
La tesis circula desde hace meses en el podcast Unsupervised Learning de Latent Space: los agentes de programación están "rompiendo el cerco". Una semana tranquila en términos de lanzamientos disruptivos sirvió para confirmarlo: tanto Claude como Codex tuvieron movimientos significativos, y Claude generalmente sigue ganando la batalla por la atención como viene ocurriendo hace un tiempo.
¿Qué cambió en Codex esta semana?
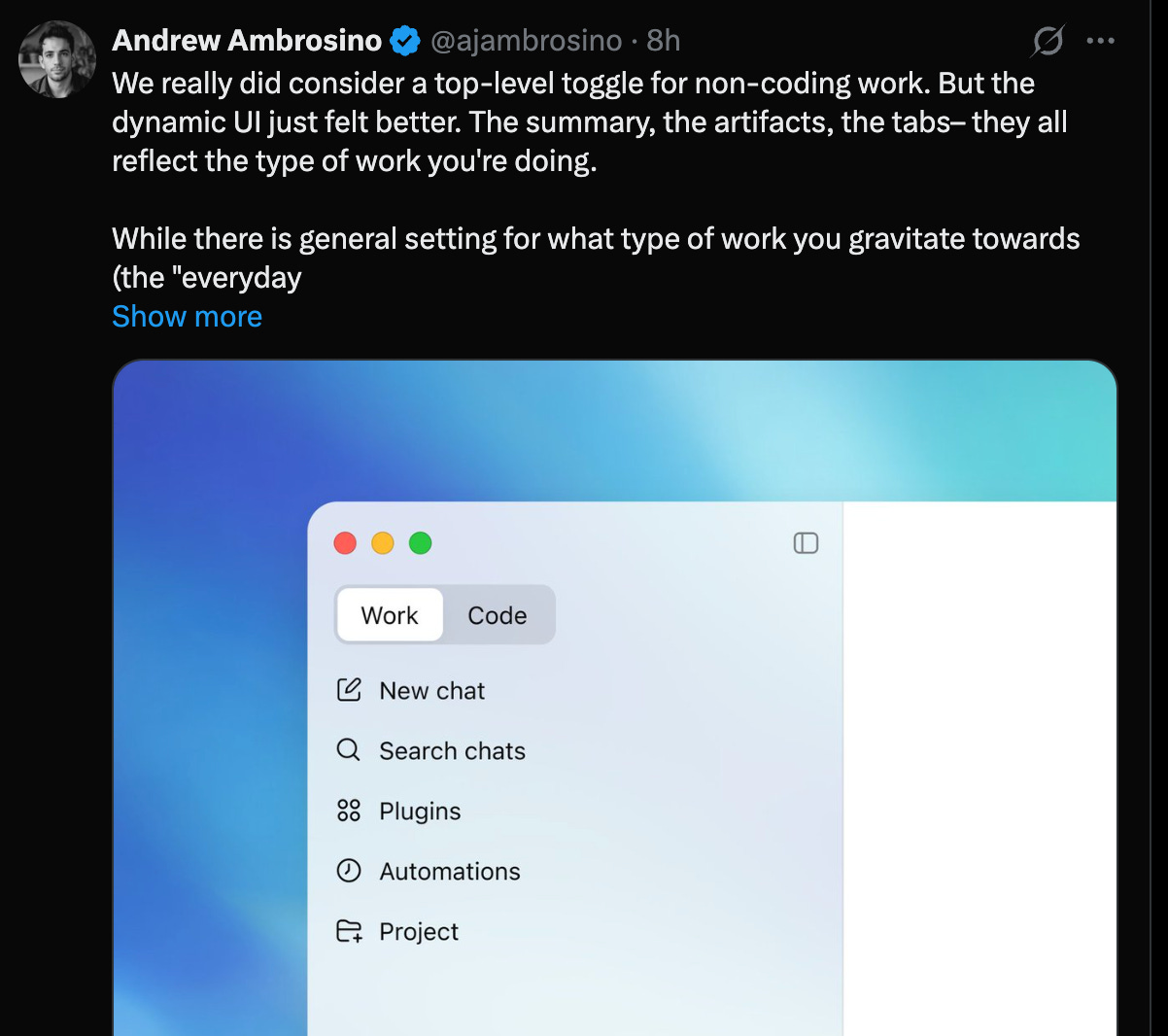
El gran update fue Codex for Work, una landing que reposiciona a Codex como agente para trabajo de conocimiento, no solo programación. La movida sigue al esfuerzo de la semana anterior por convertir a Codex en la presunta SuperApp de OpenAI.
Pero no es solo un cambio cosmético. La última versión de Codex incorpora:
- Computer Use Agent (CUA) un 42% más rápido.
- Browser responsivo.
- Comandos /chronicle y /goal, descrito como "la versión OpenAI del Ralph loop".
- Onboarding que invita a conectarse a la suite Microsoft, Google y Salesforce.
- Planning UI estilo Cowork y un editor de archivos in-app para documentos de MS Office.
El equipo de OpenAI fue explícito sobre el reposicionamiento. Tibo lo resumió como "Codex ya disponible para no programadores". Greg Brockman aportó: "Codex es para todos, para cualquier tarea hecha con un computador". Sam Altman cerró la jugada con un mensaje directo:
"Gran upgrade para Codex hoy. Pruébenlo para trabajo de computador no relacionado con código", escribió Altman.
La elección de UI dinámica es notable: el equipo rechazó explícitamente el toggle estilo Cowork de Claude y prefirió que el agente decida cómo presentar la experiencia.
¿Qué hizo Anthropic en paralelo?
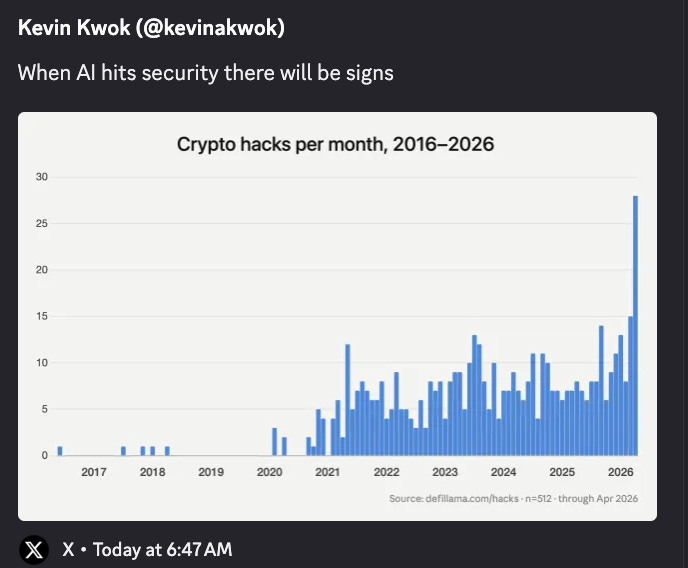
Sobre el telón de fondo de un aumento en vulnerabilidades de seguridad y el meta-mythos en torno a Mythos, Anthropic lanzó Claude Security, una herramienta de revisión de código para defensores.
Pero la noticia mayor de la semana, según el análisis de Latent Space, fue el soporte para herramientas creativas como Blender, Autodesk, Adobe Creative Cloud, Ableton, Splice y Canva Affinity, entre otras.
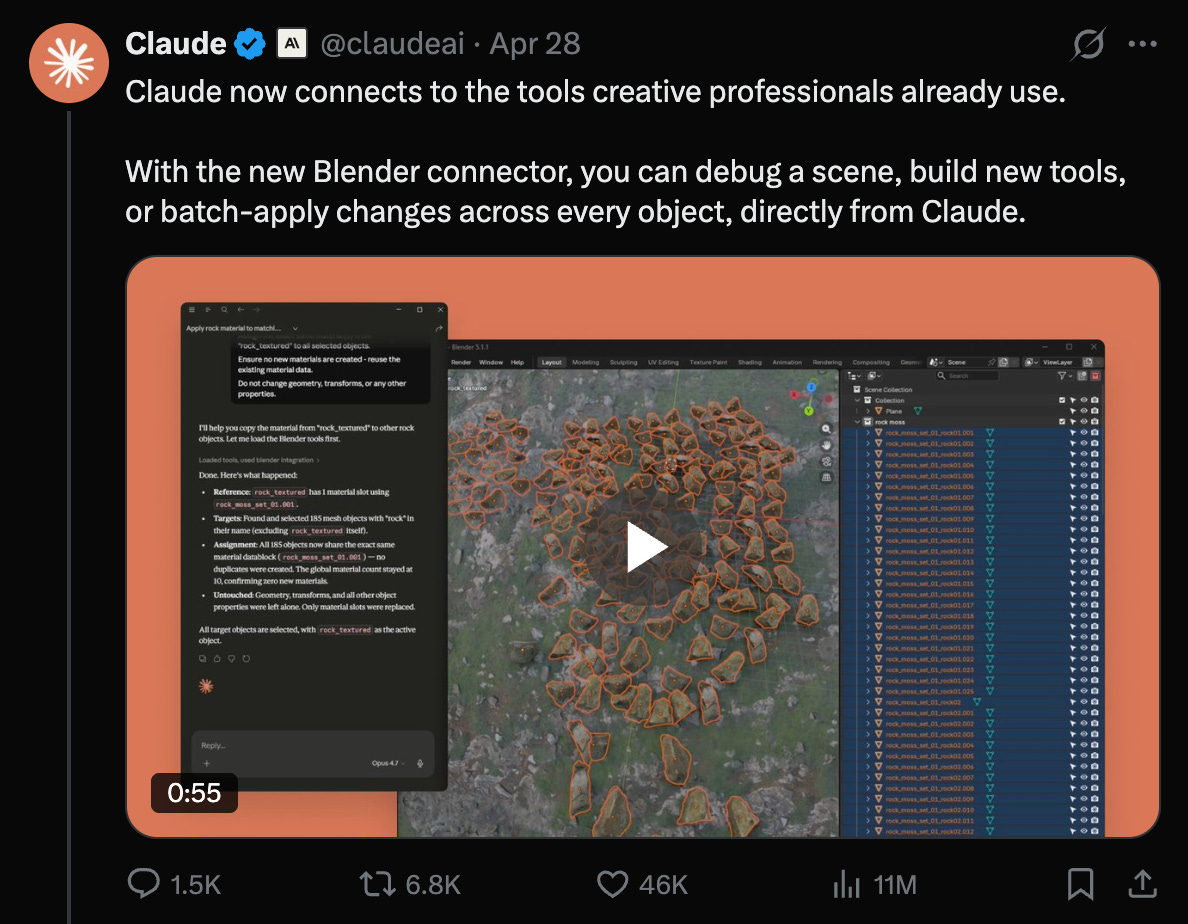
La división de tareas que sugiere la semana es clara: Codex se posiciona como agente de trabajo de conocimiento (oficinas, planillas, presentaciones) y Claude se posiciona como agente creativo (modelado 3D, audio, diseño).
¿Cómo se ve GPT-5.5 en evaluaciones de ciberseguridad?
GPT-5.5 entró al primer pelotón en tareas cibernéticas de horizonte largo. El AI Security Institute del Reino Unido reportó que GPT-5.5 fue el segundo modelo en completar de extremo a extremo una de sus simulaciones de ataque cibernético multipaso, con paridad cercana a Claude Mythos Preview en este eval:
- @scaling01 reportó 71,4% de pass rate promedio para GPT-5.5 frente a 68,6% de Mythos.
- @cryps1s destacó que GPT-5.5 resolvió la cadena TLO en 2 de 10 intentos, contra 3 de 10 de Mythos.
- @polynoamial enfatizó que el rendimiento seguía mejorando incluso pasados los 100 millones de tokens de presupuesto de inferencia, sin saturación obvia.
El dato cambia materialmente el relato anterior, según el cual Anthropic tenía una ventaja única en automatización ofensiva. OpenAI acompañó el momento con un release de seguridad del lado producto: Advanced Account Security para ChatGPT, con login resistente a phishing y recuperación endurecida.
En paralelo, Artificial Analysis reportó que GPT-5.5 Pro se convirtió en SOTA marginal sobre CritPt frente a GPT-5.4 Pro, pero el dato relevante no fue la puntuación sino que el salto se logró con costo y consumo de tokens 60% menor en ese eval frontera-científico.
¿Quién lidera entre los modelos open-weight?
Qwen3.6 27B luce como el lanzamiento open-weight más importante del día. Artificial Analysis lo posicionó como nuevo líder open-weights bajo 150B parámetros con un Intelligence Index de 46, por delante de Gemma 4 31B y variantes Qwen previas. Detalles clave:
- Licencia Apache 2.0.
- Contexto 262K.
- Multimodal nativo en input.
- Pesos BF16 que caben en una sola H100.
- El acompañante 35B A3B MoE marcó 43, el modelo open más fuerte alrededor de 3B parámetros activos.
El tradeoff es la inferencia cara: AA estima que Qwen3.6 27B usó ~144M tokens de output en la suite, aproximadamente 21× el costo de correr Gemma 4 31B. Aun así, en capacidad-por-tamaño es un paso notable.
Hy3-preview de Tencent es competitivo pero no líder de clase. Artificial Analysis lo describió como un MoE de 295B totales / 21B activos con 256K de contexto y licencia comunitaria de uso comercial restringido. Sacó 42 en el Intelligence Index, detrás de Qwen3.6 27B, DeepSeek V4 Flash y GLM-5.1. El punto bright spot fue CritPt, donde igualó a GLM-5.1 con 4,6%.
Grok 4.3 de xAI mejoró fuerte en benchmarks agénticos y bajó el precio. Artificial Analysis lo midió en 53 puntos del Intelligence Index, cuatro arriba de Grok 4.20 v2, con un salto importante en GDPval-AA hasta 1500 Elo. AA reportó precios aproximadamente 40% menores en input y 60% menores en output respecto a la versión anterior. Sigue lejos de GPT-5.5 en GDPval-AA, pero es una mejora real de sistemas y post-training, no un retoque cosmético.
Ling 2.6 1T de Ant Group apunta a costo-eficiencia, no a frontera. Artificial Analysis lo posicionó como modelo no-razonante de 1T parámetros con score 34, números decentes en GPQA y HLE, y un costo de corrida de benchmark notablemente bajo (alrededor de USD 95). El caveat es la confiabilidad: AA reportó una tasa de alucinación de 92% en AA-Omniscience.
¿Qué sigue con DeepSeek y la escala de pretraining?
La dirección multimodal de DeepSeek aparece estrechamente acoplada a agentes de uso de computadora. @nrehiew_ destacó que DeepSeek entrena visión dentro de V4-Flash haciendo que el modelo emita directamente bounding boxes y coordenadas de puntos durante el razonamiento, interpretándolo como diseño orientado a computer-use más que como trabajo VLM genérico. Una segunda observación argumenta que las "visual primitives" del paper mapean directo a browser y computer use (fuente). El framing concuerda con @teortaxesTex, que apunta a que DeepSeek estaría integrando los pesos de visión de vuelta a la línea principal V4, en lugar de liberar un "V4-Flash-Vision" separado.
La desaparición del repositorio se volvió historia propia. Tras el release, varios observadores notaron que el repo "Thinking with Visual Primitives" se evaporó, incluidos @teortaxesTex y @arjunkocher. No emergió explicación clara, pero la eliminación atrajo más atención porque el trabajo sugería una receta concreta para razonamiento visual y grounding en GUI.
Por último, la conversación sobre escala apunta a recuentos de tokens muy grandes para pretraining frontera. @teortaxesTex argumentó que más de 100T tokens ya no es inusual en modelos frontera y estimó un hipotético DeepSeek V4 de 100T tokens como "V4 + 2 epochs adicionales". @nrehiew_ hizo una estimación de servilleta con ~150T tokens y ~9e25 FLOPs de pretraining para un modelo ~100B activo, sugiriendo una corrida factible en aproximadamente 14 días sobre un cluster tipo 100K GB200 de OpenAI a MFU conservadora. Son ejercicios especulativos, pero útiles como calibración de qué significa "frontera" hoy.



