Evalúa modelos ASR clínicos más rápido con NVIDIA Nemotron Speech
- La IA de voz clínica enfrenta desafíos únicos con terminología compleja y poco común, lo que hace que los sistemas estándar sean inadecuados para tareas como el reconocimiento de nombres de medicamentos; la generación de datos sintéticos puede ayudar, pero solo si la pronunciación se valida cuidadosamente.
- El flujo de trabajo descrito aprovecha los NVIDIA agent skills, NeMo Data Designer y Magpie TTS Multilingual para crear, revisar y evaluar audio sintético consciente de la pronunciación, permitiendo la creación rápida y repetible de datasets de evaluación ASR clínica sin usar datos reales de pacientes.
- El proceso utiliza un bucle de mejora iterativo: definir perfiles clínicos, generar y revisar audio sintético para una pronunciación precisa, evaluar el rendimiento ASR a nivel de entidad y adaptar o expandir el benchmark basado en análisis de errores dirigidos, con revisión manual explícita para brechas de pronunciación.
El contenido generado por IA puede resumir información de manera incompleta. Verifique la información importante. Más información
Entrenar un modelo de IA de voz para reconocer o sintetizar correctamente terminología clínica es sorprendentemente difícil. Nombres de medicamentos como Acetaminofén, Amlodipino, Cefazolina y Biktarvy no forman parte del vocabulario cotidiano. Los nombres de procedimientos, términos anatómicos y diagnósticos específicos de cada especialidad introducen el mismo problema bajo una forma distinta. Los sistemas de voz comerciales pueden sonar fluidos y aun así omitir las palabras críticas para un flujo de trabajo clínico.
La generación de datos sintéticos (SDG) puede ayudar a cerrar esta brecha, pero solo si el habla sintetizada es fonéticamente precisa. Un sistema de texto a voz (TTS) que pronuncia mal un medicamento o un nombre de procedimiento produce datos de entrenamiento o evaluación que enseñan la pronunciación incorrecta. En lugar de solucionar el problema original, puede hacer que el fallo sea más difícil de detectar. Cuando se implementa correctamente, la SDG permite a un equipo establecer un benchmark de dominio en horas sin recolectar audio clínico real ni esperar por pipelines de anotación o aprobaciones de comités de ética (IRB).
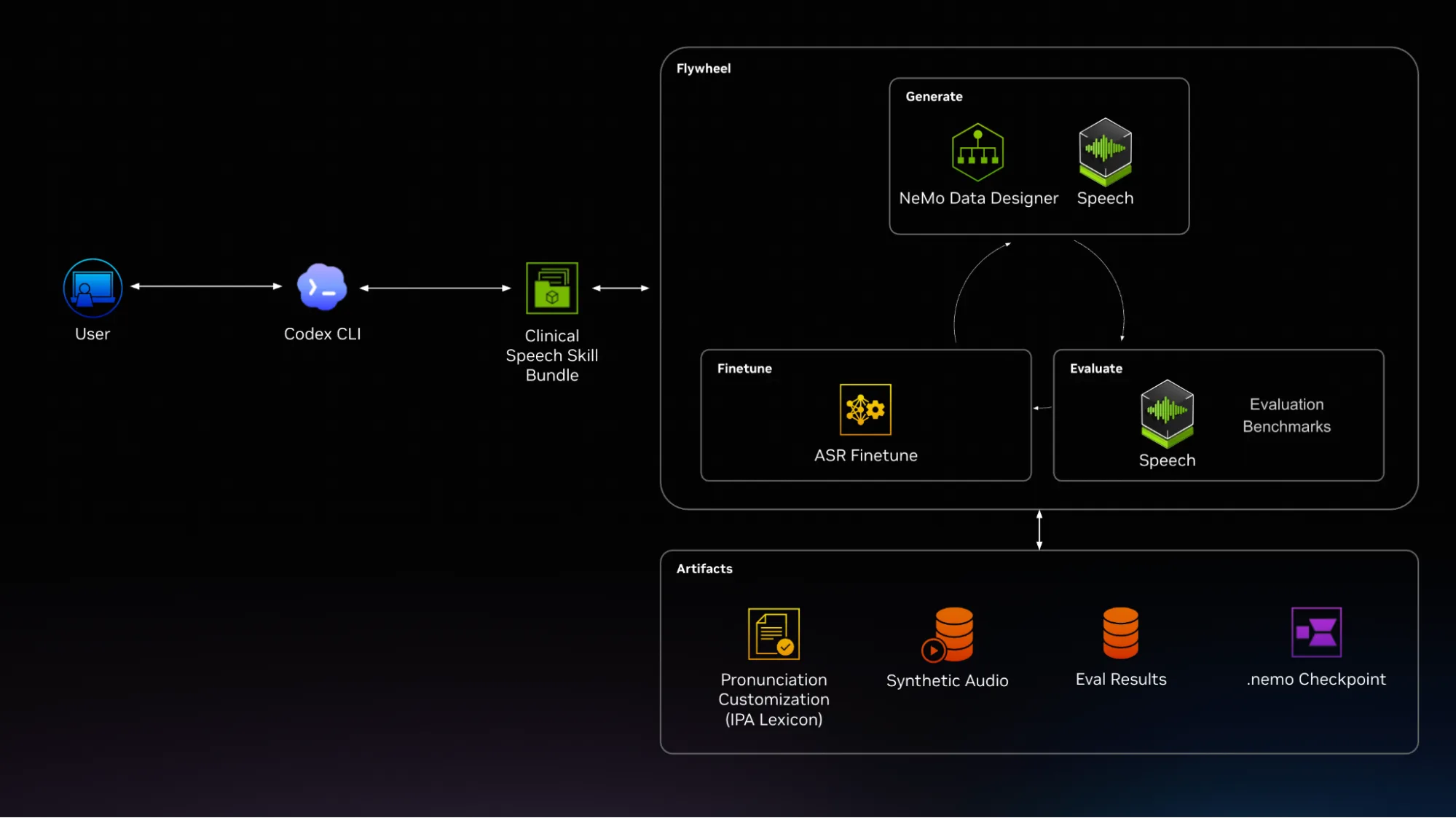
Esta publicación presenta un flujo de trabajo de reconocimiento automático de voz (ASR) clínico para generar audio sintético consciente de la pronunciación, revisar términos clínicos y evaluar la calidad del reconocimiento. Los NVIDIA agent skills guían el flujo de trabajo, mientras que NVIDIA NeMo Data Designer y NVIDIA Nemotron Speech proporcionan los servicios de datos y síntesis de voz.
¿Por qué el ASR clínico necesita un bucle de retroalimentación repetible?
La IA de voz clínica se está integrando en dictado, documentación ambiental, flujos de trabajo de centros de llamadas, admisión de pacientes y seguimiento post-consulta. Se espera que estos sistemas comprendan términos que son raros en el habla general pero centrales para la tarea: nombres de medicamentos, procedimientos, anatomía, diagnósticos, dispositivos, síntomas y abreviaturas de especialidades.
El audio clínico del mundo real también es difícil de recopilar y compartir. Puede ser costoso, lento de anotar, restringido por requisitos de privacidad y distribuido de manera desigual entre especialidades y términos poco frecuentes. Las grabaciones reales de pacientes son información de salud protegida bajo HIPAA, lo que significa que no pueden compartirse libremente entre equipos, subirse a control de versiones o utilizarse en pipelines de prueba automatizados sin una carga de cumplimiento significativa. El audio sintético no contiene información de salud protegida (PHI) por diseño, lo que lo convierte en la única forma de datos de habla clínica que un equipo puede versionar, compartir y probar. Los datasets públicos pueden no incluir la terminología exacta de la que depende un despliegue.
El desafío práctico no es solo generar más datos. Los desarrolladores necesitan una forma repetible de definir el perfil clínico objetivo, crear un benchmark, revisar el riesgo de pronunciación, medir el comportamiento del ASR, mejorar el modelo y decidir si el siguiente ciclo debe expandir términos, mejorar pronunciaciones, añadir ruido o realizar fine-tuning.
¿Cómo ayudan las habilidades de agentes de IA a la IA de voz clínica?
Las habilidades de agente (agent skills) guían al desarrollador a través de los pasos repetidos de la evaluación ASR clínica: definir un perfil, construir un benchmark centrado en términos, revisar pronunciaciones, generar audio sintético, medir el comportamiento ASR y elegir la siguiente iteración.
En esta publicación, el motor es el bucle de mejora completo: construir el benchmark, evaluar el comportamiento ASR, usar los resultados para decidir qué cambiar y reevaluar después del cambio. El pipeline es una pasada a través de parte de ese bucle, como generar oraciones, añadir marcado de pronunciación, sintetizar audio y escribir el manifiesto.
El pipeline comienza como una conversación, no como un archivo de configuración estático. Puede ejecutar la habilidad de construcción en cualquier entorno de agente (como Claude Code o Codex, por ejemplo) y describir el flujo de trabajo clínico que desea someter a prueba. La habilidad de agente digital health clinical asr build solicita entonces la especialidad, el entorno objetivo, los términos de fallo conocidos y los contextos deseados antes de generar una configuración de benchmark de primera pasada.
La habilidad hace una pregunta a la vez, en orden:
- ¿Qué especialidad o flujo de trabajo?
- ¿Qué modos de fallo de ASR se han observado?
- ¿Qué términos se encuentran diariamente y cuáles son difíciles?
Los términos comunes se convierten en la línea base, y los términos difíciles se convierten en la señal que impulsa el diseño del benchmark.
Desarrollador:
/flywheel-build
Agente:
¿Para qué especialidad o flujo de trabajo es esto?
Ejemplos: práctica ortopédica, dictado oncológico, transferencia en UCI, cardiología ambulatoria.
Desarrollador:
Práctica ortopédica. Enfoque en instrucciones postoperatorias y transferencia en PACU.
El sistema ASR a menudo omite nombres de medicamentos y procedimientos.
Agente:
Comenzaré un perfil de benchmark con términos de medicamentos, procedimientos, anatomía y condiciones, luego ejecutaré QA de pronunciación antes de generar el set de audio completo.Este inicio basado en perfiles permite que el mismo motor se configure para cirugía ortopédica, cardiología, oncología, salud conductual o cualquier otro dominio donde el vocabulario difiera. El trabajo del agente es mantener el flujo de trabajo en los carriles correctos: recopilar el perfil clínico, proponer o ingerir términos, generar primero un pequeño set de QA, dirigir los errores de IPA a revisión y solo entonces construir el benchmark completo.
¿Cómo generar audio sintético listo para TTS desde términos semilla clínicos?
Partiendo de la lista de términos específica del perfil, el pipeline utiliza NeMo Data Designer para expandir los términos semilla en un dataset más rico. NeMo Data Designer genera datos sintéticos de alta calidad desde cero o a partir de datos semilla. Los desarrolladores definen las columnas de salida y las dependencias entre ellas.
NeMo Data Designer resuelve las dependencias mientras maneja el procesamiento por lotes, la ejecución en paralelo, la validación y la vista previa o ejecución completa. En este motor, las columnas de salida producen un registro de voz sintética completo: un ID de muestra único, una oración clínica que contiene el término objetivo, una fuente de pronunciación, una oración en Speech Synthesis Markup Language (SSML) con marcado de fonemas cuando está disponible, y la ruta objetivo para el audio sintetizado.
Para este pipeline, cinco columnas transforman un término clínico en una oración anotada con fonemas y lista para TTS (Figura 1).

La oración de prompt generada debe preservar el término objetivo exacto. Si el modelo sustituye un nombre de marca, equivalente genérico, abreviatura o variante de ortografía, el benchmark ya no es preciso.
Vía NVIDIA Developer.