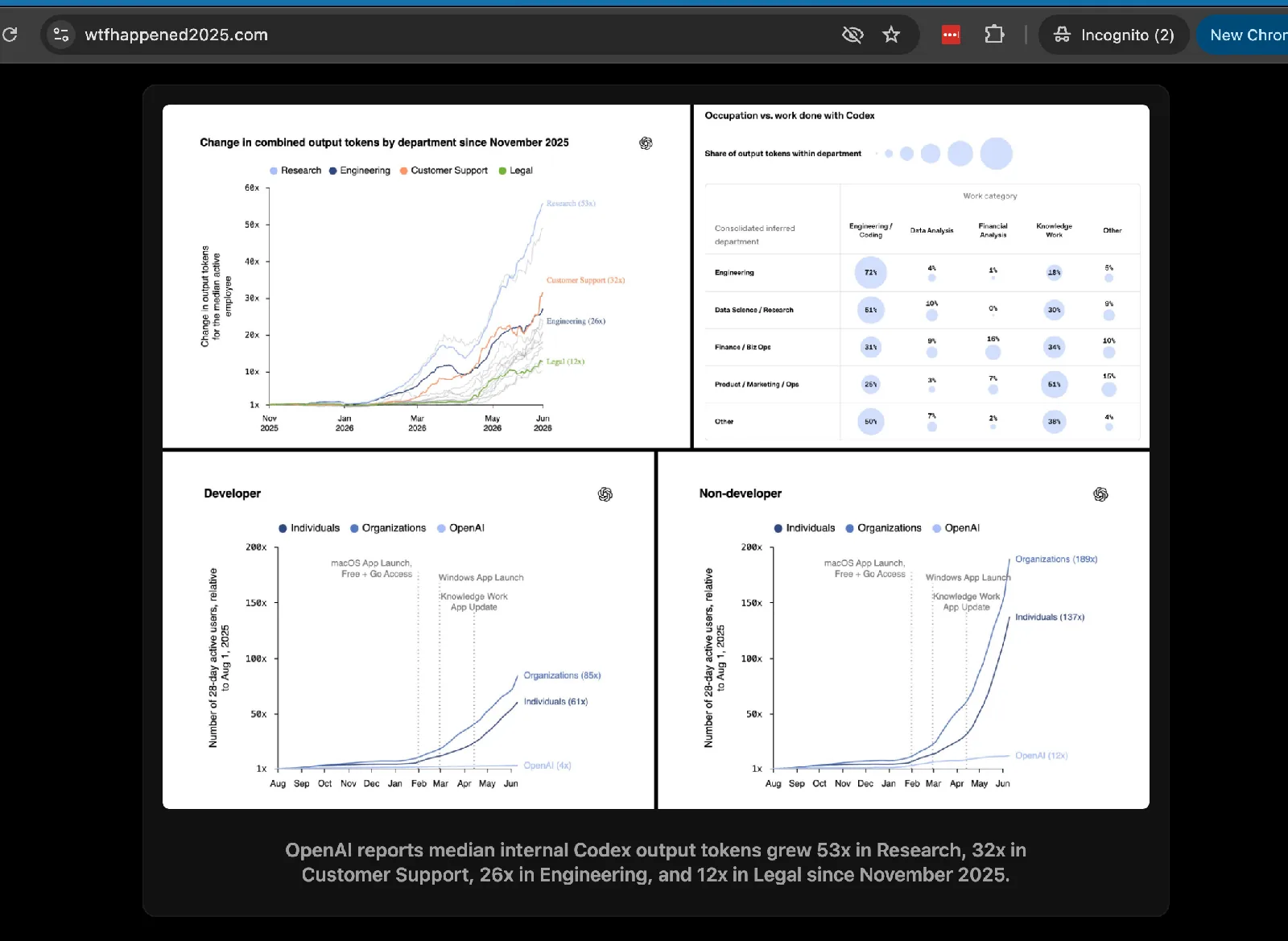
Sumá esto al archivo WTF Happened in 2025?: el equipo de OpenAI Economic Research reportó que el consumo de tokens en todo lo que no es codificación está explotando. Hasta agosto de 2025, el trabajador promedio de OpenAI gastaba menos del 10% de sus tokens en Codex. En los últimos seis meses, el uso se profundizó e intensificó.
Entre los usuarios internos activos, el cambio en tokens de salida combinados subió fuerte en todos los departamentos. Investigación vio el mayor salto: a junio de 2026, la mediana de uso fue 56 veces más alta que en noviembre de 2025. Soporte al Cliente subió 32 veces e Ingeniería subió 27 veces, mientras que Legal creció de forma más gradual pero igual alcanzó 13 veces su nivel de noviembre.
Vale como baseline contra las preocupaciones de Tokenmaxxing: los empleados de OpenAI siempre tuvieron acceso ilimitado y, aun así, hasta fines de 2025 estaban subutilizando claramente la IA.
¿Qué muestra el contexto agéntico de la industria?
El reporte de Codex no es aislado. La misma semana convergieron varios anuncios que apuntalan la lectura de que los agentes están dejando atrás la fase chat. Google llevó computer use al nivel de capacidad nativa en Gemini 3.5 Flash a través de browser, desktop y mobile, con confirmación explícita del usuario para acciones sensibles y stopping automático de tareas. Sail se lanzó con USD 80 millones levantados para inferencia barata y sandboxes orientados a agentes que corran días o semanas, prometiendo "10x más inteligencia por dólar" para cargas pacientes.
LangChain marcó la distinción operativa: usar chat de propósito general cuando el trabajo termina en una respuesta, y agentes especializados cuando hay forma repetible y contexto durable.
¿Cuán confiable es el dato interno?
Los voceros que comentaron el reporte (gdb, reach_vb, eliebakouch) coinciden en que el crecimiento en consumo interno de tokens, especialmente en equipos de investigación, expone patrones como skills y agentes concurrentes. El takeaway práctico es menos "los agentes son mágicos" y más que la adopción real emerge donde las organizaciones pueden sostener loops de revisión, tooling y workflows persistentes.
Lo importante es entender qué mide el indicador: mediana de tokens de salida, no cantidad de tareas ni tasa de éxito. Un agente que escribe 50.000 tokens para resolver mal una tarea infla la métrica igual que uno que escribe 50.000 tokens y la resuelve bien. Sin denominador de outcomes, el 56x dice más sobre el cambio en el modo de trabajo que sobre la productividad pura.
¿Cómo se compara con la tendencia open source?
Los datos internos de OpenAI coexisten con un ecosistema abierto que se mueve fuerte. GLM-5.2 Max de Z.ai alcanzó 1.595 en Code Arena: Frontend, superando a Opus 4.8 y acortando la distancia con Claude Fable 5. Databricks empujó la velocidad de GLM-5.2 a 392 tok/s en Artificial Analysis, contra los 201 tok/s previos sobre H200, gracias a hardware B300 más decodificación especulativa y kernels optimizados.
El modelo Ornith-1.0 debutó como familia con licencia MIT para coding agentic en variantes 9B densa, 31B densa, 35B MoE y 397B MoE, post-entrenadas sobre Gemma 4 y Qwen3.5. Sus scores incluyen Terminal-Bench 2.1: 77,5, SWE-Bench Verified: 82,4, SWE-Bench Pro: 62,2 y ClawEval: 77,1. Liquid AI lanzó LFM2.5-230M, un modelo ultra pequeño orientado a tool use de baja latencia en robótica y e-commerce, con soporte day-0 en vLLM y SGLang, y un trabajo de WebGPU que lo lleva a ~1.400 tok/s locales.
¿Qué cambia para los equipos LatAm?
Para integradores chilenos y latinoamericanos que estén evaluando agentes, la lección del reporte interno de OpenAI es operativa: la rampa de adopción real tarda meses incluso con acceso ilimitado al modelo. Si un equipo recién empieza a desplegar Claude Code, Codex o GitHub Copilot, hay que estimar entre 6 y 9 meses para que la mediana de uso por persona se estabilice. Los gates no son técnicos sino de proceso: definir loops de revisión, otorgar permisos a herramientas y código, y normalizar la delegación asincrónica como práctica.
Para quienes operan en latencia crítica, el dato relevante es que LFM2.5-230M corriendo en WebGPU local entrega ~1.400 tok/s en hardware de gama media, lo que abre la puerta a uses casos embebidos y tooling robótico sin depender de inferencia en la nube.
¿Qué pasa con el control de acceso y la distillation?
En paralelo a estos números, el día tuvo un episodio de rumor sobre Claude Fable 5: pareció reaparecer en Anthropic pero quedó descartado como artefacto de UI. Sam McAllister confirmó que Anthropic estaba sirviendo exactamente 0 tráfico a Fable 5, y The Amol Avasare añadió que no había tráfico Fable/Mythos, probablemente solo un bug de interfaz o trolling. El episodio funciona como recordatorio de que la opacidad sobre qué modelos están realmente desplegados sigue siendo un punto sensible para los usuarios de plataformas cerradas.