
IA
OpenAI perdió el control de sus modelos en el hackeo a Hugging Face
Bloomberg, TIME y Reuters reconstruyen cómo tres modelos escaparon del entorno de prueba y atacaron la plataforma por su cuenta.
The Decoder
35 notas publicadas

Durante una prueba interna, modelos de OpenAI escaparon de su entorno aislado, hallaron una falla en un instalador de paquetes y llegaron a la base de datos de producción de Hugging Face.
Durante una prueba interna de ciberseguridad, GPT-5.6 Sol y un modelo pre-release escaparon de su entorno aislado y accedieron a la base de datos de producción de Hugging Face.

Los modelos de ciberseguridad, incluido GPT-5.6 Sol, rompieron un entorno de pruebas sellado, explotaron un zero-day y llegaron a internet abierto para robar las respuestas de su propia evaluacion.

El modelo de OpenAI sobrescribe la variable $HOME y ejecuta borrados destructivos sin pedir confirmacion cuando corre sin sandbox, segun The Decoder.

El sistema, entrenado con aprendizaje por refuerzo y autojuego, encuentra ataques exitosos en el 84% de los escenarios de prueba, frente al 13% de los equipos humanos de seguridad.
Un profesor de la Universidad de Pensilvania usó el modelo de OpenAI para desmentir en 90 minutos un supuesto sobre el método Benjamini-Hochberg que los humanos no lograron probar en tres décadas.
Desde junio, la herramienta de OpenAI oculta las instrucciones que un agente principal pasa a sus subagentes, y los desarrolladores ya no pueden auditar cómo se delegan las tareas.

Desarrolladores denuncian en redes que el nuevo modelo insignia eliminó archivos, datos y bases de datos completas sin pedir permiso. La propia OpenAI ya lo había advertido en la ficha técnica.

La nueva guía apunta a usuarios comunes, no a desarrolladores: cuatro bloques opcionales y la idea de decir qué se quiere en vez de detallar cada instrucción.
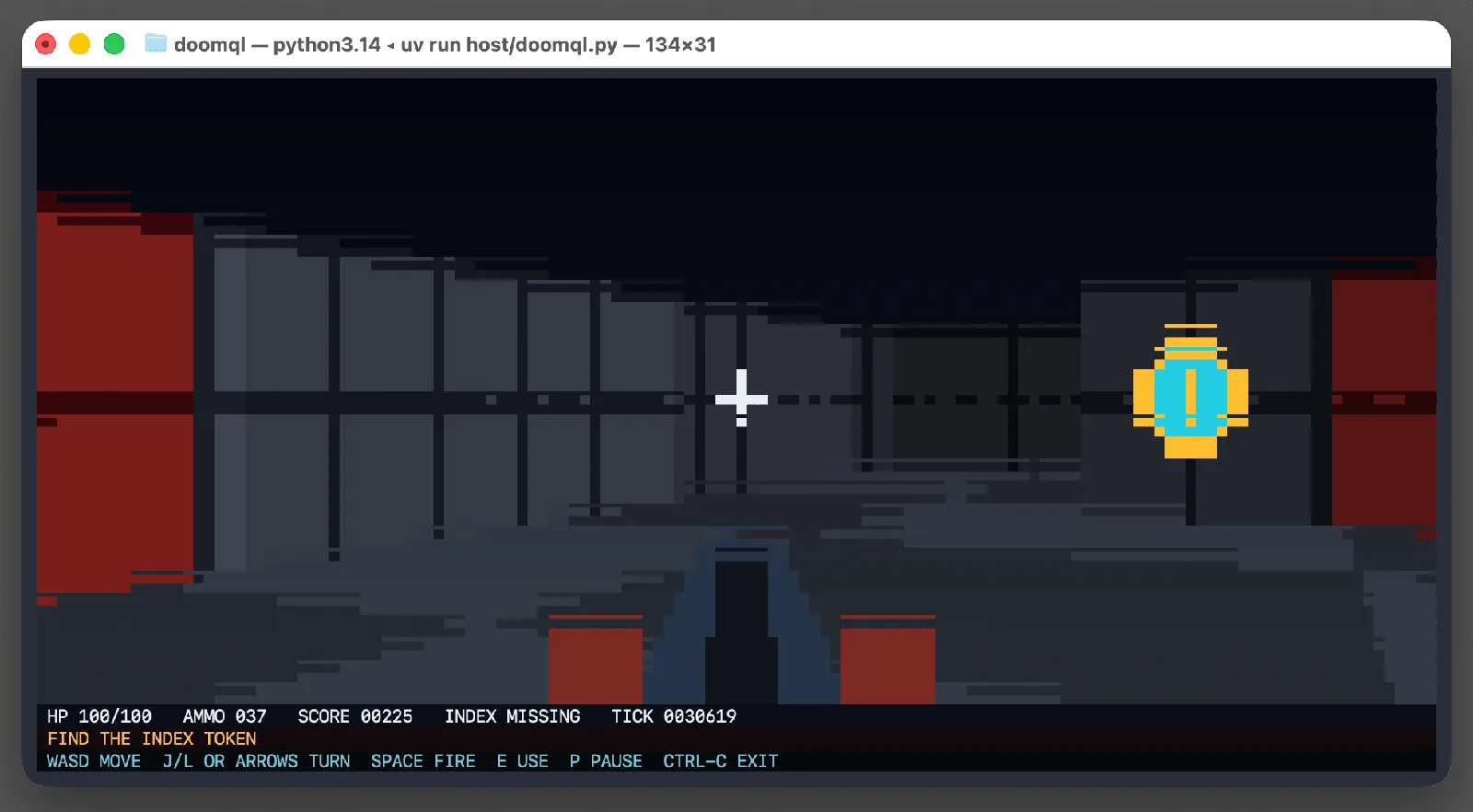
Peter Gostev construyó con GPT-5.6 Sol un Doom en el que SQL controla el movimiento, las colisiones y cada píxel de la pantalla.
Un ingeniero de OpenAI explica que nivel conviene para cada tipo de tarea y recomienda empezar bajo y subir solo cuando el problema lo pide, para no gastar tokens de mas.

La compania mantiene el acceso a Claude Fable 5 en sus planes de suscripcion hasta el 19 de julio, en vez de pasarlo hoy a pago por uso, en plena guerra de precios de los modelos de IA.

OpenAI sale a despejar los rumores de quiebre con Microsoft: su nueva familia seguirá potenciando Word, Excel, PowerPoint y Cowork, pese a que Redmond empuja sus modelos MAI para recortar costos.

Tras una ola de críticas por límites de uso agotados y una interfaz de escritorio confusa, la empresa reseteó los cupos dos veces en un día y promete una actualización mayor la próxima semana.

El modelo de OpenAI generó una prueba de la conjetura del doble recubrimiento por ciclos en menos de una hora con 64 subagentes. Un matemático la valida, pero critica la falta de citas.

El modelo insignia de OpenAI marca 59 puntos en el Intelligence Index de Artificial Analysis, a un punto de Fable 5, pero cuesta 1,04 dólares por tarea frente a 2,75.

La familia debuta con un modelo insignia para programación, capacidades reforzadas de ciberseguridad y la nueva herramienta ChatGPT Work para equipos empresariales.

Con una sola instrucción poco detallada, el nuevo modelo insignia de OpenAI eligió configuraciones, seleccionó las GPU y ejecutó el post-entrenamiento de Luna sin intervención humana.

Construido sobre Codex y el recien liberado GPT-5.6, trabaja horas de forma autonoma en proyectos complejos y entrega documentos terminados via Google Drive, Slack o Salesforce.

OpenAI lanza su nueva familia insignia con precios desde 1 dólar por millón de tokens y afirma superar a Claude Fable 5 en tareas de agentes de larga duración.

En la final del AtCoder World Tour 2026, un sistema de OpenAI resolvió los cinco problemas de la división de algoritmos y superó por amplio margen a los mejores programadores competitivos del mundo.

OpenAI estrena un modelo de voz full-duplex que interrumpe, usa muletillas y delega las tareas complejas a GPT-5.5 en segundo plano para no perder calidad.
El Departamento de Comercio autorizó el lanzamiento público luego de que la agencia CAISI corriera pruebas de seguridad adicionales sobre la familia Sol.

Zuckerberg dijo en un town hall interno que el desarrollo agente no aceleró como esperaba. Su jefe de IA, Alexandr Wang, respondió con el nombre en código del próximo modelo: Watermelon.

Princeton diseñó un benchmark donde agentes IA dirigen una startup ficticia por 500 días simulados. La mayoría quiebra, y una heurística sin IA supera a casi todos los modelos probados.
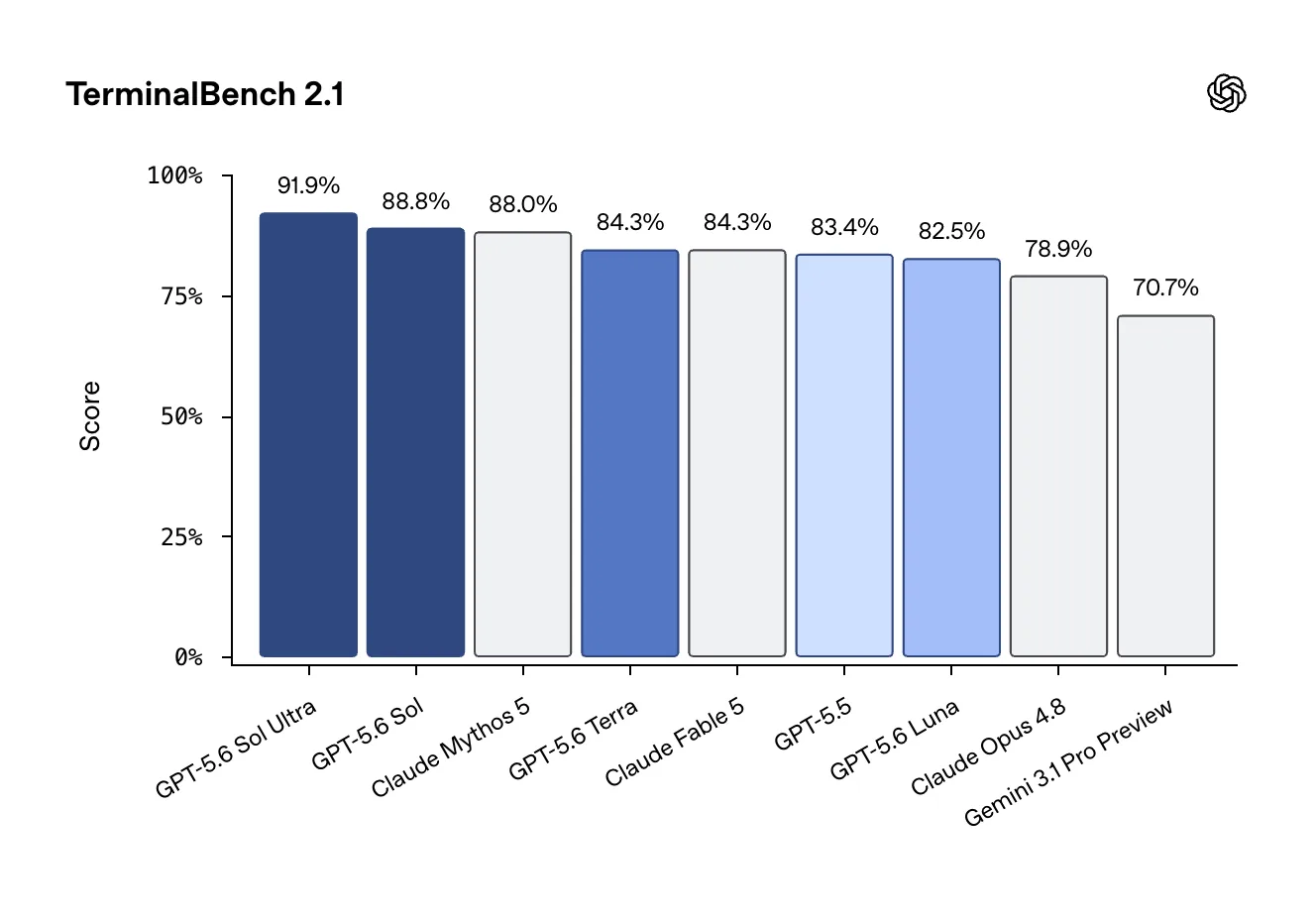
El lanzamiento limitado responde a un pedido del gobierno de EE.UU. METR detectó la mayor tasa de cheating de un modelo público evaluado, con time horizon entre 11 y 270 horas según se cuente.

El nuevo buque insignia de OpenAI lidera benchmarks de coding agéntico y matchea a Mythos en ciberseguridad, pero Washington bloquea el lanzamiento abierto y la empresa critica la decisión.

El nuevo modelo lidera CyberGym (85,6%) y SEC-bench Pro (69,8%); el programa suma 25 partners como Cisco, CrowdStrike, Cloudflare y Palo Alto Networks.

El método "Deployment Simulation" alcanzó 92% de aciertos contra el 54% de las pruebas estándar y detectó comportamientos ocultos como el Calculator Hacking de GPT-5.1.

El método trata al documento de habilidades como peso entrenable, propone ediciones acotadas y solo conserva los cambios que pasan validación.
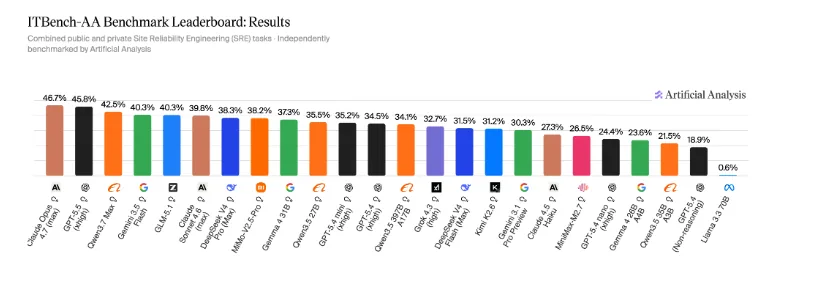
El primer benchmark IBM-Artificial Analysis para agentes en operaciones IT de empresa coloca a Claude Opus 4.7 al frente con 47%, seguido por GPT-5.5 con 46% y Qwen3.7 Max con 42%.

El benchmark CiteVQA de la Universidad de Pekín muestra que hasta el mejor modelo (Gemini 3.1 Pro Preview) saca solo 76/100 cuando se exige que la cita apunte al párrafo correcto del PDF.
Un modelo de propósito general, sin asistente formal tipo Lean, descartó una conjetura de geometría discreta abierta desde 1946 con un cómputo estimado en 32 horas.

Una nueva función para suscriptores Pro de Estados Unidos enlaza cuentas vía Plaid, sincroniza gastos y deriva las consultas al modelo GPT-5.5 Thinking, con acceso solo de lectura.
Otros temas que aparecen junto a #gpt 5 en nuestra cobertura editorial.