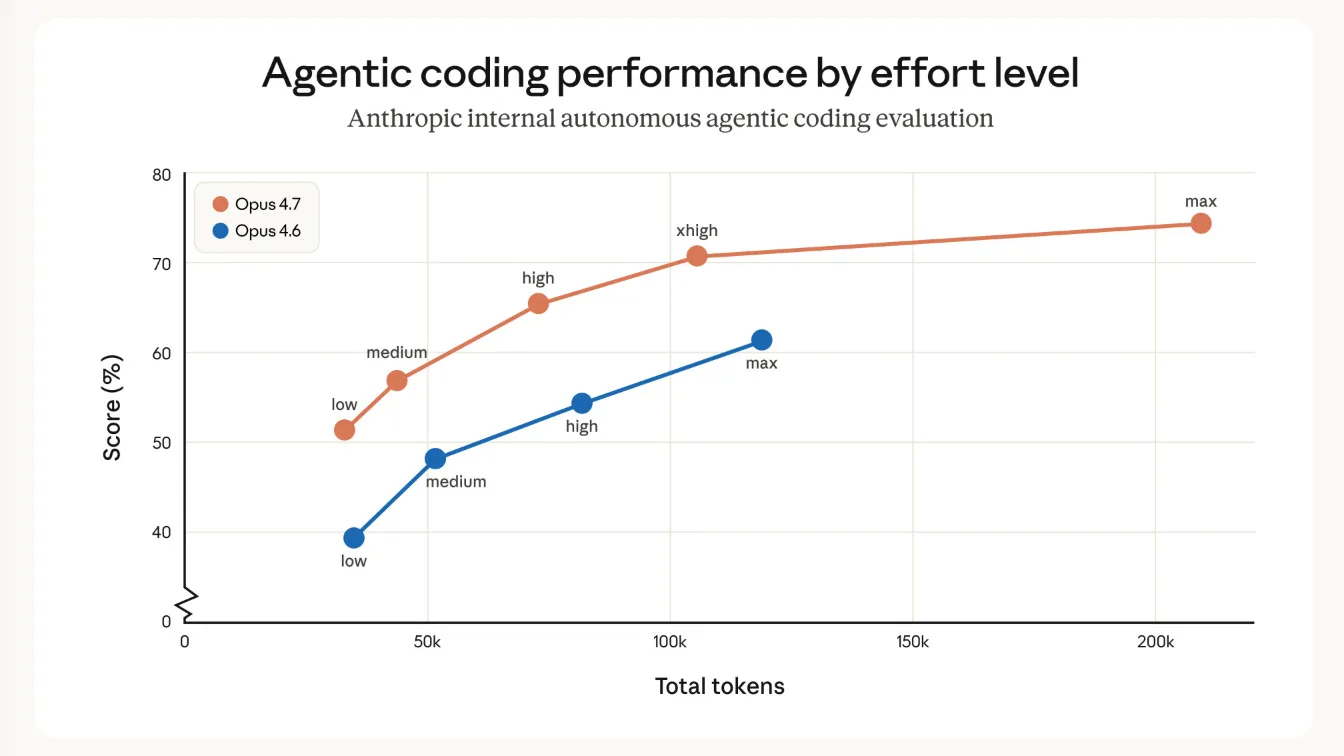
El nuevo modelo insignia de Anthropic, Claude Opus 4.7, ofrece mejoras importantes en tareas de programación. Durante el entrenamiento, la compañía intentó deliberadamente reducir ciertas capacidades de ciberseguridad.
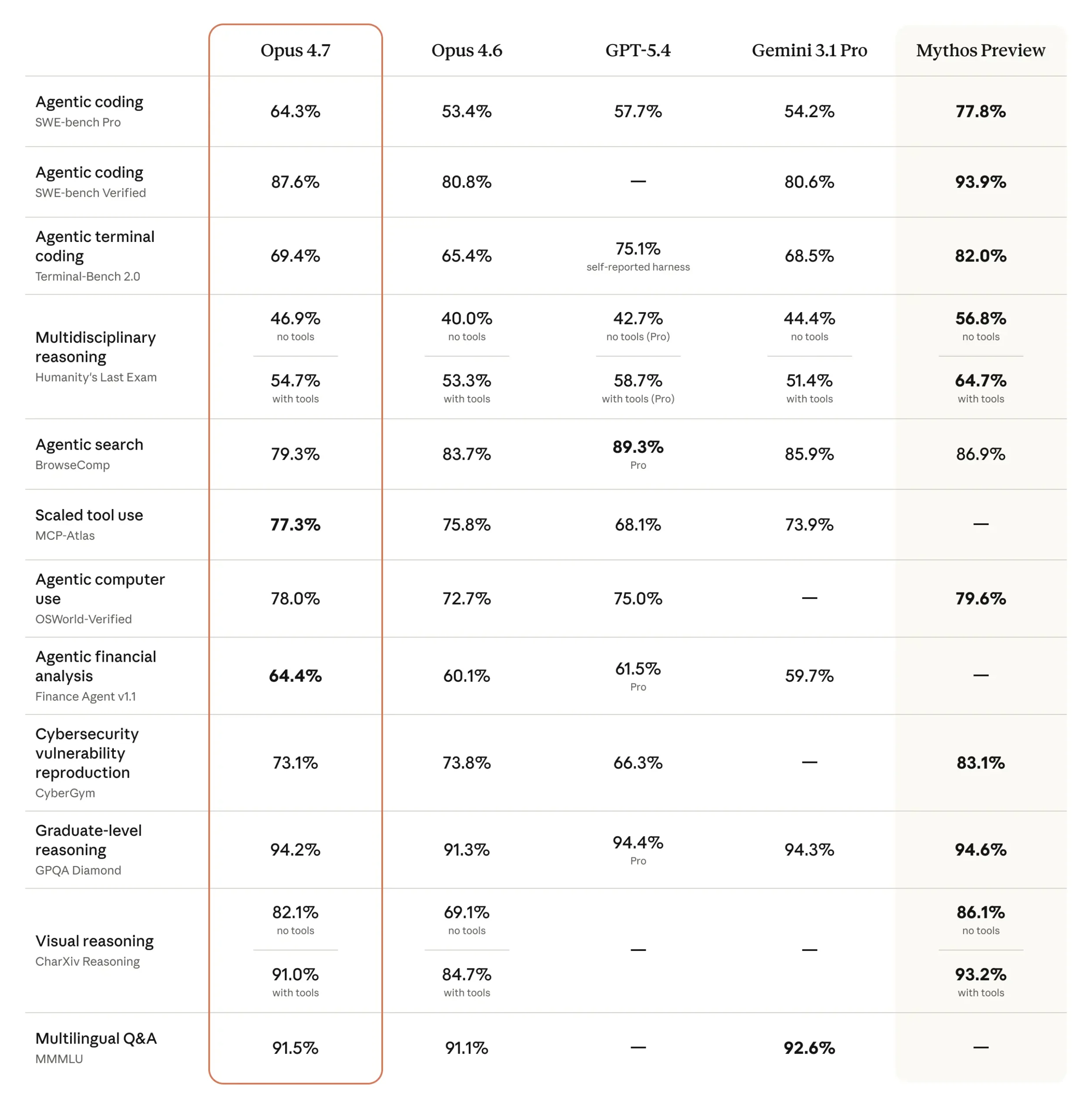
Anthropic ha lanzado Claude Opus 4.7, una actualización directa de su predecesor, Opus 4.6. La compañía posiciona el modelo principalmente como un paso adelante en la programación autónoma. En el benchmark de código SWE-bench Pro, Opus 4.7 obtiene un 64.3 por ciento, superando el 53.4 por ciento de su predecesor y por delante del GPT-5.4 de OpenAI con un 57.7 por ciento. El propio modelo superior de Anthropic, Claude Mythos Preview, sigue liderando por un amplio margen con un 77.8 por ciento.
Anthropic señala que Opus 4.7 sigue las instrucciones con mayor precisión que su predecesor. La empresa destaca que los prompts escritos para modelos más antiguos ahora podrían producir resultados inesperados, ya que Opus 4.7 interpreta las instrucciones de manera más literal que Opus 4.6, el cual a veces las interpretaba libremente o se saltaba partes por completo.
La resolución de imagen se triplica para una mejor comprensión visual
Opus 4.7 procesa imágenes de hasta 2,576 píxeles en el borde más largo, lo que según Anthropic equivale a aproximadamente 3.75 megapíxeles, más del triple de lo que los modelos anteriores de Claude podían manejar. Esto no es un ajuste de la API, sino un cambio a nivel del modelo: las imágenes se procesan automáticamente a mayor resolución, aunque como resultado consumen más tokens. Los usuarios que no necesiten el detalle adicional pueden reducir la resolución de las imágenes antes de enviarlas.
Anthropic ve esto como una ventaja importante para los agentes de uso de computadora (computer-use agents) que necesitan leer capturas de pantalla densas y para extraer datos de diagramas complejos. En el benchmark de Razonamiento de Documentos (OfficeQA Pro), la compañía reporta una precisión del 80.6 por ciento, frente al 57.1 por ciento con Opus 4.6. Los benchmarks también muestran ganancias significativas en razonamiento biomolecular y navegación visual (ScreenSpot-Pro).
Anthropic limita deliberadamente las capacidades cibernéticas
Uno de los aspectos más notables de este lanzamiento es cómo Anthropic maneja las capacidades de ciberseguridad del modelo. La empresa afirma que intentó experimentalmente reducir ciertas capacidades cibernéticas de forma diferencial durante el entrenamiento. Las nuevas salvaguardas están diseñadas para detectar y bloquear automáticamente las solicitudes que sugieran un uso de ciberseguridad prohibido o de alto riesgo.
El contexto de esto es el recientemente anunciado Project Glasswing, en el cual Anthropic abordó los riesgos y beneficios de los modelos de IA para la ciberseguridad. La compañía había explicado que restringiría el lanzamiento del modelo más capaz, Mythos Preview, y primero probaría nuevas salvaguardas en modelos menos capaces. Opus 4.7 es el primer caso de prueba para esta estrategia.
Los investigadores de seguridad que deseen usar el modelo para pruebas de penetración o red-teaming pueden registrarse en un nuevo Programa de Verificación Cibernética.
Las alucinaciones disminuyen pero no desaparecen
Según la tarjeta del sistema, Anthropic distingue entre dos tipos de alucinaciones: alucinaciones factuales —afirmaciones erróneas sobre el mundo, como citas inventadas o datos incorrectos— y alucinaciones de entrada (input hallucinations), donde el modelo actúa como si tuviera acceso a una herramienta o archivo adjunto que en realidad no existe.
En cuanto a las alucinaciones factuales, Opus 4.7 tiene un rendimiento superior o igual a Opus 4.6 en cuatro benchmarks, pero se queda corto frente a Mythos Preview. Anthropic dice que la brecha proviene principalmente de la mayor tasa de aciertos de Mythos Preview en datos oscuros, no de una mayor tasa de error en Opus 4.7.
Para las alucinaciones de entrada, Opus 4.7 logra la tasa de alucinación más baja de todos los modelos probados cuando los usuarios solicitan una herramienta que no está disponible. Cuando falta información de contexto, se acerca a Mythos Preview y se sitúa muy por delante de los modelos más antiguos. Sin embargo, Anthropic reconoce que los casos de prueba para el conjunto de herramientas se adaptaron a las debilidades de Opus 4.6, lo que sesga los resultados de ese modelo.
Al lidiar con preguntas basadas en hechos inventados, Opus 4.7 rinde a la par que Opus 4.6 y por debajo de Mythos Preview. Bajo presión, como cuando los usuarios o los prompts del sistema empujan al modelo a contradecir su propia evaluación, Opus 4.7 es más honesto que Opus 4.6 pero menos firme que Mythos Preview.
Los resultados de alineación son mixtos
En general, Anthropic describe el perfil de seguridad de Opus 4.7 como similar al de Opus 4.6, con bajas tasas de engaño, adulación y cooperación con el mal uso. El modelo es más resistente a los ataques de inyección de prompts (prompt injection).
Un problema conocido de los modelos anteriores de Claude persiste parcialmente: negarse a ayudar con investigaciones legítimas de seguridad en IA. Según la tarjeta del sistema, Opus 4.7 todavía se niega a asistir en el 33 por ciento de las tareas simuladas de investigación de seguridad. Esa es una caída significativa desde el 88 por ciento con Opus 4.6, pero sigue siendo una proporción sustancial.
Mismos precios por token, costos reales potencialmente mucho más altos
Los precios se mantienen en USD 5 por millón de tokens de entrada y USD 25 por millón de tokens de salida. Sin embargo, Opus 4.7 usa un nuevo tokenizador que puede mapear el mismo texto en hasta 1.35 veces más tokens. El modelo también genera más tokens de salida en niveles de esfuerzo más altos. En la práctica, el costo por solicitud puede aumentar significativamente a pesar de que los precios por token permanecen sin cambios.
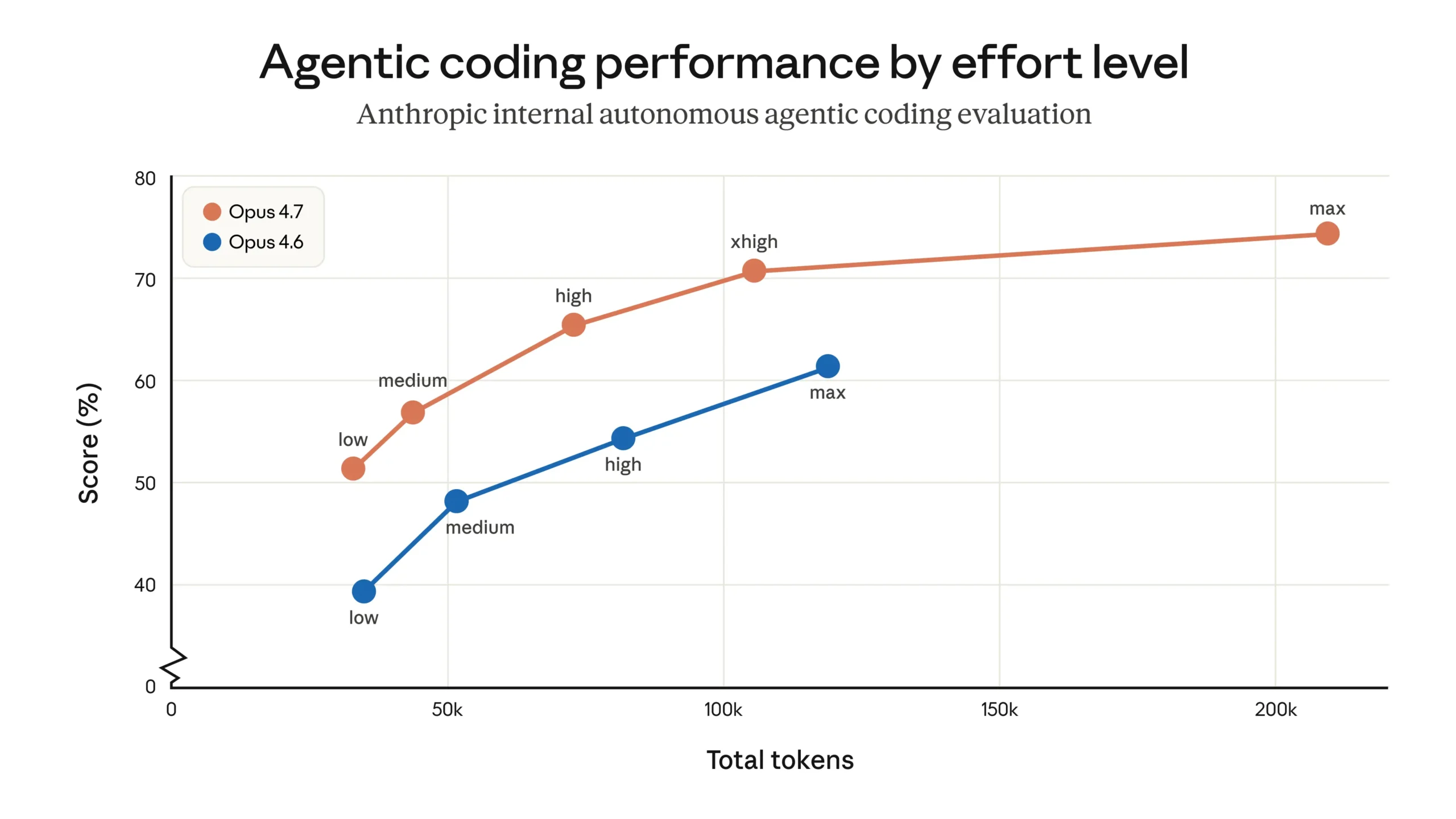
Un nuevo nivel de esfuerzo llamado "xhigh" se ubica entre "high" y "max". Claude Code también recibe un nuevo comando "/ultrareview" para revisiones de código dedicadas y un "Modo Automático" expandido para usuarios Max, donde Claude toma decisiones por su cuenta. Opus 4.7 está disponible a través de la API de Claude, Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry.
Más detalles y consejos están disponibles en la guía de migración para Opus 4.7.
Noticias de IA sin el hype – Curadas por humanos
Suscríbete a THE DECODER para una lectura sin publicidad, un boletín semanal de IA, nuestro informe exclusivo de frontera "AI Radar" seis veces al año, acceso completo al archivo y acceso a nuestra sección de comentarios.
Noticias de IA sin el hype Curadas por humanos.
- Más del 16% de descuento.
- Lee sin distracciones – sin anuncios de Google.
- Acceso a comentarios y discusiones de la comunidad.
- Boletín semanal de IA.
- 6 veces al año: “AI Radar” – inmersiones profundas en temas clave de IA.
- Hasta 25 % de descuento en eventos en línea de KI Pro.
- Acceso a nuestro archivo completo de diez años.
- Obtén las últimas noticias de IA de The Decoder.
Vía The Decoder.