[AINews] Anthropic Claude Opus 4.7: literalmente un paso mejor que 4.6 en cada dimensión
El nuevo modelo SOTA reafirma su dominio.
Las mañanas de los jueves suelen estar reservadas para lanzamientos de IA de alto perfil y, aunque OpenAI realizó un esfuerzo valiente con GPT-Rosalind y The New New Codex (incluyendo el asombroso computer use), hoy no hubo dudas sobre quién se llevaría la noticia principal. Si revisan con atención las ediciones anteriores de AINews, habrán notado los rumores sobre esto durante al menos la última semana, pero el lanzamiento de Claude Opus 4.7 de hoy superó ligeramente incluso esas expectativas.
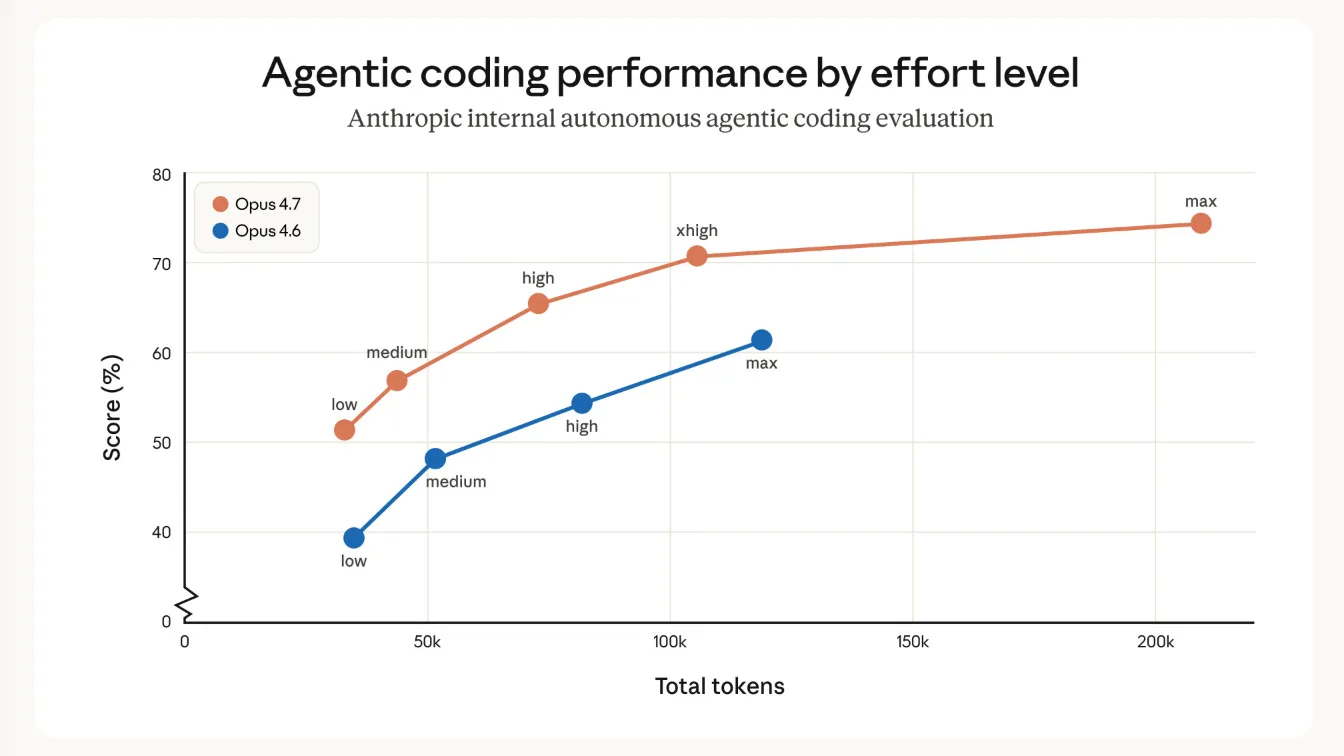
El gráfico clave para entender este avance es el siguiente:
Básicamente, el nivel 4.7-low es estrictamente mejor que el 4.6-medium; el 4.7-medium es superior al 4.6-high; el 4.7-high es ahora mejor que el 4.6-max, y se ha introducido un nuevo nivel de esfuerzo xhigh que Claude Code utiliza por defecto. Aunque Anthropic señala que el nuevo tokenizer (¿un nuevo pretrain?) puede causar hasta un 35% más de uso de tokens, la eficiencia de razonamiento general ha mejorado tanto que el uso total de tokens SIGUE siendo hasta un 50% menor que el de sus equivalentes anteriores. La verdadera prueba será determinar si el Claude Code predeterminado, que ahora es 11 puntos superior en SWE-Bench Pro, ofrece un rendimiento notablemente mejor en sus propios casos de uso.
La otra capacidad destacada que, literalmente, debe verse para creerse, es la "visión sustancialmente mejorada". Opus 4.7 posee una mejor visión para imágenes de alta resolución: puede aceptar imágenes de hasta 2,576 píxeles en su borde más largo (~3.75 megapíxeles), lo que representa más del triple que los modelos Claude anteriores. Esto abre una gran cantidad de usos multimodales que dependen de detalles visuales finos: agentes de computer-use que leen capturas de pantalla densas, extracción de datos de diagramas complejos y trabajos que requieren referencias con precisión de píxel. Más detalles se encuentran en el resumen de temas específicos a continuación.
Noticias de IA del 14/04/2026 al 16/04/2026. Revisamos 12 subreddits, 544 cuentas de Twitter y ningún Discord adicional. El sitio web de AINews permite buscar en todas las ediciones pasadas. Como recordatorio, AINews es ahora una sección de Latent Space. ¡Pueden optar por suscribirse o cancelar las frecuencias de correo electrónico!
Historia Principal: Claude Opus 4.7
Anthropic lanzó oficialmente Claude Opus 4.7 como su nuevo modelo Opus de nivel superior, posicionándolo como una herramienta superior en tareas de larga duración, programación, seguimiento de instrucciones, autoverificación, computer use y trabajo de conocimiento en comparación con Opus 4.6. Todo esto manteniendo los precios de lista sin cambios en $5 / $25 por cada millón de tokens de entrada/salida, según los resúmenes de usuarios y la discusión del lanzamiento @claudeai, @kimmonismus. El lanzamiento provocó una discusión técnica inusualmente activa en torno a las ganancias en benchmarks, un nuevo tokenizer, soporte para mayor resolución de imagen, el nuevo nivel de razonamiento xhigh, las implicaciones en el costo de tokens y si Opus 4.7 es un sucesor directo de 4.6, un nuevo modelo base o un sistema parcialmente destilado "adyacente a Mythos".
Detalles del lanzamiento y cambios en el producto
Enfoque oficial. El discurso de lanzamiento de Anthropic enfatizó tres mejoras de comportamiento: mejor manejo de tareas de larga duración, un seguimiento de instrucciones más preciso y una autoverificación más sólida antes de responder @claudeai.
- La plataforma y la aplicación de Claude se reportaron como activas de inmediato @dejavucoder.
- Claude Code incluyó soporte desde el primer día y estableció
xhighcomo el nivel de esfuerzo predeterminado @_catwu, @_catwu.
- Anthropic también lanzó o destacó los presupuestos de tareas (task budgets) en beta pública,
/ultrareviewen Claude Code y un acceso más amplio al modo Auto para los usuarios de Claude Code Max @kimmonismus.
- Múltiples usuarios notaron un nuevo modo de razonamiento
xhigh, posicionado entrehighymax@scaling01, @scaling01.
- Cat Wu mencionó que Claude Code ahora utiliza
xhighde forma predeterminada para Opus 4.7 @_catwu.
Cambios en visión y computer use.
- Los resúmenes de usuarios informaron soporte para imágenes de hasta 2,576 px en el borde largo (~3.75 MP), descrito como 3 veces más grande que las entradas de imagen anteriores de Claude @kimmonismus.
- Alex Albert, empleado de Anthropic, destacó que ya no hay reducción de escala (downscaling) para imágenes de alta resolución y que el modelo tiene un mejor gusto en los resultados de UI, diapositivas y documentos @alexalbert__.
- Esto se vinculó repetidamente con un mejor desempeño en computer use y flujos de trabajo con gran cantidad de capturas de pantalla @dejavucoder, @omarsar0.
Tokenizer y economía de tokens.
- Varios observadores descubrieron que Opus 4.7 utiliza un tokenizer diferente al de la versión 4.6 @natolambert, @nrehiew_.
- Kimmonismus resumió la advertencia de Anthropic de que la misma entrada puede mapearse a 1.0–1.35 veces más tokens dependiendo del tipo de contenido @kimmonismus.
- Esto generó un debate sobre si 4.7 es efectivamente un nuevo modelo base, una continuación con cambio de tokenizer o algún tipo de puente de midtraining o destilación desde Mythos @natolambert, @stochasticchasm, @eliebakouch, @maximelabonne.
- Boris Cherny, empleado de Anthropic, dijo más tarde que aumentaron los límites para todos los suscriptores para compensar el incremento en el uso de tokens @bcherny, @bcherny.
Benchmarks y progreso medible
Ganancias reportadas en benchmarks vs Opus 4.6
Las cifras de lanzamiento más citadas provienen de capturas de pantalla de benchmarks y resúmenes compartidos por cuentas externas:
- SWE-bench Pro: 64.3%, con usuarios citando aproximadamente +11 puntos sobre Opus 4.6 @scaling01, @kimmonismus
- SWE-bench Verified: 87.6%, aproximadamente +7 puntos frente a 4.6 @scaling01, @scaling01
- TerminalBench 2.0: 69.4%, alrededor de +4 puntos @scaling01, @kimmonismus
- Razonamiento de documentos: 80.6%, frente al 57.1% según discusiones de terceros @scaling01, @llama_index
- GDPval-AA: 1753 Elo @scaling01, @ArtificialAnlys
- ARC-AGI-1: 92%; ARC-AGI-2: 75.83% según @scaling01
Artificial Analysis afirmó que Opus 4.7 se lanzó como el nuevo #1 en GDPval-AA, con una ventaja implícita de ~60% en enfrentamientos directos.
Vía Latent Space.


