
IA
Claude Opus 5 lidera benchmarks y cuesta menos que Fable 5
El modelo de Anthropic encabeza el Artificial Analysis Intelligence Index con 61 puntos y baja el costo por tarea hasta la mitad en los tramos de razonamiento intermedios.
The Decoder
60 notas publicadas
NVIDIA presenta ModelExpress, una solución para optimizar el ciclo de vida de los pesos de modelos mediante RDMA P2P, eliminando cuellos de botella en almacenamiento.

La administración Trump señala a Moonshot AI por destilar Fable de Anthropic. Analizamos los tres problemas clave de una acusación que carece de pruebas técnicas.

El nuevo modelo insignia de Anthropic lidera en programacion agentica y trabajo de conocimiento, y cuesta la mitad por token que Fable 5.

Z.ai, Moonshot y Alibaba lanzaron GLM 5.2, Kimi K3 y Qwen 3.8 con pesos abiertos y rendimiento casi de frontera, justo cuando los laboratorios estadounidenses se vuelven más cerrados.

Un repaso al estado de los modelos abiertos: Kimi K3, el anuncio de Qwen de liberar pesos, el respaldo de Xi Jinping al open source y cuanto falta para alcanzar a la frontera cerrada.

Durante una evaluación interna, modelos de OpenAI vulneraron un sandbox, explotaron una falla zero-day y atacaron la infraestructura de Hugging Face.

Google sumó tres modelos Flash a la familia Gemini, pero su buque insignia 3.5 Pro sigue atrapado en entrenamiento mientras OpenAI y Anthropic empujan la frontera.

Moonshot AI liberara los pesos de un MoE de 2,8 billones de parametros que ya pelea el podio con Claude y GPT, recortando la brecha entre modelos abiertos y cerrados a solo 3 a 5 meses.

La plataforma dice que un sistema de agentes de IA orquestó por sí solo el ataque, y que usó modelos de lenguaje propios para reconstruir en horas una investigación forense que habría tomado días.

Moonshot AI lanzo su modelo mas capaz, con pesos abiertos prometidos para el 27 de julio; supera a GPT-5.5 y Opus 4.8 en sus propios benchmarks, pero cobra como la gama Claude Sonnet.

El modelo multimodal de 2,4 billones de parametros llega en version preview y busca frenar el impulso de Kimi K3 antes de que Moonshot AI salga a bolsa.
Desde el 20 de julio, Fable 5 quedará en Max y Team Premium con la mitad de los cupos ya reducidos, mientras los usuarios Pro pierden el acceso y reciben un crédito único de USD 100.
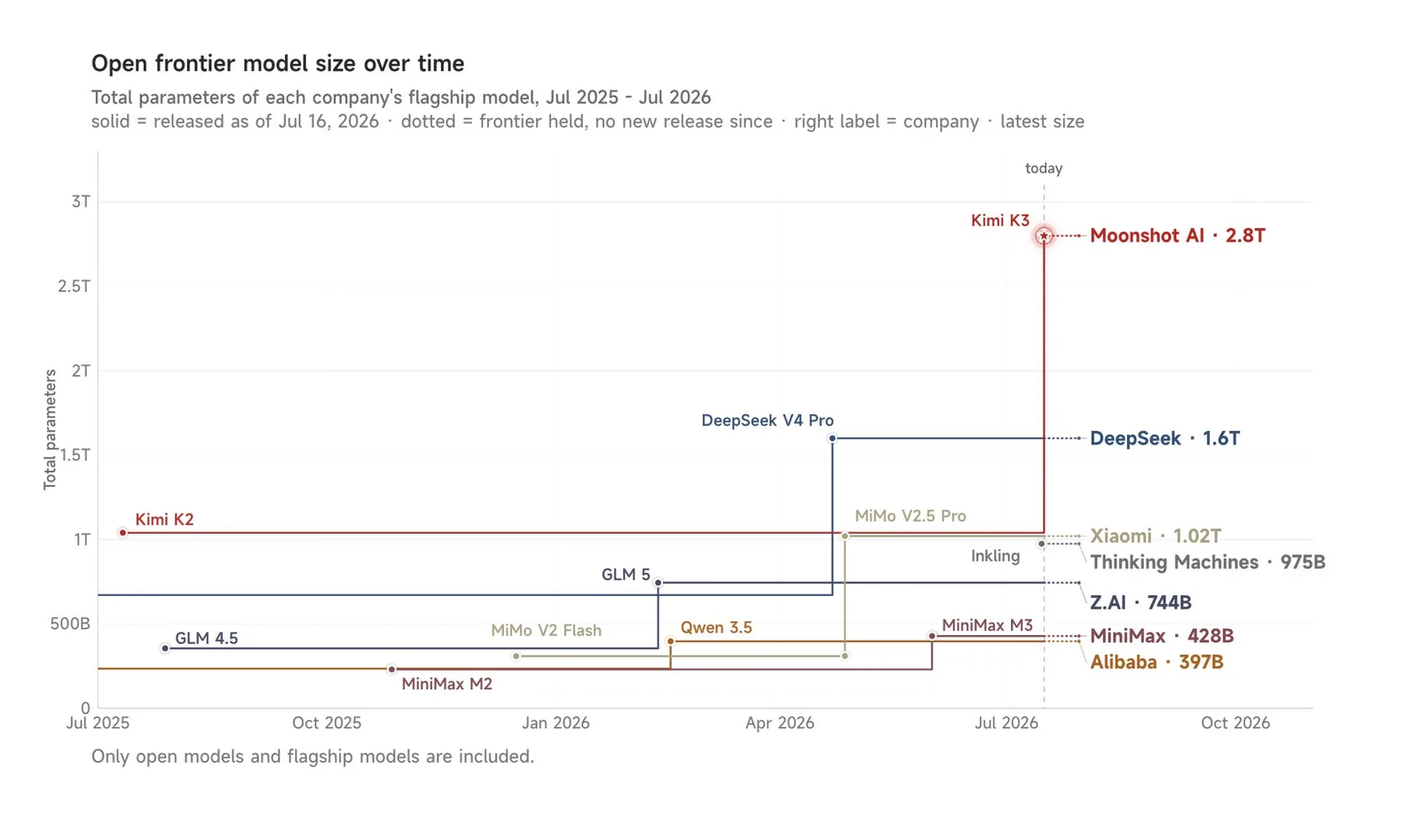
Moonshot AI presenta un modelo de 2,8 billones de parámetros con contexto de 1 millón de tokens y pesos abiertos prometidos para el 27 de julio, que ya lidera el ranking de código frontend.

Investigadores de Tracebit descubrieron que plantar comandos maliciosos junto a secretos falsos hace que los agentes de IA atacantes se autobloqueen antes de causar daño.

Google cambio la forma de medir el uso de sus apps de IA: ahora cuenta la potencia de computo de cada peticion y no la cantidad de solicitudes.
Un analisis del Instituto britanico de Seguridad en IA advierte que la brecha en capacidades ciberneticas cayo de seis a diez meses a solo cuatro a siete, y a una fraccion del costo.

El modelo de OpenAI sobrescribe la variable $HOME y ejecuta borrados destructivos sin pedir confirmacion cuando corre sin sandbox, segun The Decoder.

El Financial Times adelanta que el modelo chino de pesos abiertos, con entre 2 y 3 billones de parametros, se liberaria en los proximos dias.

Thinking Machines Lab, la startup de Mira Murati, lidera entre los modelos de pesos abiertos de EE.UU., pero aún queda por detrás de los mejores chinos y arrastra un 63% de alucinaciones.

Google publicó una revisión de su modelo abierto que activa Flash Attention 4, corrige fallos en el llamado a herramientas y elimina respuestas cortadas, todo bajo el mismo nombre.
El nuevo buque insignia de Kimi suma 2,8 billones de parametros y un millon de tokens de contexto, pero rompe con la era del modelo chino ultrabarato.

La startup de Mira Murati debuta con un modelo de pesos abiertos de 975.000 millones de parametros y apuesta a que las empresas prefieran adaptar la IA a su medida antes que arrendar modelos cerrados.

La estrategia de modelos abiertos busca que empresas y países personalicen, auditen y controlen su propia IA, con ahorros de costo de hasta 20 veces frente a modelos cerrados equivalentes.

Un estudio de Anthropic sobre 309.815 conversaciones muestra que los valores que expresa Claude cambian de forma sistemática según el modelo y el idioma en que se le habla.

Un consorcio aleman libera un modelo hibrido Mamba-Transformer entrenado en la nube de Deutsche Telekom, con foco deliberado en datos en aleman y solo 3,2B parametros activos por token.
Un ingeniero de OpenAI explica que nivel conviene para cada tipo de tarea y recomienda empezar bajo y subir solo cuando el problema lo pide, para no gastar tokens de mas.

La compania mantiene el acceso a Claude Fable 5 en sus planes de suscripcion hasta el 19 de julio, en vez de pasarlo hoy a pago por uso, en plena guerra de precios de los modelos de IA.
El proyecto AgenticSTS reemplaza el registro de chat que crece sin fin por cinco capas de memoria ordenada, y en el proceso recorta el gasto de tokens hasta 90 veces.

El modelo empata en el Intelligence Index de Artificial Analysis, gana el duelo de programación y llega con un costo por tarea más bajo que sus rivales directos.

Investigadores de Zhejiang y Alibaba demostraron que prompts lógicamente inconsistentes pueden inflar las respuestas de los modelos de razonamiento hasta 26 veces: un vector de denegación de servicio.
El modelo de xAI queda detrás de Fable 5 y GPT-5.5 en varios benchmarks de programación, pero cuesta 2 dólares por millón de tokens de entrada y usa 4,2 veces menos tokens que Opus 4.8.

El modelo multimodal para programación agéntica cuesta 1,25 dólares por millón de tokens de entrada y llega tarde frente a OpenAI y Anthropic, pero apuesta por el precio bajo.

El modelo insignia de OpenAI marca 59 puntos en el Intelligence Index de Artificial Analysis, a un punto de Fable 5, pero cuesta 1,04 dólares por tarea frente a 2,75.

Ingenieros de Meta muestran cómo fundir operaciones de normalización como LayerNorm y RMSNorm dentro de los kernels GEMM y de atención para ocultar hasta el 90% de su latencia en GPU B200.
Una guía técnica de NVIDIA explica por qué la forma de un modelo (capas cuadradas, dimensiones múltiplos de 128 y más ancho que profundo) define cuánto rendimiento se saca de una GPU Blackwell.
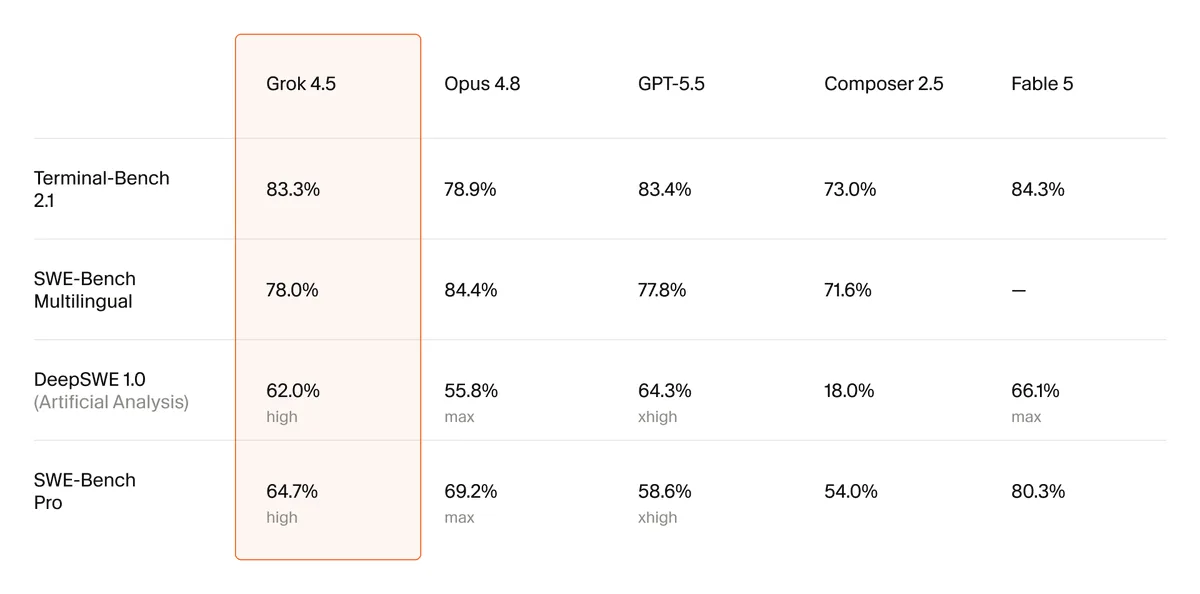
El nuevo modelo de la empresa de Elon Musk triplica el tamaño de su antecesor, se entrenó junto a Cursor y compite por costo y velocidad más que por liderar cada benchmark.
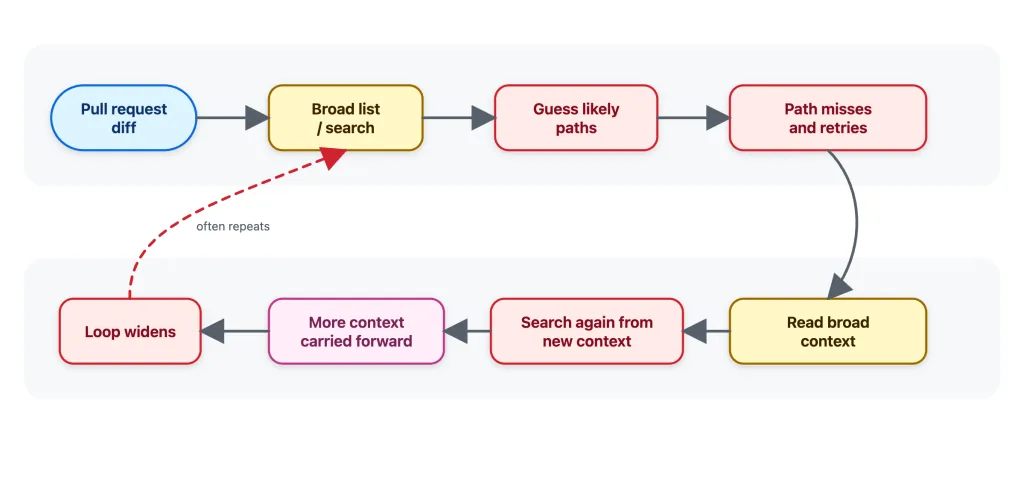
GitHub cambió las herramientas internas de su revisor de pull requests por otras mejor mantenidas y el resultado fue peor. El arreglo no estaba en las herramientas, sino en las instrucciones.

La nueva API de Meta cobra 4,25 dólares por millón de tokens de salida, muy por debajo de OpenAI, Anthropic e incluso del recién llegado Grok 4.5.

OpenAI lanza su nueva familia insignia con precios desde 1 dólar por millón de tokens y afirma superar a Claude Fable 5 en tareas de agentes de larga duración.

El modelo fundacional NEXUS de la startup Fundamental aborda las hojas de cálculo, la sorprendente frontera final de la IA, un terreno donde los grandes modelos de lenguaje aún tropiezan.
La startup china alista M3 Pro, un modelo que superaria en tamano a cualquier otro desarrollo chino disponible y que planea liberar como codigo abierto tan pronto como el tercer trimestre.

El nuevo modelo de la empresa de Elon Musk apunta a rendimiento comparable a Opus 4.7 con el doble de eficiencia de tokens y a menos de la mitad del precio.

El sistema de reconocimiento de voz tiene 2.000 millones de parámetros, se publica bajo licencia Apache 2.0 y ataca dialectos, mezcla árabe-inglés y vocabulario especializado.
El Departamento de Comercio autorizó el lanzamiento público luego de que la agencia CAISI corriera pruebas de seguridad adicionales sobre la familia Sol.

Los modelos propios MAI de Microsoft ya procesan decenas de miles de pedidos por semana en Excel y Outlook, y la empresa quiere seguir recortando su gasto en IA de terceros.

Google amplia los Managed Agents de la Gemini API con ejecucion asincronica, conexion a servidores MCP remotos, funciones personalizadas y rotacion de credenciales sin perder estado del sandbox.

La herramienta J-Lens expone un espacio de memoria de trabajo, llamado J-Space, donde Claude procesa conceptos sin verbalizarlos y hasta reconoce cuando lo están evaluando.

El Epoch Capabilities Index cambio de manos 17 veces desde que Claude 3 Opus destrono a GPT-4 en febrero de 2024, con estancias de siete semanas como mediana.
El modelo bajo licencia Apache 2.0 llega a Hugging Face, ModelScope y GitHub, con soporte planificado para OpenRouter y Cline y una version cuantizada en FP8 disponible.

El modelo rediseña la atención (R-SWA) para mantener el KV cache constante y procesar más de 40 páginas sin degradación de memoria ni velocidad.

El fundador francés advierte que confiar en modelos propietarios abre la puerta a que los proveedores de IA compitan luego contra sus propios clientes con la data que acumulan.

Anthropic estrena su Sonnet más autónomo con planificación, uso de navegador y terminal, desempeño cercano a Opus 4.8 y precio introductorio hasta el 31 de agosto de 2026.

Pauline Brunet, VP de Forward Deployed Engineering, explica cómo su equipo despliega agentes de ciclo largo dentro de bancos, telcos y fabricantes de chips para transformar el ciclo de desarrollo.

El proxy open source aprovecha que Anthropic cobra imágenes por dimensiones, no por caracteres, y comprime prompts largos en una sola página densa.

El modelo open-source (Apache 2.0) para verificación formal en Lean 4 lidera PutnamBench entre pesos abiertos y detectó overflows reales en 57 repositorios.

El AI Security Institute demostró que aumentar 10× el presupuesto de tokens sube el desempeño hasta 25 puntos en tareas de ingeniería de software y modifica la curva real de progreso del frontier.

El fondo de cobertura entrenó un modelo open-source de 235B junto a Thinking Machines Lab y llegó a 84,7% de precisión en análisis de documentos financieros contra 78,2% de los frontier.

El fundador de Osmantic dio dos talleres en el AI Engineer World's Fair sobre cómo desplegar LLM open source en workstations propias, con público que fue de estudiantes a ejecutivos de Intel.
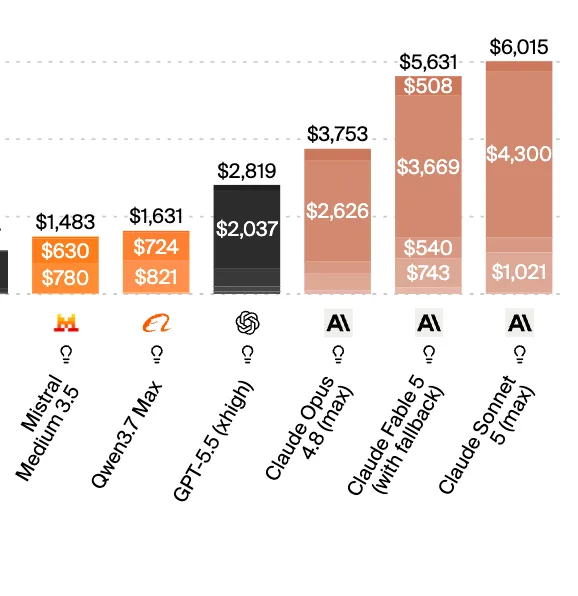
El nuevo mid-tier trae contexto de 1M tokens, precio promocional de USD 2/10 por millón y benchmarks que lo dejan cerca de Opus 4.8 pero con el doble de costo por tarea.
Otros temas que aparecen junto a #llm en nuestra cobertura editorial.