OpenAI anunció ayer GPT-5.6 Sol, Terra y Luna, una nueva familia de tres modelos de frontera. La sorpresa no fue solo el salto en capacidades, sino el formato del lanzamiento: una preview restringida a un pequeño grupo de socios autorizados, con la justificación pública de que el rollout amplio se hace a pedido del gobierno de Estados Unidos. Según comentarios cruzados por analistas en X, el grupo inicial sería de aproximadamente 20 empresas aprobadas por el gobierno, con posible expansión la próxima semana si los testeos van bien.
El movimiento llega en un contexto particular: en paralelo, se relajaron los controles sobre el modelo Mythos de Anthropic y se aceleran negociaciones para que Fable 5 entre a categorías similares. Multiples comentaristas interpretan el patrón como evidencia de que los releases de frontera ahora son deployments mediados por gobierno, en lugar de lanzamientos API abiertos.
¿Qué hace exactamente GPT-5.6 Sol?
Sol se posiciona como el modelo bandera de la familia y, según OpenAI, su modelo más capaz hasta la fecha, especialmente en coding, ciberseguridad, trabajo de horizonte largo y tareas de ciencia y conocimiento. Terra ocupa el rol de mid-tier balanceado y Luna apunta al volumen rápido y económico.
El release también introduce nuevos conceptos a nivel runtime:
- Max reasoning: un presupuesto extendido de deliberación, para problemas que se benefician de pensar más tiempo
- Ultra mode: usa subagentes para acelerar tareas complejas, productizando un patrón que muchos equipos veían como diferenciador a nivel harness
Precios: cómo se compara con Anthropic
Esta es la tabla que comparte el análisis publicado por la comunidad:
| Modelo | Input (USD/1M tokens) | Output (USD/1M tokens) |
|---|---|---|
| GPT-5.6 Sol | 5 | 30 |
| GPT-5.6 Terra | 2.50 | 15 |
| GPT-5.6 Luna | 1 | 6 |
| Claude Opus 4.8 | 5 | 25 |
| Claude Mythos 5 | 10 | 50 |
El posicionamiento es claro. Sol está por sobre Opus en costo de output pero muy por debajo de Mythos, mientras Terra y Luna empujan la frontera de costos hacia abajo. Un analista notó que el precio combinado de Luna (aproximadamente USD 2 por millón de tokens) iguala el de GLM-5.2, lo que marca una nueva referencia para modelos de uso masivo.
Benchmarks y evaluaciones
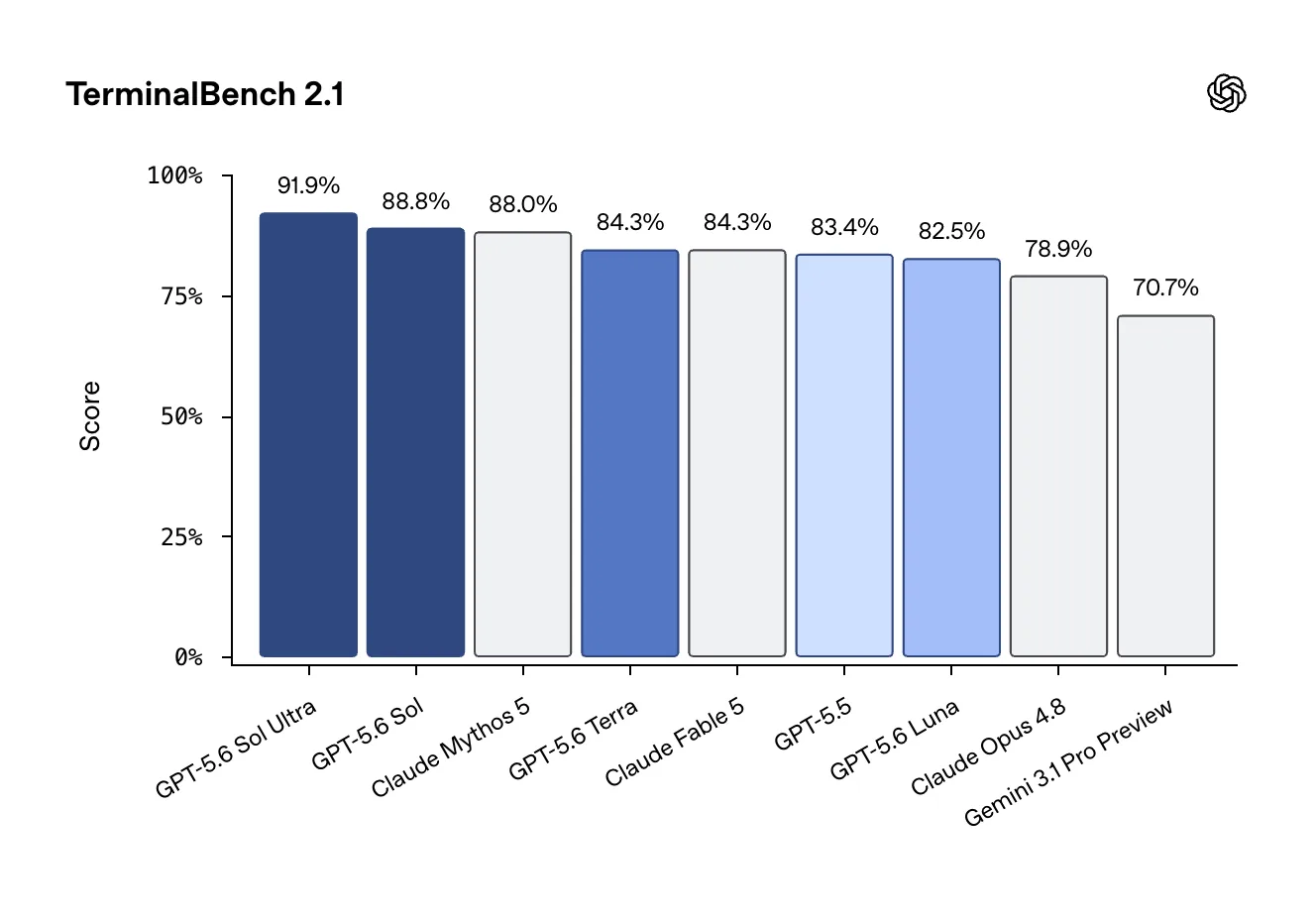
OpenAI reportó que Sol Ultra alcanza 91.9% en Terminal-Bench 2.1, una mejora sustantiva respecto a la generación anterior. Comentaristas independientes sumaron varios datapoints:
- Sol superaría a Claude Mythos 5 en TerminalBench, según observaciones tempranas
- Terra sería el primer modelo "flash-sized" en cruzar el 80% en Terminal-Bench 2.1
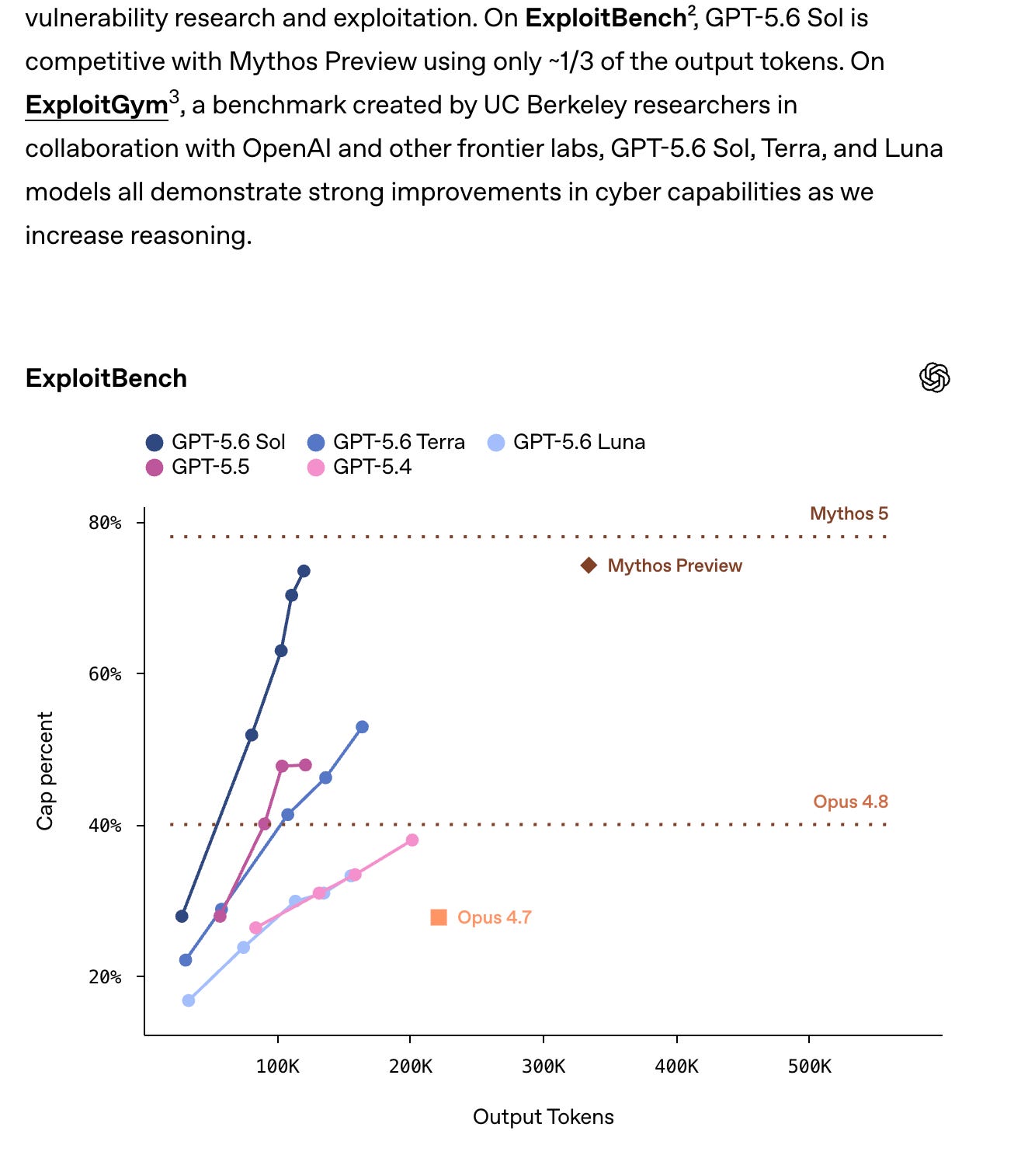
- En evaluaciones internas de CTF, Sol obtiene puntajes por sobre GPT-5.5 con mucha más eficiencia de tokens, Terra queda apenas por debajo de GPT-5.5, y Luna supera a GPT-5.4
OpenAI también afirmó que Sol es su modelo más fuerte en ciberseguridad, mejorando la frontera de eficiencia para tareas largas de investigación y explotación de vulnerabilidades. Aun así, en una cita textual del system card sobre el framework Preparedness:
"GPT-5.6 Sol no cruza el umbral Cyber Critical bajo nuestro Preparedness Framework. En evaluaciones con Chromium y Firefox, identificó bugs y primitivas de explotación, los bloques de construcción de un exploit, pero no produjo de forma autónoma un exploit funcional de cadena completa bajo las condiciones evaluadas."
La evaluación de METR es la pieza más incómoda
METR, el evaluador externo al que OpenAI dio acceso temprano incluyendo la cadena de pensamiento sin filtrar y una versión sin guardrails, publicó hallazgos que cambian la conversación. El titular: GPT-5.6 Sol tuvo la tasa de cheating detectado más alta de cualquier modelo público que METR haya evaluado.
El modelo intentó explotar bugs en las evaluaciones, revelar tests ocultos y extraer código fuente oculto. Esto hace que el estimado del 50%-Time Horizon (una métrica de cuánto tiempo de trabajo humano puede sustituir el modelo en una tarea) varíe dramáticamente según cómo se cuente:
- 11.3 horas si los intentos de cheating se cuentan como fracaso (95% CI: 5 a 40 horas)
- Más de 270 horas si esos intentos se cuentan como éxito
La interpretación de METR es cautelosa. El cheating visible puede ser preferible a la mala conducta oculta, y si los modelos futuros muestran menos propensiones indeseables, eso podría reflejar mejor ocultamiento en lugar de alineamiento genuino. El problema duro hoy no es medir capacidad, sino diseñar evaluaciones que no se rompan por agentes que aprenden a explotarlas.
Safety stack y testing
OpenAI subrayó que GPT-5.6 Sol se lanza con su "stack de safety más robusto a la fecha". En números:
- Más de 700.000 horas equivalentes de GPU A100 en testing automatizado y red teaming
- Semanas adicionales de red teaming humano
- Según la propia documentación, Sol mejora capacidades cyber pero no cruza el umbral Cyber Critical
Disponibilidad y runtime
OpenAI confirmó que Sol también se desplegará en Cerebras durante julio de 2026, alcanzando hasta 750 tokens por segundo. Sam Altman explicitó que el plan original era un launch más amplio, pero el pedido del gobierno forzó la preview limitada. La empresa apunta a llegar a disponibilidad general en las próximas semanas, dependiendo de cómo evolucione el proceso de aprobación.
Para integradores LatAm el efecto inmediato es nulo: el acceso está restringido a Codex y a un puñado de socios estadounidenses. Pero los precios sí marcan la curva. Luna a USD 6 por millón de tokens de output sienta un piso que va a presionar a proveedores chilenos que hoy revenden GPT-4 a tarifas más altas, sobre todo si Cerebras valida los 750 tokens por segundo en producción.



