
Las telcos en todo el mundo estan construyendo fabricas de IA soberanas basadas en la arquitectura de referencia NVIDIA Cloud Partner (NCP). Eso le entrega a gobiernos, empresas y startups acceso a infraestructura de IA dentro del propio pais, con los controles, la confianza y el rendimiento adecuados. Pero la infraestructura por si sola no alcanza para llegar a servicios empresariales de IA de alto margen y listos para produccion.
El tamaño de los modelos y las cargas de razonamiento sigue creciendo, lo que sube los tokens por request, mientras que cada nueva generacion de computo acelerado baja el costo por token. Juntas, estas tendencias hacen mas valioso empujar la economia de la IA hacia arriba en el stack: pasar de vender horas-GPU a entregar servicios de IA medidos y facturados en tokens.
Al mismo tiempo, las empresas no quieren administrar clusters, runtimes o pesos de modelos. Quieren aplicaciones y APIs listas para produccion, con desempeño predecible, medidas por consumo de tokens y respaldadas por SLAs atados a metricas IA-nativas como tokens por segundo, time-to-first-token (TTFT) y latencia end-to-end.
¿Como se construye el stack de IA de una telco?
La IA puede entenderse como una torta de 5 capas: energia, chips, infraestructura, modelos y aplicaciones. Las fabricas soberanas de telcos se posan sobre las capas de energia y chips, y anclan la capa de infraestructura: proveen computo acelerado NVIDIA, networking y almacenamiento que pueden hospedar modelos y aplicaciones de forma segura.
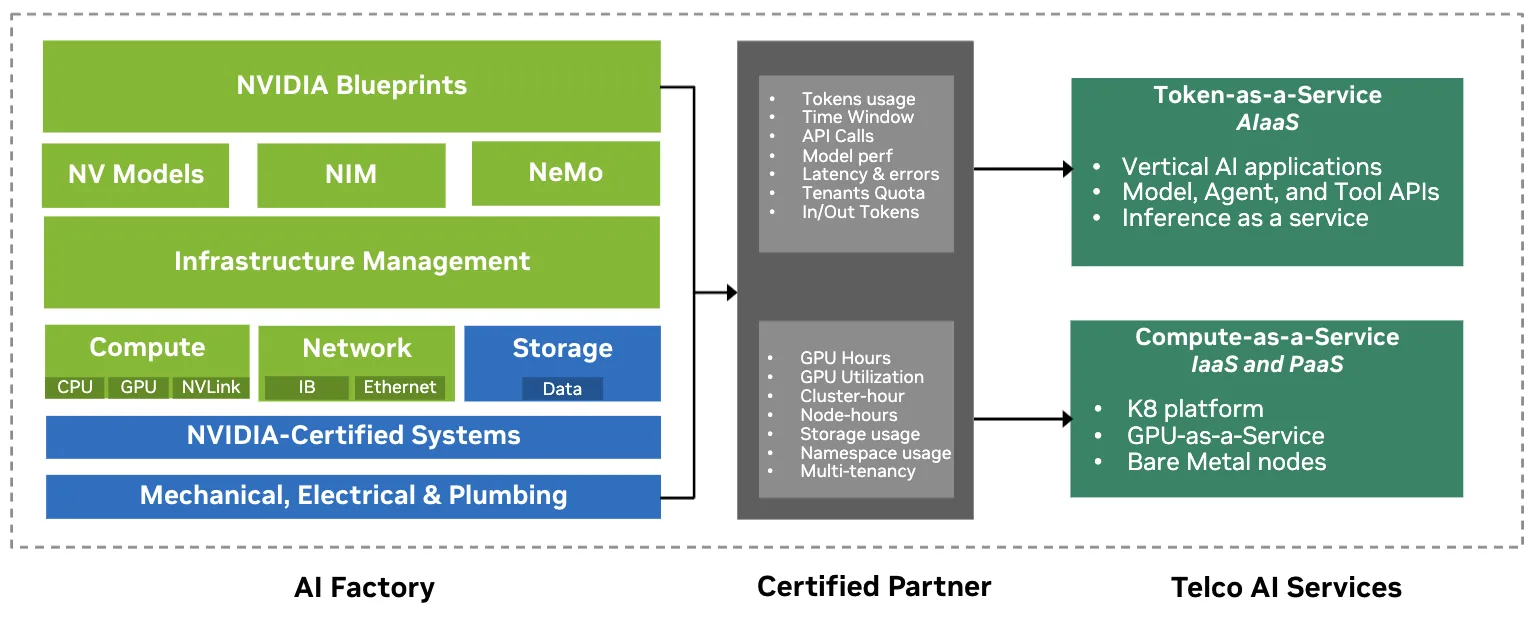
Las fabricas de IA de telcos parten con infraestructura certificada NVIDIA y una eleccion de partners de software que definen la postura economica y regulatoria de la plataforma. Esta capa fundacional establece el costo del computo como servicio, fuerza donde pueden residir los datos y controla que tenants pueden correr que cargas en un ambiente compartido.
En la practica, convierte la capacidad cruda de GPU en computo multi-tenant seguro que puede exponerse como servicios. Su estructura de costos y su huella marcan la linea base del costo por token a medida que las telcos suben en el stack.
¿Que es Compute-as-a-Service?
Compute-as-a-Service (CaaS) es la forma en que las telcos monetizan las capas de energia, chips e infraestructura de la torta de 5 capas, exponiendo sistemas certificados NVIDIA, CPUs, GPUs, NVLink, InfiniBand o Ethernet de alta velocidad y almacenamiento como GPU/Infrastructure-as-a-Service (IaaS) que los clientes rentan por hora, similar a las instancias cloud tradicionales.
Sobre eso, una capa de plataforma basada en Kubernetes convierte esa capacidad cruda en un ambiente manejado con clusters multi-tenant, namespaces y planificacion de GPU. Los desarrolladores pueden desplegar containers y runtimes de inferencia mientras se les factura principalmente por GPU-horas, node-horas y storage.
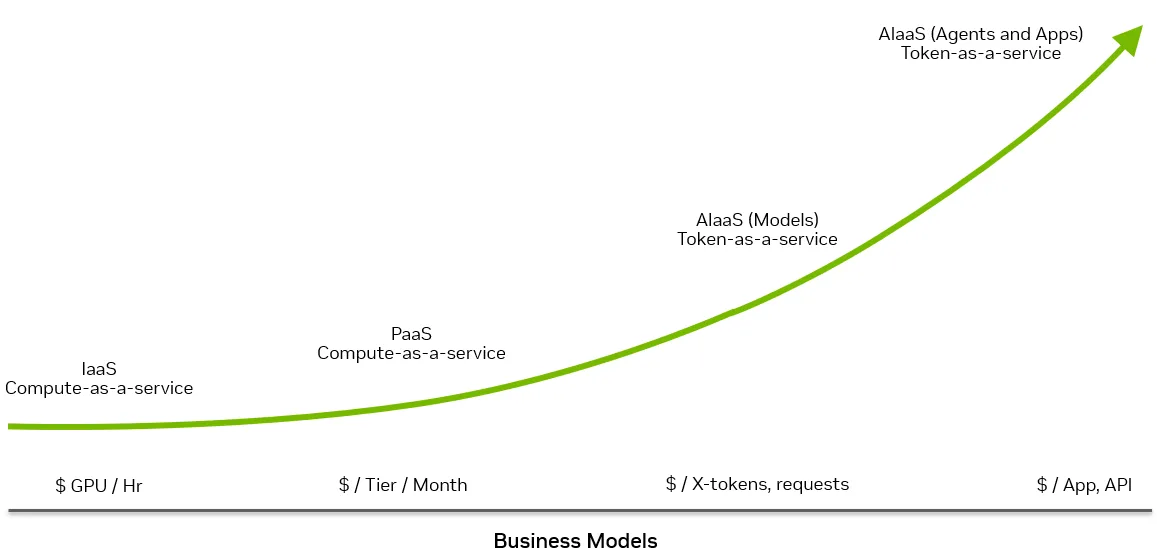
Este nivel es esencial para flexibilidad, control y soberania, pero deja el negocio anclado en un modelo de GPU-por-hora. El verdadero giro economico ocurre cuando las telcos agregan modelos y aplicaciones medidos en tokens encima.
¿Como funciona Token-as-a-Service?
Token-as-a-Service (TaaS) lleva a las telcos hacia las capas de modelos y aplicaciones de la torta de 5 capas, donde el valor se mide en tokens, llamadas a API y workflows, no en GPU-horas. En esta capa, la capacidad de GPU de la fabrica de IA se empaqueta en productos que se miden, facturan y gobiernan en esas mismas unidades.
Las telcos suelen empezar con un portafolio acotado de servicios medidos en tokens, impulsados por modelos open source como NVIDIA Nemotron, NVIDIA NIM y blueprints:
- Aplicaciones IA verticales (por ejemplo, copilotos de atencion al cliente o asistentes de conocimiento adaptados a idiomas y regulaciones locales)
- APIs de modelos y herramientas para texto, vision, voz y agentes
- Endpoints de Inference-as-a-Service para modelos fine-tuneados y de dominio especifico
Los clientes integran estos servicios via APIs y pagan en unidades que matchean como su negocio consume IA: tokens, requests o workflows, en vez de metricas opacas de infraestructura. Los SLAs se desplazan en consecuencia: en lugar de uptime de servidores especificos, las empresas se enfocan en latencia, confiabilidad y calidad de respuesta a nivel de modelo o aplicacion.
Un AI developer studio es donde estos servicios medidos en tokens se diseñan, adaptan y operan. Cientificos de datos y desarrolladores usan NVIDIA NeMo para hacer fine-tuning de modelos foundation, los despliegan como endpoints NIM seguros y los conectan a pipelines de retrieval o workflows agenticos. Un AI marketplace se vuelve la vidriera que convierte esos assets en productos.
GPU-por-hora vs TaaS: la matematica del cambio
Estos numeros son ilustrativos, no precios prescriptivos. Pero el contraste es claro.
| Modelo | Precio referencia | Utilizacion | Ingreso anual por GPU H100 |
|---|---|---|---|
| GPU-per-hour | USD 3 por hora | 70% promedio | USD 18.400 |
| Token-as-a-Service | USD 1 por 1M tokens, 30M tokens/hora | 60% token-active | USD 157.680 |
La diferencia es de casi 9 veces a favor del modelo TaaS, con la misma H100. Las nuevas generaciones amplifican el efecto: NVIDIA GB200 NVL72 entrega mejoras de orden de magnitud en tokens-por-segundo y costo-por-millon-de-tokens frente a la generacion anterior, y proveedores de inferencia lideres reportan hasta 10 veces menor costo-por-token en cargas reales cuando combinan Blackwell con stacks optimizados.
Estas economias son mas faciles de capturar cuando se monetiza en la capa de tokens en lugar de por GPU-hora, porque mas tokens-por-segundo y menor costo-por-token se traducen directamente en mejor economia unitaria para servicios medidos en tokens.
Monetizar la fabrica como una token factory
En un modelo GPU-por-hora, el ingreso esta capeado por cuantas horas se puede rentar una GPU y a que tarifa. Se puede afinar utilizacion y precios, pero la unidad de valor sigue siendo "dolares por GPU-hora", asi que las mejoras en hardware y software se manifiestan como presion para bajar tarifas por hora en lugar de mayores margenes.
En el modelo TaaS, la misma GPU se monetiza por cuantos tokens de alta calidad puede producir a traves de un stack optimizado, a un precio dado por millon de tokens y un SLA. Vista asi, la fabrica de IA se vuelve una token factory: cada mejora del stack, mejor batching, ruteo y scheduling mas inteligente, modelos mas eficientes, networking mas rapido y storage que elimina cuellos de I/O, aumenta tokens-por-segundo o reduce el costo-por-token.



