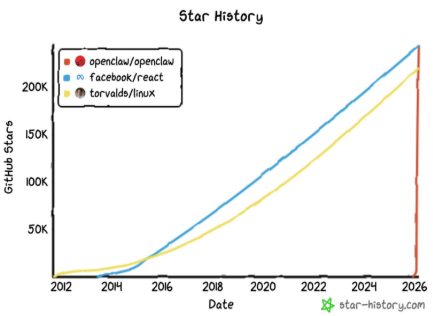
A inicios de 2026, el proyecto open source OpenClaw se convirtió en un fenómeno. En enero, su conteo de estrellas en GitHub superó las 100.000 mientras crecía el interés de los desarrolladores. Los dashboards comunitarios y las analíticas de tráfico mostraron más de 2 millones de visitantes en una sola semana. Para marzo, OpenClaw superó los 250.000 stars, sobrepasando a React para convertirse en el proyecto de software con más estrellas de GitHub en apenas 60 días.
Creado por Peter Steinberger, OpenClaw es un asistente de IA persistente y self-hosted, diseñado para correr localmente o en servidores privados. El proyecto llamó la atención por su accesibilidad y autonomía sin límites, ya que los usuarios podían desplegar un modelo de IA localmente sin depender de infraestructura cloud ni de APIs externas.
La mayoría de los agentes de IA actuales se activan con un prompt, completan una tarea definida y luego dejan de ejecutarse. Un agente autónomo de larga duración, o "claw", funciona distinto. Estos agentes corren persistentemente en segundo plano, completando tareas por sí mismos y elevando solo aquello que requiere una decisión humana. Operan sobre un heartbeat, es decir, a intervalos regulares revisan su lista de tareas, evalúan qué requiere acción y deciden actuar o esperar al próximo ciclo.
¿Qué riesgos abrió la adopción acelerada?
La rápida adopción de OpenClaw también encendió el debate. Investigadores de seguridad plantearon preocupaciones sobre cómo las herramientas IA self-hosted gestionan datos sensibles, autenticación y actualizaciones de modelos. Otros cuestionaron si los despliegues locales podían exponer a los usuarios a nuevos riesgos, desde instancias de servidor sin parchear hasta contribuciones maliciosas en forks comunitarios. Mientras contribuidores y mantenedores trabajaban para abordar estos problemas, el ascenso de OpenClaw motivó una conversación más amplia en el ecosistema de IA sobre los trade-offs entre apertura, privacidad y seguridad.
Para reforzar la seguridad y robustez del proyecto OpenClaw, Nvidia está colaborando con Steinberger y la comunidad de desarrolladores para abordar potenciales vulnerabilidades, según se detalla en una reciente publicación del blog de OpenClaw.
Nvidia aporta código y orientación enfocados en mejorar el aislamiento de modelos, gestionar mejor el acceso a datos locales y fortalecer los procesos de verificación de contribuciones de la comunidad. La meta es apoyar el momentum del proyecto contribuyendo experiencia en seguridad y sistemas de manera abierta y transparente, fortaleciendo el trabajo de la comunidad mientras se preserva la gobernanza independiente de OpenClaw.
Para hacer más seguros los agentes de larga duración para empresas, Nvidia también introdujo NVIDIA NemoClaw, una implementación de referencia que con un solo comando instala OpenClaw, el runtime seguro NVIDIA OpenShell y los modelos abiertos NVIDIA Nemotron, con configuraciones por defecto endurecidas para redes, acceso a datos y seguridad. NemoClaw sirve de plano para que las organizaciones desplieguen "claws" con mayor seguridad.
La demanda de inferencia se multiplica con cada ola de IA
La IA atravesó cuatro fases, y el tiempo entre cada una se acorta. La IA predictiva tomó años en hacerse mainstream. La IA generativa avanzó más rápido. La IA de razonamiento llegó aún más rápido. La IA autónoma, la ola que representa OpenClaw, marca un ritmo todavía más acelerado.
Lo que se acumula con cada ola es la demanda de inferencia. La IA generativa aumentó el uso de tokens respecto a la IA predictiva. La IA de razonamiento lo aumentó otras 100 veces. Los agentes autónomos, que corren continuamente y actúan en horizontes de tiempo largos, elevan la demanda de inferencia otras 1.000 veces por sobre la IA de razonamiento. Cada ola multiplica la computación requerida.

Este aumento del uso de tokens permite a las organizaciones acelerar su productividad por órdenes de magnitud. Por ejemplo, los agentes de larga duración pueden ayudar a investigadores a resolver un problema durante la noche, iterar sobre un diseño en miles de configuraciones, o monitorear sistemas y elevar solo las anomalías que requieran juicio humano, liberando jornadas para tareas de mayor valor.
¿Cuándo conviene desplegar un "claw"?
Si bien la IA generativa se volvió un recurso habitual para tareas bajo demanda, hay escenarios específicos donde el "heartbeat" persistente de un claw ofrece ventajas distintivas. Determinar cuándo pasar de una IA estándar basada en prompts a un agente de larga duración suele depender de la naturaleza del flujo de trabajo:
- De "bajo demanda" a "siempre activo": aunque los modelos estándar son excelentes para consultas inmediatas activadas por humanos, los claws suelen adaptarse mejor a tareas que requieren monitoreo continuo en segundo plano o chequeos periódicos sin un inicio manual.
- Gestión de loops de alta iteración: para problemas complejos, como probar miles de combinaciones químicas o simular pruebas de estrés de infraestructura, un claw puede manejar el volumen de iteraciones que de otro modo se vería frenado por la intervención humana.
- Pasar de sugerencias a acciones: en muchos flujos, la IA estándar se usa para entregar información o borradores. Un claw se considera cuando la meta es que la IA pase a la fase de ejecución, interactuando con APIs, actualizando bases de datos o gestionando archivos en horizontes largos.
- Optimización de recursos: para tareas de razonamiento intensivo en tokens, desplegar un claw local en hardware dedicado como NVIDIA DGX Spark permite costos más predecibles y privacidad de datos en comparación con llamadas frecuentes a APIs cloud.
¿Cómo están usando las organizaciones agentes autónomos persistentes?
Las aplicaciones prácticas de agentes autónomos de larga duración cubren todas las funciones y sectores.
En servicios financieros, los agentes monitorean continuamente sistemas de trading y feeds regulatorios, marcando eventos materiales antes de la revisión matutina. En descubrimiento de fármacos, los agentes barren nueva literatura científica, extrayendo hallazgos relevantes y actualizando bases de datos internas en tiempo real sin intervención del investigador, un proceso que antes tomaba semanas.
En ingeniería y manufactura, los agentes aceleran el análisis de problemas testeando miles de combinaciones de parámetros, rankeando resultados y marcando las configuraciones que vale la pena examinar, todo durante la noche.
En operaciones IT, los agentes diagnostican incidentes de infraestructura, aplican remediaciones conocidas y escalan solo los problemas inéditos, comprimiendo el tiempo medio de resolución de horas a minutos. En ServiceNow, los especialistas en IA que aprovechan los modelos Apriel y NVIDIA Nemotron pueden resolver el 90% de los tickets de manera autónoma.
¿Cómo se despliegan estos agentes de manera responsable?
Los agentes autónomos son ejecutivos. Pueden enviar comunicaciones, escribir archivos, llamar APIs y actualizar sistemas en vivo. Cuando un agente produce una acción incorrecta, hay consecuencias reales. Establecer correctamente el marco de accountability desde el inicio es esencial, y las organizaciones que despliegan agentes autónomos en producción deben tratar la gobernanza como un requisito de primer orden.
Las organizaciones necesitan ver qué hacen sus agentes, inspeccionar su razonamiento en cada paso, auditar sus acciones e intervenir cuando sea necesario. Las que despliegan agentes de manera responsable se enfocan en tres prioridades:
- Un framework abierto y auditable: NemoClaw se construye sobre el código base de OpenClaw, licenciado bajo MIT, lo que significa que las organizaciones poseen toda la infraestructura del agente. Pueden leer, hacer fork y modificar cada capa del despliegue. Esa transparencia permite a los equipos entender y controlar el sistema a nivel de código. Correr modelos open source como NVIDIA Nemotron localmente mantiene cargas sensibles (registros de pacientes, documentos legales, transacciones financieras, investigación propietaria) dentro del entorno de la organización.
- Asegurar el runtime: NemoClaw corre los agentes dentro de OpenShell, un entorno sandbox que define con precisión qué puede y qué no puede hacer el agente, imponiendo límites de permisos claros desde el inicio.
- Cómputo local: los supercomputadores NVIDIA DGX Spark entregan rendimiento GPU de clase data-center en formato de escritorio, pensado para inferencia local continua siempre activa, con hosting local del modelo y datos que permanecen dentro del entorno de la organización. Los sistemas NVIDIA DGX Station escalan esa capacidad para equipos que corren múltiples agentes simultáneamente en cargas complejas y sostenidas.
Las organizaciones que están definiendo qué hacen los agentes autónomos en la práctica están acumulando algo valioso, esto es: meses de aprendizaje operacional en vivo, marcos de gobernanza desarrollados a partir de cargas reales y agentes que han absorbido el contexto institucional que los hace genuinamente útiles. Ese fundamento solo se profundizará con el tiempo.
¿Vale la pena vs. agentes cloud como AutoGPT o LangGraph?
Para equipos en LATAM evaluando alternativas, la diferencia operativa de NemoClaw frente a stacks cloud-first como AutoGPT o LangGraph se concreta en tres ejes: costo de inferencia (tokens locales en una DGX Spark de USD 3.999 amortiza rápido para cargas continuas vs. la facturación variable de OpenAI/Anthropic), residencia de datos (relevante para fintech y salud bajo Ley 19.628 chilena de protección de datos personales) y latencia (sin round-trip a us-east). El paquete OpenClaw + OpenShell + Nemotron, todo MIT/Open Model License, lo posiciona como referencia para gobiernos y banca regional que necesiten un agente persistente sin dependencia de proveedor único.
¿Cómo empezar con NemoClaw?
Hay un tutorial paso a paso sobre cómo construir un agente IA más seguro con NemoClaw sobre NVIDIA DGX Spark. NemoClaw está disponible en GitHub, y hay una comunidad de desarrolladores en Discord construyendo con NemoClaw usando NVIDIA Nemotron 3 Super y Telegram sobre DGX Spark.