados como reporte markdown en un pull request que el usuario puede referenciar para afinar la consulta o usarla en un dashboard.
Qubot también está disponible en VS Code y en la CLI de Copilot para quienes prefieren una experiencia más integrada con su flujo. Se instala con un comando como plugin y queda disponible en cualquier sesión de agente junto a los demás agentes, skills y herramientas que tenga configurado el usuario.
Capa de contexto federada
El data warehouse contiene datos en distintos niveles de curación: eventos crudos (bronze), hechos y dimensiones conformados (silver), y datasets curados diseñados para casos de negocio específicos (gold). La capa de contexto está construida de manera federada, con conocimiento adaptado al tipo de dato.
- Para datos bronze: contexto de telemetría aportado por los equipos de producto, con información de esquema y metadatos.
- Para datos silver: ejemplos de consultas, guías de uso y filtros obligatorios, mantenidos por el equipo de datos y analítica.
- Para datos gold: reglas de negocio y definiciones de métricas aportadas por los equipos dueños de esos datasets.
GitHub también aprovecha sus pipelines de ETL para enriquecer sistemáticamente la capa de contexto con señales adicionales y metadata derivada. El contexto se carga en tiempo de ejecución vía el GitHub MCP Server, recuperándolo desde la capa de contexto.
Agente de contexto
La capa de contexto se enriquece constantemente con conocimiento nuevo persistido en múltiples repositorios. En GitHub se usa principalmente markdown para la documentación, así que no necesitan interfacear con varias herramientas distintas.
La contribución federada de contexto se simplificó mediante un agente de contexto. Los equipos pueden aportar vía una plantilla estandarizada o referenciando un repositorio con el contexto relevante. El agente ingesta, organiza y normaliza esa información en un formato estructurado que ha demostrado funcionar bien para Qubot según las evaluaciones internas.
Framework de evaluación
Cada cambio a la capa de contexto o a la configuración del agente pasa por una evaluación antes de salir. Cuando alguien quiere enriquecer la capa con conocimiento nuevo, abre un pull request. El contexto nuevo atraviesa un framework de eval offline que mide precisión de la respuesta, latencia en encontrar la respuesta correcta y atrapa regresiones antes de que lleguen a los usuarios.
El framework de benchmarking para evaluar Qubot a través de casos de prueba estructurados tiene tres componentes:
- Casos de prueba: dataset curado de prompts con respuestas correctas conocidas, SQL ground-truth y metadata (dominio, dificultad).
- Orquestación automatizada: un script que automatiza el lanzamiento de cada caso como agent task con la CLI
gh agent-task create, corre múltiples trials en paralelo, hace polling hasta completion y guarda resultados JSON detallados. - Agregación de estadísticas: un script de reporte que lee los resultados guardados y calcula métricas por caso de prueba: tasa de completion, accuracy y duración (avg/min/max).
El flujo end-to-end es: definir casos de prueba, correr Qubot N veces por caso, recolectar resultados, agregar estadísticas y comparar configuraciones.
Motor de consultas
Qubot se conecta tanto a Kusto como a Trino, los dos motores de consulta que sostienen la mayoría de las cargas analíticas de GitHub, vía un MCP server. Desarrollaron una implementación custom del Trino MCP server, mientras que para Kusto desplegaron una versión local del Fabric RTI MCP Server. Kusto es rápido y bien adaptado a preguntas exploratorias sobre datos de eventos recientes. Trino maneja joins complejos y análisis histórico más profundo.
En vez de obligar al usuario a saber cuál usar, Qubot por defecto va a Kusto y cambia a Trino automáticamente cuando la pregunta lo requiere.
Lo que cambió y lo que aprendieron
Qubot tuvo amplia adopción dentro de GitHub, con cientos de usuarios entusiastas corriendo miles de consultas. La cantidad de preguntas que los Hubbers hacen en los canales de Slack de datos y analítica bajó dramáticamente, porque ahora exploran los datos con más autonomía y solo contactan al equipo para preguntas complicadas.
¿Qué de esto sirve para equipos LatAm?
El patrón es replicable sin necesidad de Copilot Cloud. Un equipo chileno de tamaño medio que tenga su data en BigQuery, Snowflake o Postgres puede armar una versión liviana de Qubot con tres ingredientes: un cliente de LLM (Claude vía API ronda los USD 3 por millón de tokens de entrada, lo que para un equipo de 50 personas que hace 1.000 consultas/mes suele dejar el costo bajo CLP 80.000 mensuales), un MCP server custom contra el warehouse y un canal Slack como punto de entrada. El componente crítico que diferencia un agente útil de uno que alucina respuestas SQL no es el modelo, es la capa de contexto: documentar grano, filtros mandatorios y reglas de negocio en markdown versionado.
Para qué NO sirve
Qubot, según GitHub, no reemplaza dashboards ni reportería formal. Las respuestas exploratorias siguen necesitando validación humana antes de tomar decisiones operacionales. Y la calidad del agente depende directamente de la calidad del contexto: data warehouses sin documentación de esquemas o sin reglas de negocio escritas devolverán respuestas inconsistentes incluso con el mejor LLM detrás.



