
Un nuevo benchmark pone a trabajar a modelos punteros como GPT-5.4 y Claude Opus 4.6 en el tipo de tareas que un banquero junior maneja a diario. Ninguno de los outputs fue calificado como listo para enviar a un cliente. Aun así, más de la mitad de los banqueros dijo que lo usaría como punto de partida.
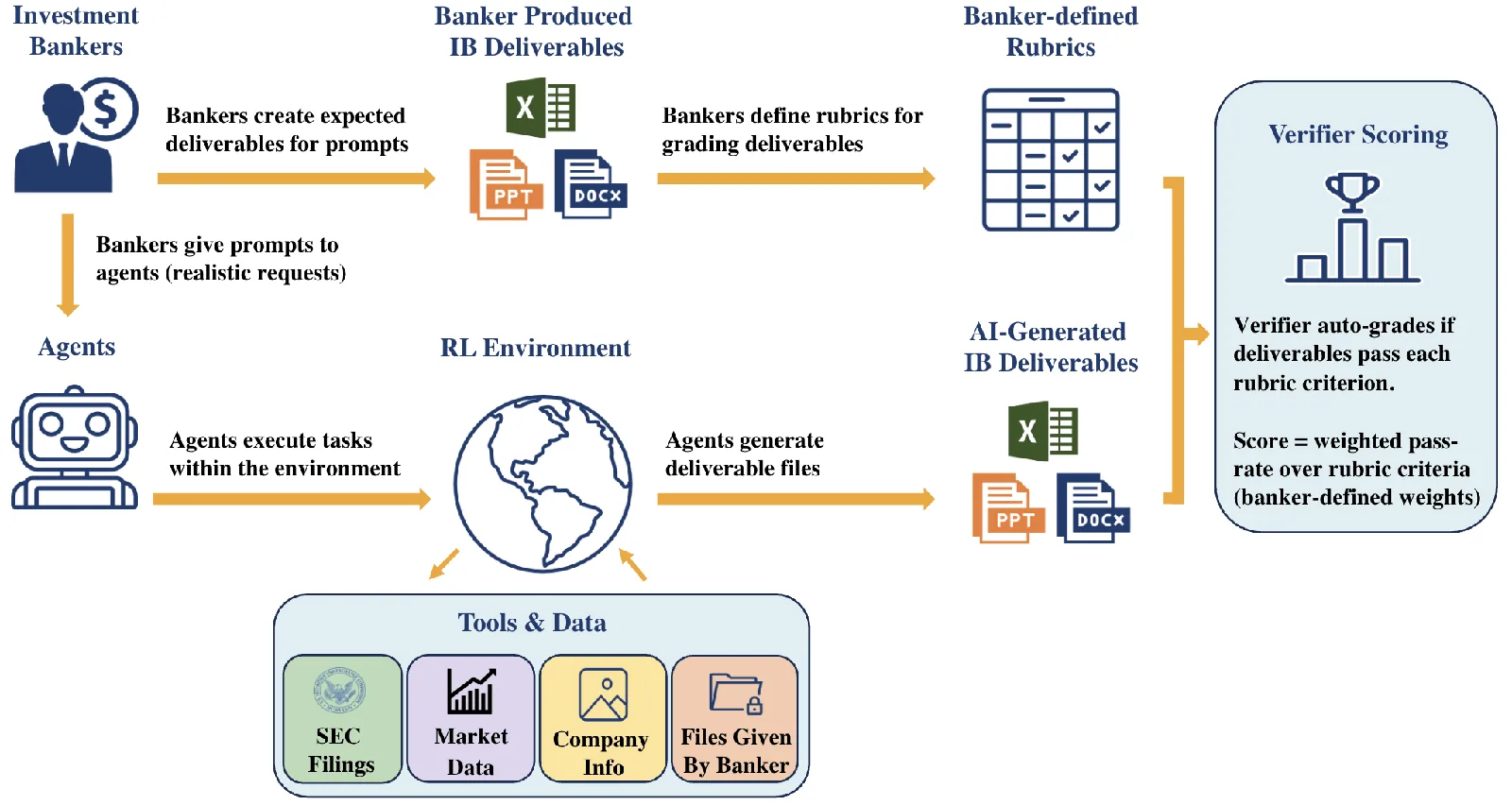
Un equipo de investigación de Handshake AI y la Universidad McGill ha publicado BankerToolBench, un benchmark de código abierto que prueba a agentes de IA contra los flujos de trabajo típicos de los banqueros junior.
Handshake AI es el brazo empresarial de la plataforma de carrera profesional Handshake, que coloca a académicos y profesionales validados dentro de los laboratorios de IA para ayudar a entrenar y evaluar sus modelos. Tras correr nueve modelos punteros actuales por la prueba, el veredicto de los banqueros involucrados es contundente: ninguno de los outputs es apto para uso con clientes.
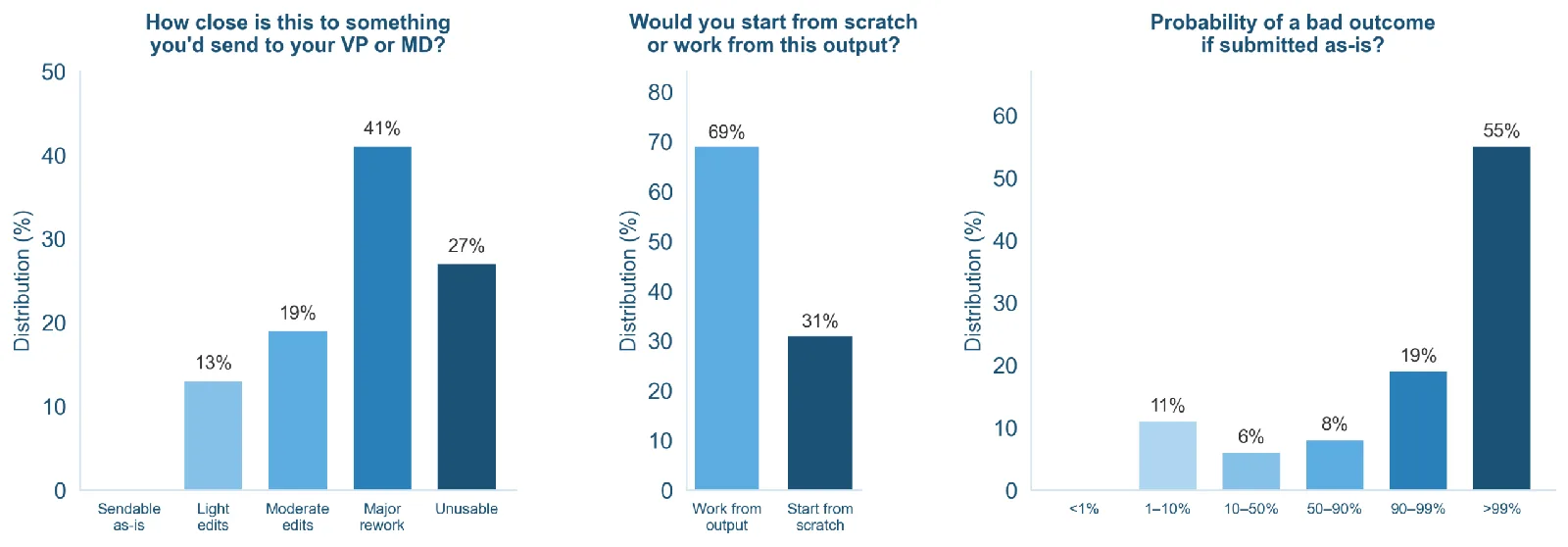
El equipo enroló a unos 500 banqueros de inversión actuales y antiguos de firmas como Goldman Sachs, JPMorgan, Evercore, Morgan Stanley y Lazard. De ellos, 172 diseñaron las propias tareas, registrando más de 5.700 horas de trabajo. Cada una de las 100 tareas le tomó a un banquero humano un promedio de cinco horas, con algunas alcanzando hasta 21 horas.
Modelos reales en Excel, no solo respuestas de texto
BankerToolBench evalúa los entregables reales que un banquero junior pasaría a su supervisor: modelos financieros en Excel con fórmulas funcionales, presentaciones de PowerPoint para reuniones con clientes, informes en PDF y memos en Word.
Los agentes tienen que escarbar en data rooms, extraer datos de plataformas de mercado como FactSet y Capital IQ, y procesar reportes ante la SEC. Según el paper, una sola tarea puede gatillar hasta 539 llamadas al modelo de lenguaje, con el 97% atadas a uso de herramientas o ejecución de código.
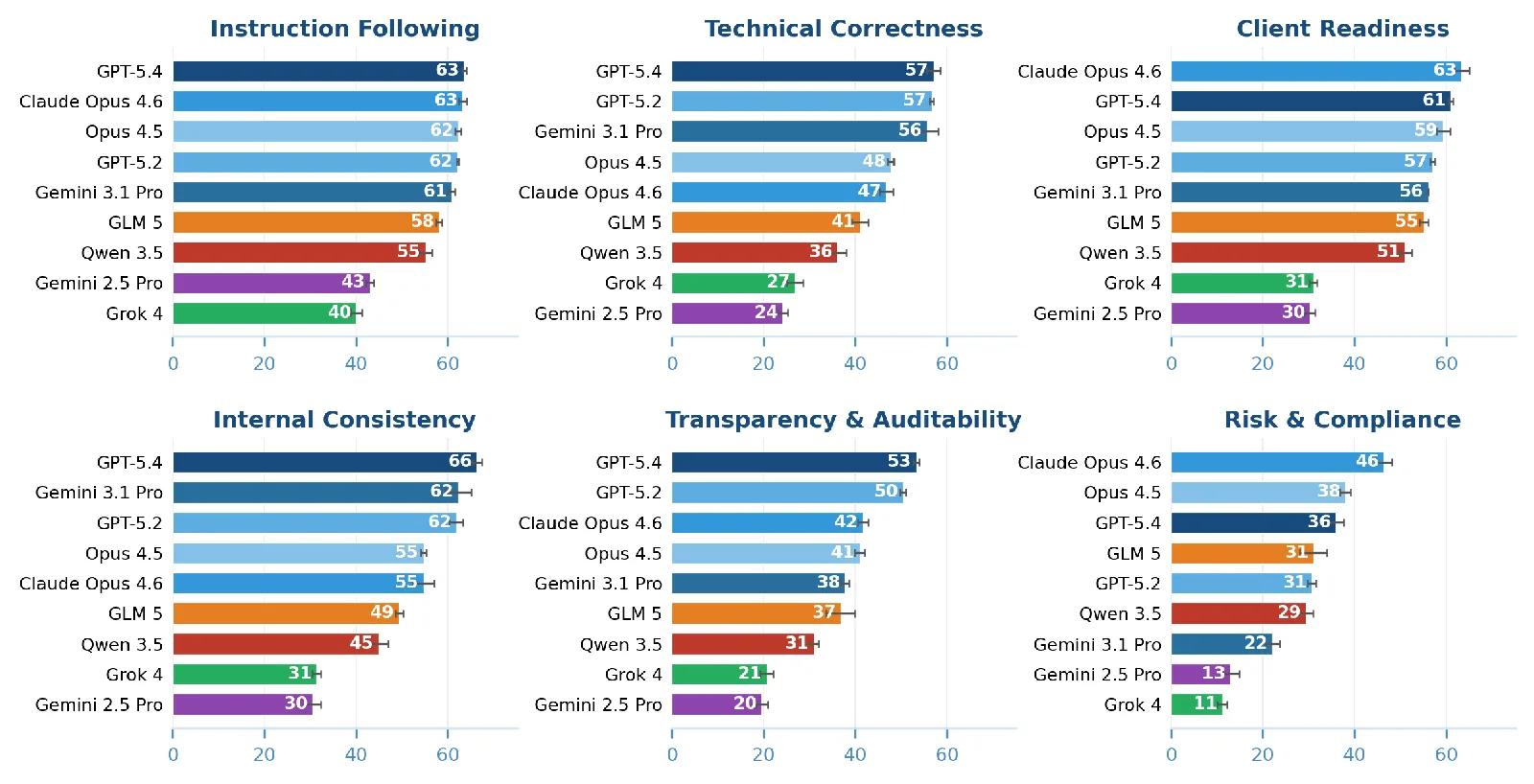
Cada entregable se contrasta con una rúbrica diseñada por banqueros que promedia 150 criterios individuales. Los criterios cubren seis áreas, incluyendo corrección técnica, idoneidad para el cliente, cumplimiento, auditabilidad y consistencia entre archivos.
La calificación corre por cuenta de un verificador de IA construido por los autores llamado Gandalf, basado en Gemini 3 Flash Preview. Coincide con los revisores humanos el 88,2% de las veces, ligeramente por encima del 84,6% de coincidencia entre dos revisores humanos.
GPT-5.4 lidera, pero está lejos de aprobar
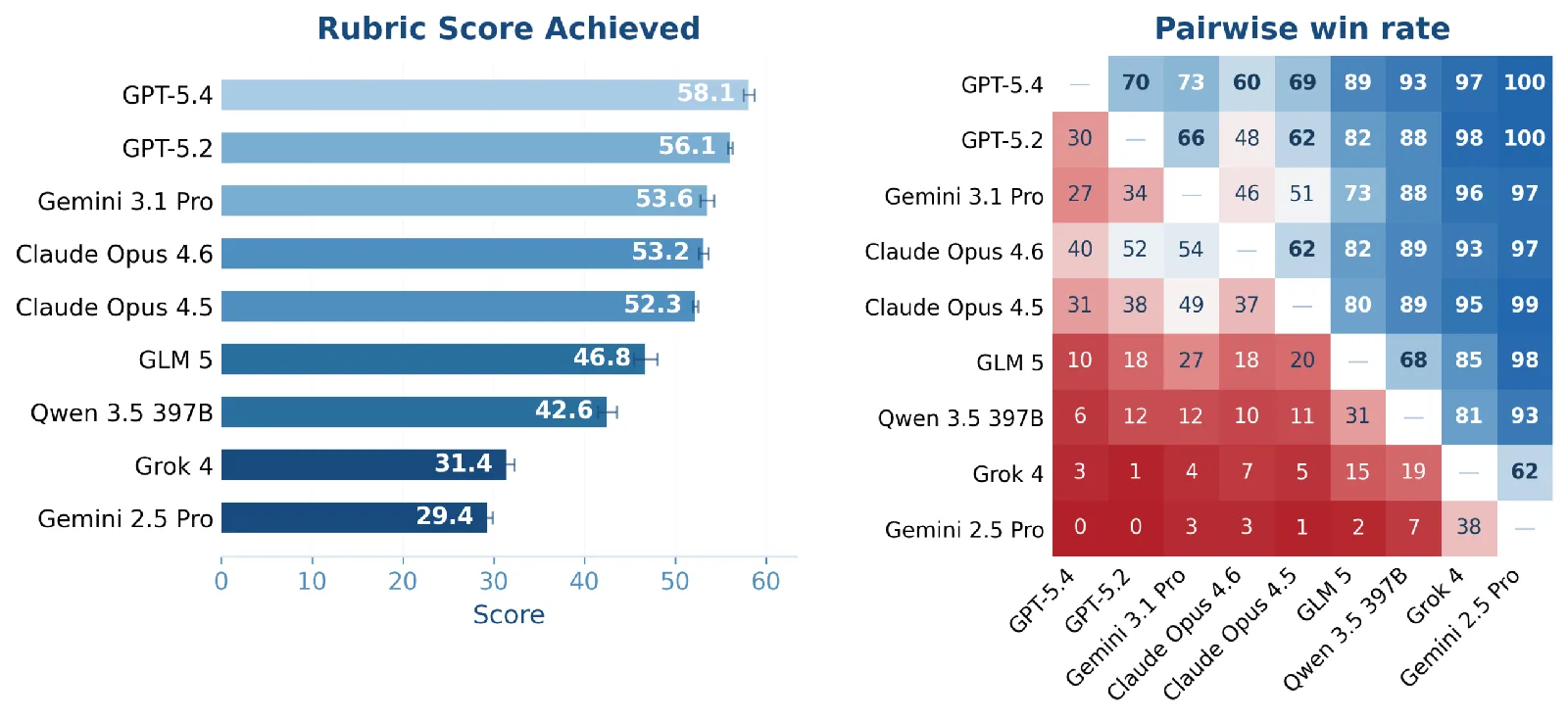
El equipo probó GPT-5.2, GPT-5.4, Claude Opus 4.5 y 4.6, Gemini 2.5 Pro, Gemini 3.1 Pro Preview, Grok 4, y los modelos open source Qwen-3.5-397B y GLM-5. GPT-5.4 quedó al frente pero igual reprobó casi la mitad de los criterios. Apenas el 16% de sus outputs superó el umbral en que los banqueros lo aceptarían como un punto de partida útil. Si se exigen tres corridas consistentes, esa cifra baja al 13%.
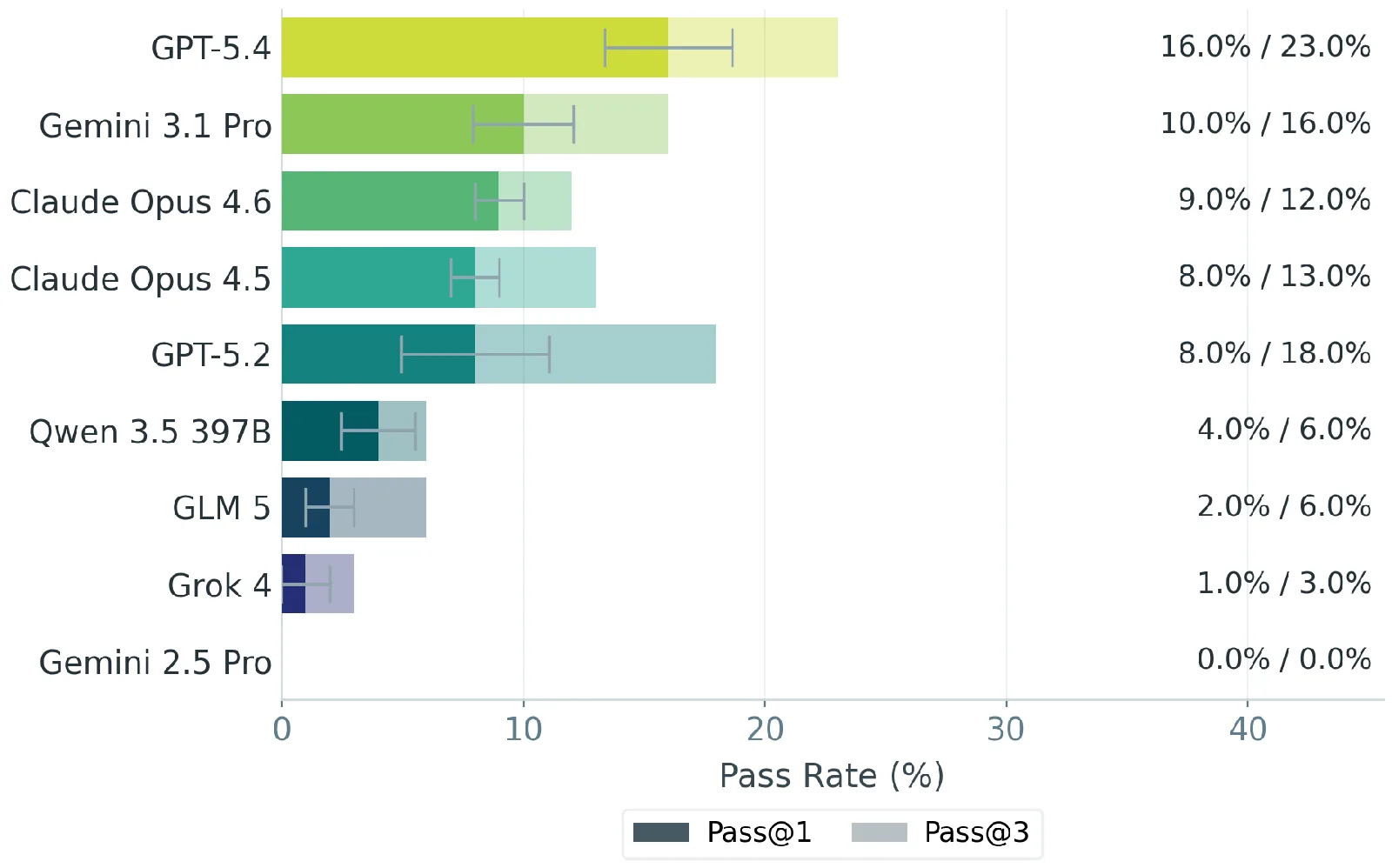
Ningún output de ningún modelo fue calificado como listo para enviar tal cual. Con GPT-5.4, apenas el 2% de las tareas pasó cada criterio críticamente ponderado. Con Gemini 2.5 Pro, esa cifra fue cero.
Bonito por fuera, roto por dentro
Los outputs de Claude Opus 4.6 lucen pulidos a primera vista, según los investigadores. Pero los modelos de Excel revelan una falla fundamental: la mayoría de las cifras clave están hardcodeadas como valores fijos en lugar de calcularse mediante fórmulas. Eso es un dealbreaker en banca de inversión, anota el paper, porque imposibilita el análisis de escenarios. Cambia el precio de compra en el modelo, y nada se actualiza. Claude Opus 4.5 tuvo el mismo problema.
Un análisis de las trayectorias del agente GPT-5.4 expone cuatro modos de falla recurrentes. El más común, con un 41%, son bugs en la generación de código y fórmulas. Los agentes invocan funciones de python-pptx que no existen, y en lugar de arreglar el problema de fondo, simplemente borran la línea rota.
En el 27% de los casos, la lógica de negocio se quiebra, como sumar sinergias de costo a la línea de ingresos en lugar de a costos. Otro 18% de los errores proviene de consultas de datos abortadas. Y en el 13% de los casos, los agentes fabrican cifras faltantes y las presentan como obtenidas de fuente.
Errores sutiles que se cuelan
Los ejemplos en el paper ilustran lo sutiles que pueden ser estas fallas. En una presentación generada, el verificador detecta una cifra de ingresos de 189.500 millones de dólares en una diapositiva y 201.000 millones en la siguiente, ambas cubriendo el mismo período.
En otro caso, el agente usa el rojo de Netflix como color de acento aunque el manual de estilo del banco exige un azul uniforme. En un análisis competitivo para un deal farmacéutico, un agente fabricó datos específicos de un ensayo clínico tras quedarse sin resultados en la base de datos de la SEC.
Los modelos en general rinden mejor en tareas de PowerPoint que en trabajo en Excel. Las tareas más duras caen en mercados de deuda, modelos de fusión y tablas de estructura de capital. El equipo atribuye parte del déficit a la ausencia de conocimiento de dominio. Cuando las tareas se enriquecen con el tipo de contexto que un banquero da por sentado, los puntajes suben de manera significativa.
También como herramienta de entrenamiento
BankerToolBench también puede usarse para reinforcement learning, según los autores. En experimentos con Qwen-3-4B y 32B, los métodos Dr. GRPO y DPO multiplicaron por cinco a trece el desempeño en el benchmark, aunque desde una base muy baja.
El equipo señala varias limitaciones: el benchmark se centra en EE.UU., no incluye información confidencial de deals, y no captura la iteración en equipo dentro de un banco real. Aun así, los autores lo califican como una de las pruebas más detalladas hasta la fecha sobre si los agentes de IA pueden manejar trabajo intelectual exigente. Por ahora, la respuesta es no. El benchmark completo, incluyendo datos, rúbricas y verificador, está disponible públicamente.
Los hallazgos coinciden con otra investigación reciente. Un estudio de Vals.ai realizado con un banco sistémico global encontró que el o3 de OpenAI alcanzó solo 48,3% de precisión en tareas de análisis financiero. Investigación de UC Berkeley concluyó que los equipos que logran que los agentes funcionen en producción se apoyan en setups simples y rigurosamente controlados con pocos pasos. Y un análisis de Carnegie Mellon y Stanford sostiene que el desarrollo de agentes se ha enfocado demasiado en tareas de código, dejando campos económicamente importantes como gestión, derecho y finanzas fuera de los benchmarks.
Mientras tanto, laboratorios de IA como Anthropic están trabajando exactamente en las debilidades que BankerToolBench expone. Anthropic recientemente introdujo una función que permite a Claude alternar por su cuenta entre Excel y PowerPoint, y los plugins de Cowork ahora canalizan servicios de datos de mercado como FactSet, MSCI y LSEG directamente en el flujo de trabajo.



