OpenAI presenta GPT-5.5, una "nueva clase de inteligencia" al doble de precio
Puntos clave
- OpenAI lanzó GPT-5.5, un nuevo modelo basado en agentes capaz de gestionar tareas complejas de forma autónoma, como escribir código, realizar búsquedas en línea y analizar datos mediante múltiples herramientas.
- El modelo supera a competidores como Claude Opus 4.7 de Anthropic y Gemini 3.1 Pro de Google en benchmarks clave, especialmente en programación y matemáticas avanzadas, sin sacrificar velocidad, aunque no lidera en todos los aspectos.
- Se lanzó también una variante más capaz, GPT-5.5 Pro, como socio de investigación iterativo. Ambos modelos están disponibles para usuarios de pago de ChatGPT y Codex en planes Plus, Pro, Business y Enterprise, mientras que el acceso vía API llegará pronto al doble de costo.
Actualización – 25 de abril de 2026
- Se añadió disponibilidad de API.
Actualización del 25 de abril de 2026:
GPT-5.5 y GPT-5.5 Pro ya están disponibles a través de la API de Responses y Chat Completions de OpenAI, cada uno con una ventana de contexto de un millón de tokens. "Los agentes construidos con GPT-5.5 pueden planificar, recopilar contexto, llamar a herramientas, recuperarse de ambigüedades y completar flujos de trabajo más largos con menos guía", escribe OpenAI. GPT-5.5 Pro está diseñado para "trabajos de mayor precisión", señala la empresa.
El laboratorio de pruebas independiente Artificial Analysis ya ha evaluado GPT-5.5: el nuevo modelo de OpenAI obtiene el primer lugar general por un margen estrecho sobre Claude de Anthropic y Gemini de Google, pero muestra una debilidad notable con las alucinaciones. Los costos efectivos de la API son aproximadamente un 20 por ciento más altos que los de GPT-5.4, según el laboratorio; los precios duplicados por token en papel se compensan parcialmente con un menor uso de tokens por tarea.
Artículo original del 23 de abril de 2026:
OpenAI ha anunciado GPT-5.5, un modelo agentico diseñado para manejar tareas complejas de forma autónoma a través de múltiples herramientas. En teoría, el precio de su API es el doble.
OpenAI ha revelado GPT-5.5, calificándolo como una "nueva clase de inteligencia para el trabajo real y para potenciar agentes". El modelo está construido para comprender objetivos complejos, utilizar herramientas, verificar su propia salida y trabajar en tareas de forma independiente hasta que se completen, según OpenAI. Ya está disponible para usuarios de pago de ChatGPT y Codex.
Los flujos de trabajo de agentes son el principal atractivo
Según OpenAI, GPT-5.5 es especialmente fuerte en escritura y depuración de código, investigación web, análisis de datos, creación de documentos y hojas de cálculo, y operación de software. El modelo está diseñado para cambiar entre diferentes herramientas por sí mismo hasta que una tarea finaliza.
OpenAI observa las mayores mejoras en cuatro áreas: codificación agentica, uso de computadoras, trabajo de conocimiento e investigación científica temprana. Estas áreas requieren razonamiento a través de contextos y la capacidad de realizar acciones durante períodos prolongados, indica la compañía.
En Terminal-Bench 2.0, un benchmark de codificación para flujos de trabajo agenticos, GPT-5.5 obtiene un 82,7 por ciento según OpenAI, 7,6 puntos porcentuales por encima de su predecesor GPT-5.4 (75,1 por ciento). Claude Opus 4.7 de Anthropic alcanza el 69,4 por ciento y Gemini 3.1 Pro de Google llega al 68,5 por ciento.
La brecha se amplía aún más en problemas matemáticos más difíciles. En FrontierMath Tier 4, GPT-5.5 obtiene un 35,4 por ciento, en comparación con el 22,9 por ciento de Claude Opus 4.7 y el 16,7 por ciento de Gemini 3.1 Pro. La variante Pro, GPT-5.5 Pro, eleva esa cifra al 39,6 por ciento.
OpenAI afirma que GPT-5.5 ofrece estas ganancias de rendimiento sin sacrificar velocidad. Según se informa, el modelo iguala la latencia por token de GPT-5.4 mientras utiliza significativamente menos tokens para completar las mismas tareas de Codex.

El rendimiento en contextos largos también mejoró significativamente. En el benchmark MRCR v2, que prueba la fiabilidad con la que un modelo puede localizar múltiples piezas de información oculta en textos muy largos, GPT-5.5 salta al 74,0 por ciento con longitudes de contexto de 512K a 1M tokens, frente al 36,6 por ciento de GPT-5.4. En la prueba Graphwalks BFS con un millón de tokens, GPT-5.5 pasa del 9,4 por ciento (GPT-5.4) al 45,4 por ciento.
La dominancia no es total, sin embargo. En SWE-Bench Pro, que prueba la resolución real de problemas de GitHub, Claude Opus 4.7 supera a GPT-5.5 con un 64,3 por ciento frente al 58,6 por ciento. OpenAI señala, no obstante, que Anthropic reconoció signos de memorización en algunas de esas tareas.
En MCP Atlas, un benchmark de uso de herramientas realizado por Scale AI, GPT-5.5 obtiene un 75,3 por ciento, quedando por detrás de Claude Opus 4.7 (79,1 por ciento) y Gemini 3.1 Pro (78,2 por ciento). El modelo base también se queda ligeramente atrás de Gemini en BrowseComp, un benchmark de investigación web, con un 84,4 por ciento frente al 85,9 por ciento.
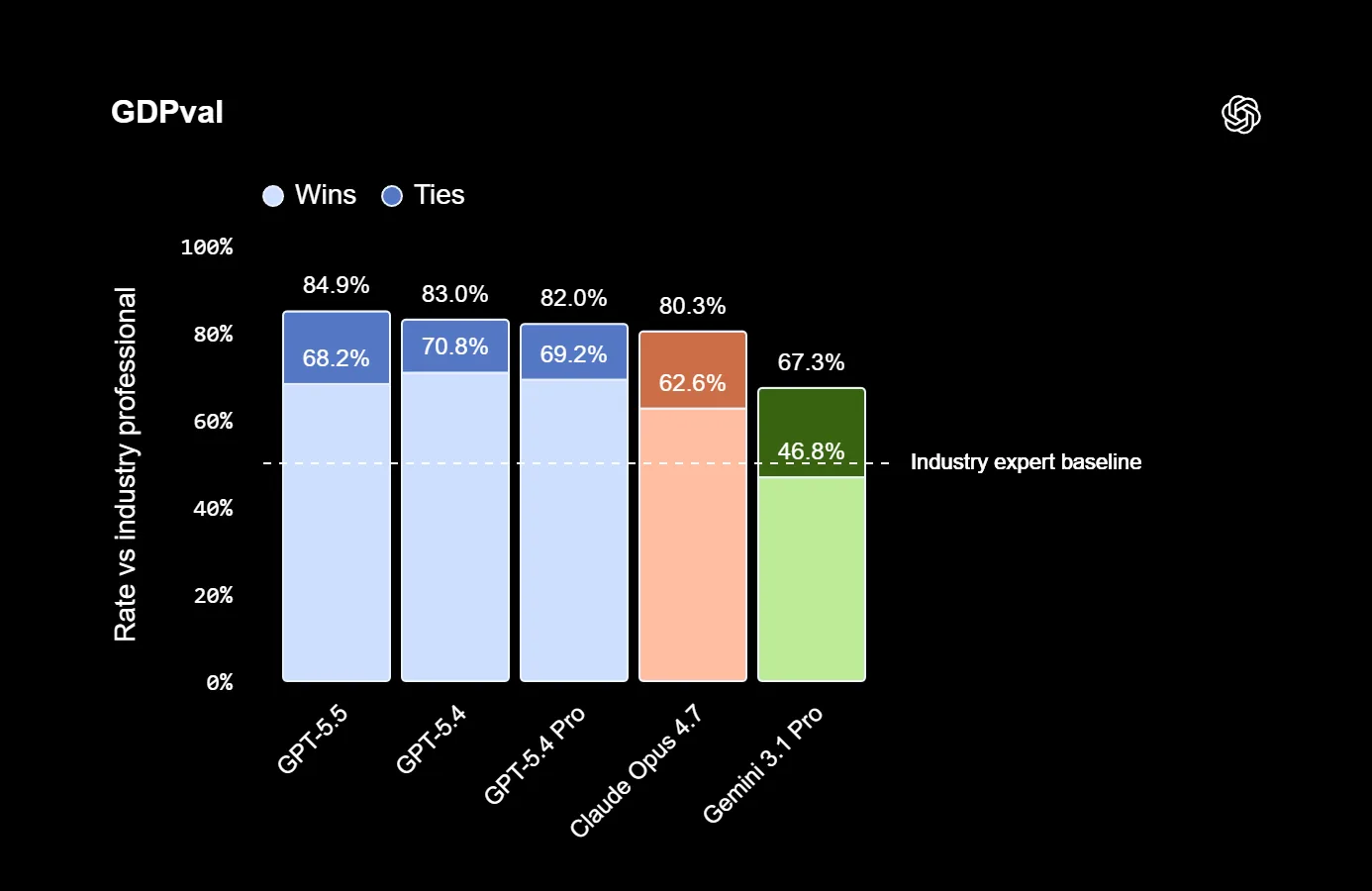
Y GPT-5.5 apenas movió la aguja en GDPval, un benchmark diseñado para medir el rendimiento en tareas del mundo real a través de 44 ocupaciones. GPT-5.5 obtiene un 84,9 por ciento, solo una mejora marginal sobre el 83,0 por ciento de GPT-5.4. Una visión general completa de todos los benchmarks está disponible aquí.
El modelo fue desarrollado y optimizado junto a los sistemas NVIDIA GB200 y GB300-NVL72. OpenAI afirma que GPT-5.5 y Codex ayudaron a optimizar la propia infraestructura de servicio de la compañía; Codex analizó patrones de tráfico de producción y escribió sus propios algoritmos heurísticos para el balanceo de carga, lo que resultó en un aumento de más del 20 por ciento en la velocidad de generación de tokens. "El modelo ayudó a mejorar la infraestructura que lo sirve", escribe OpenAI.
GPT-5.5 Pro aspira a ser un "socio de investigación"
Junto al modelo estándar, OpenAI lanza GPT-5.5 Pro. La empresa sostiene que las mejoras de inferencia full-stack hacen que el modelo más potente sea mucho más práctico para cargas de trabajo pesadas. Los primeros evaluadores lo llamaron un "socio de investigación" iterativo que funciona mejor cuando recibe un contexto rico de documentos y plugins.
Hasta ahora, OpenAI solo ha compartido resultados de benchmarks de GPT-5.5 Pro para tres de nueve pruebas: BrowseComp, FrontierMath Tier 1-3 y FrontierMath Tier 4. Supera al modelo base en las tres.
Capacidades de ciberseguridad calificadas como "Altas"
OpenAI clasifica las capacidades biológicas, químicas y de ciberseguridad de GPT-5.5 como "Altas" en su Marco de Preparación, la misma calificación que sus predecesores recientes, pero no "Crítica". El modelo muestra un mejor rendimiento en ciberseguridad en comparación con GPT-5.4, obteniendo un 81,8 por ciento en el benchmark CyberGym (frente al 79,0 por ciento) y un 88,1 por ciento en tareas internas de captura de bandera (frente al 83,7 por ciento).
Al mismo tiempo, OpenAI está implementando clasificadores más estrictos para riesgos cibernéticos potenciales, lo que podría generar inicialmente más rechazos, señala la empresa. El programa Trusted Access for Cyber brindará a investigadores de seguridad verificados un acceso ampliado a las capacidades de ciberseguridad. OpenAI también trabaja con socios gubernamentales para proteger la infraestructura crítica. Una tarjeta de sistema con detalles de seguridad adicionales está disponible aquí.
Los usuarios de pago obtienen acceso primero; los precios de API se duplican
GPT-5.5 Thinking es n
Vía The Decoder.