IA
ModelExpress: Distribución de modelos a velocidad de luz
NVIDIA presenta ModelExpress, una solución para optimizar el ciclo de vida de los pesos de modelos mediante RDMA P2P, eliminando cuellos de botella en almacenamiento.
NVIDIA Developer
60 notas publicadas

En su conferencia Advancing AI, Lisa Su llamó a Helios el rack de IA de mayor rendimiento de la industria, con OpenAI, Meta, Oracle, Anthropic y Microsoft entre sus primeros clientes.

El nuevo backend compila el lenguaje de kernels de PyTorch a Pallas y alcanza 838 TFLOPs en atención flash sobre una TPU v7, cerca del 79% de utilización de un tensor core.

Aprende a integrar herramientas de verificación de errores y depuración en tiempo real para optimizar el rendimiento de tus aplicaciones de trazado de rayos en la GPU.

Autoridades estadounidenses acusan a Moonshot de copiar tecnología de Anthropic, pero investigadores sugieren que el desarrollo del modelo es mucho más complejo.
La API IProgressMonitor, incluida en TensorRT desde hace varias versiones, permite seguir el progreso en tiempo real y abortar una compilación larga antes de malgastar horas de GPU.

La nueva GPU de la plataforma Vera Rubin apunta a las cargas de IA agentica con 336 mil millones de transistores, 288 GB de HBM4 y 50 petaflops en formato NVFP4.

El nuevo framework de código abierto permite a los desarrolladores simular anatomía y dispositivos médicos, acelerando la creación de robots quirúrgicos.

El nuevo switch de 102.4 Tbps llega para potenciar las fábricas de IA, duplicando la capacidad de red necesaria para los modelos de próxima generación.

La libreria ovrtx, ya disponible en GitHub como software preliminar, permite generar salidas de camara, lidar y radar desde escenas OpenUSD sin ceder el control de tu aplicacion.

El nuevo procesador de NVIDIA apuesta por el rendimiento de un solo hilo con 88 nucleos, 176 hilos y una malla coherente de 3,4 TB/s pensada para las cargas de agentes.

El sistema rack-scale de NVIDIA triplica el rendimiento por GPU frente a la generacion anterior al preentrenar DeepSeek-V3 671B, con NVLink de quinta generacion y 1,8 TB/s de ancho de banda por GPU.
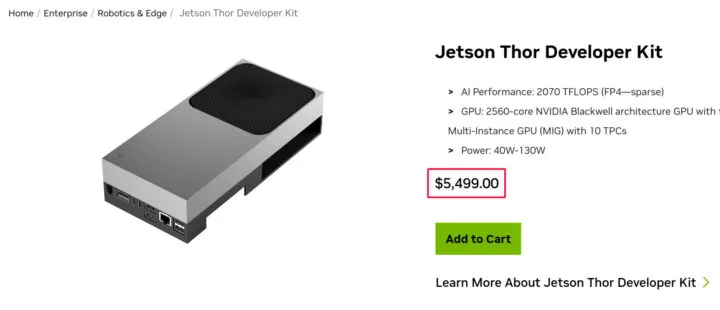
El aumento va de 33% a 101% y afecta a todos los módulos y kits de desarrollo, desde el Jetson Nano hasta el AGX Thor, que ahora cuesta 5.499 dólares.

La nueva plataforma de centros de datos de NVIDIA ya corre en CoreWeave, Google Cloud, Microsoft Azure y Oracle, con un rediseño integral que va del chip a la red eléctrica.

El nuevo chip de servidor de Alphabet, previsto para 2028, prometeria ser entre 6 y 10 veces mas eficiente que sus aceleradores actuales, mientras la industria busca depender menos de NVIDIA.

La sexta generacion de la red de escalado vertical de NVIDIA promete 260 TB/s por rack y 130 TFLOPS de computo en red, con una mejora de 50 veces en tokens por watt entre Hopper y Blackwell.
Microsoft ampliará el uso de chips de IA de AMD en Azure con la plataforma Helios, y un perfil público sugiere que Anthropic también está probando hardware de la firma.
En SIGGRAPH 2026, la compañía sumó conexiones vía Model Context Protocol para Blender, Unreal y Adobe, un detector de video sintético y un modelo de mundo compacto para IA física local.

La nueva plataforma de NVIDIA se diseño para el post-entrenamiento continuo de la IA agentica, entrenando los modelos mas grandes con la cuarta parte de las GPUs que la generacion Blackwell.

nanousd-labs, de Omniverse Labs, permite crear implementaciones de USD directamente desde la especificación estándar, con agentes que escriben y validan el código.

La startup japonesa apuesta por la inteligencia colectiva: varios modelos abiertos coordinados que, dice, pueden competir con los sistemas frontera individuales.

El nuevo DPU y el procesador Vera BlueField-4 STX descargan redes, almacenamiento y seguridad de las CPU para sostener a los agentes de IA, con hasta 6 veces más cómputo que la generación anterior.
El nuevo conjunto de blueprints abiertos de NVIDIA orquesta análisis de video, recuperación de conocimiento y reportes, y cierra el ciclo creando tareas automáticas en herramientas como Jira.

La version 9.1 suma AutoMagicCalib y Multi-View 3D Tracking, dos habilidades que calibran camaras y siguen objetos entre multiples vistas sin configuracion manual.

El nuevo sistema de plugins de PyTorch-Triton carga pases y extensiones en tiempo de ejecucion y activa por defecto las TLX de Meta, con hasta 15% mas rendimiento que las librerias del fabricante.

Los nuevos modulos Thor son la mitad de tamano que los T4000 y T5000, entregan hasta 865 TFLOPS FP4 y llegan en el primer trimestre de 2027 para robotica y computo en el borde.
El desafío de razonamiento de NVIDIA reunió a más de 5.000 participantes que partieron del mismo modelo abierto, y sus mejores soluciones revelan cómo mejorar la precisión sin cambiar el modelo base.

Los nuevos modulos basados en la arquitectura Thor llevan supercomputo de IA compacto a robots humanoides y maquinas autonomas, con rangos que van de 70 TOPS a 2.000 teraflops.

Con TAO, LoRA y un agente de programación, NVIDIA post-entrenó su modelo de razonamiento visual para preguntas sobre video y comprimió a un día lo que antes tomaba una semana de ingeniería.

Un agente de código puede montar el entorno, lanzar experimentos y afinar modelos por su cuenta. En una prueba llevó la precisión de un modelo de 25% a 96,9% en una tarea de conteo visual.

La estrategia de modelos abiertos busca que empresas y países personalicen, auditen y controlen su propia IA, con ahorros de costo de hasta 20 veces frente a modelos cerrados equivalentes.

La plataforma mide no solo si un robot completa la tarea, sino cuando falla, por que falla y con cuanta confianza estadistica se puede afirmar que una politica es mejor que otra.

Un emulador climático de difusión, guiado hacia ciclones tropicales, estima la probabilidad de eventos raros y reduce el error un 25% frente a Monte Carlo.

Un consorcio aleman libera un modelo hibrido Mamba-Transformer entrenado en la nube de Deutsche Telekom, con foco deliberado en datos en aleman y solo 3,2B parametros activos por token.

La plataforma de NVIDIA Research busca resolver uno de los problemas sin resolver de la robótica: cómo medir de verdad si una política de control funcionará fuera del laboratorio.
NVIDIA reemplazó la comunicación por MPI orquestada desde la CPU con acceso directo entre GPUs vía NVSHMEM, y logró hasta el doble de rendimiento en los clústeres Eos y GB200 NVL72.
Un pipeline iterativo con NeMo Data Designer, NeMo Curator y modelos Nemotron produjo 502.536 titulares únicos en 82 rondas sobre un solo nodo B200, para entrenar modelos de IA financiera.

La compañía fabricará su acelerador propio con Broadcom y TSMC para reducir su dependencia de las GPU de Nvidia y AMD, en plena escasez de componentes.
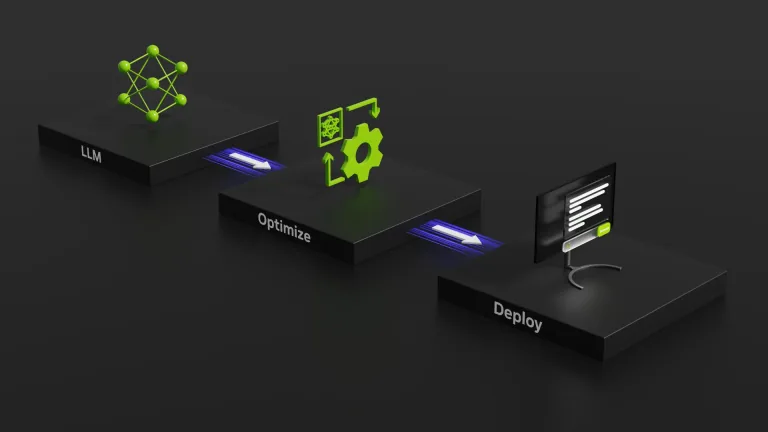
Una guía técnica de NVIDIA explica por qué la forma de un modelo (capas cuadradas, dimensiones múltiplos de 128 y más ancho que profundo) define cuánto rendimiento se saca de una GPU Blackwell.
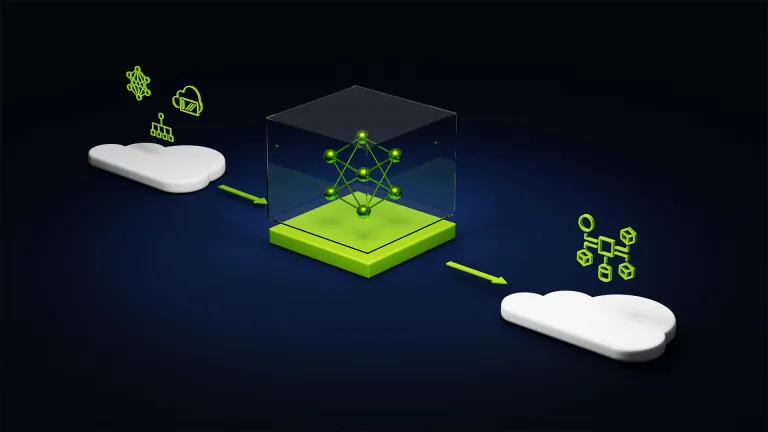
El host offloading libera memoria HBM al mover activaciones a la RAM del sistema, con hasta 57% mas rendimiento al entrenar modelos como DeepSeek-V3 671B en NVIDIA Grace Blackwell.
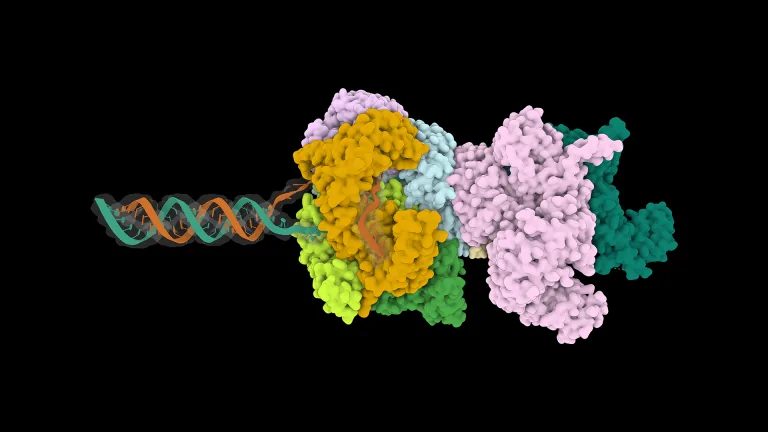
El BioNeMo Agent Toolkit combina MSA en GPU, cuEquivariance y Fold-CP para predecir estructuras biomoleculares de hasta 32.000 aminoacidos, un salto clave para el descubrimiento de farmacos.

NVIDIA y LangChain muestran cómo la ingeniería de arnés acerca a un modelo abierto a la precisión de frontera, ajustando el entorno del agente en lugar de los pesos del modelo.

NVIDIA explica cómo combinar operaciones en un solo kernel reduce el tráfico a memoria global y el overhead de lanzamiento, con ejemplos en CUDA C++, torch.compile y cuda.compute.
NVIDIA integró río arriba la habilitación inicial de su núcleo Armv9.2-A en el compilador LLVM Clang, meses antes de que el chip Rosa llegue al mercado.

NVIDIA describe un asistente que reúne contexto, corre analisis especializado y redacta una recomendacion por cada alarma, con inferencia acelerada por GPU y respuesta en segundos.
El ingeniero Dhruv Chawla integro la opcion -mcpu=rigel al Git de GCC apenas minutos despues de que NVIDIA confirmara el nuevo nucleo.

LangChain ajusto su harness Deep Agents para el modelo abierto de NVIDIA y logro paridad con los modelos cerrados a un decimo del costo de inferencia.

La alianza lleva el modelo fundacional GR00T 1.7 y el framework Isaac Teleop a la biblioteca robotica abierta de Hugging Face, con Cosmos 3 anunciado como el proximo paso.

La nueva CPU de NVIDIA para cargas agénticas usa 88 núcleos Olympus y promete 40% menos latencia y el triple de ancho de banda por núcleo frente a los x86 de centro de datos.

La plataforma de red de acceso radio acelerada por GPU logra hasta 1,62x más rendimiento en beamforming y 1,3x en adaptación de enlace frente a los métodos tradicionales basados en CPU.

La plataforma abre bajo Apache 2.0 un flujo completo de simulación, entrenamiento y despliegue, con un modelo visión-lenguaje-acción entrenado en 32.000 horas de demostraciones humanas.
El sucesor de Vera promete más rendimiento por núcleo que Olympus sin agrandar el silicio, y su soporte inicial ya empezó a subirse al compilador GCC.
NVIDIA posiciona a Vera como una nueva clase de CPU optimizada para el bucle de agentes, con nucleo Olympus que promete 50% mas instrucciones por ciclo que Grace.

Los papers aceptados en la conferencia muestran que los modelos de frontera abiertos y la infraestructura abierta ya son la base del trabajo cientifico en inteligencia artificial.
Problemas en la fabricación del PCB midplane demoran más de un año el próximo rack IA de NVIDIA. Ibiden cae 10%, Kingboard Laminates 18% y Rubin Ultra pierde su variante de 4 dies.

Nonuniform Tensor Parallelism reconfigura el paralelismo tensorial en caliente cuando una GPU falla dentro de un dominio NVLink, con overhead bajo 1%.

La alianza integra el modelo VLA para humanoides y el framework de teleoperacion en la libreria open source de Hugging Face, con Cosmos 3 planeado en breve.
El fabricante de GPUs se compromete a arrendar la capacidad no colocada por los proveedores jóvenes, financiando a la vez el hardware y el centro de datos que lo aloja.
El nuevo binario Tag-Length-Value reemplaza el mix de headers y ELF que hoy usa Nouveau, para que el driver escrito en Rust parsee las imágenes de firmware de la GPU con menos código boilerplate.

La versión 153, que llega el 21 de julio, elimina la necesidad del driver nvidia-vaapi en Linux apoyándose en el soporte Vulkan Video de FFmpeg.
Otros temas que aparecen junto a #nvidia en nuestra cobertura editorial.