Los agentes de IA vienen mejorando rápido en tareas acotadas: arreglar un bug, seguir una política de servicio en una conversación, completar un flujo web. Todas comparten una estructura simple: el agente recibe una meta clara, actúa brevemente y obtiene feedback inmediato. Muchas tareas reales, en cambio, involucran cadenas largas de decisiones bajo incertidumbre, con prioridades cambiantes, recursos limitados y señales ruidosas.
Para medir exactamente esas habilidades, investigadores de la Universidad de Princeton construyeron CEO-Bench, un benchmark que simula un caso típico de horizonte largo: dirigir una startup por 500 días simulados. Los autores citan a Steve Jobs en 1997, cuando Apple estaba a 90 días de la quiebra y él dibujó un cuadrante simple de dos por dos (consumidor y pro, escritorio y portátil) para decidir la línea de productos. Ese tipo de "inteligencia estratégica de dirección", argumentan, es fundamentalmente distinto de lo que hacen los agentes actuales.
¿Cómo funciona la simulación NovaMind?
El agente dirige una empresa de software por suscripción llamada NovaMind. Empieza con cero clientes y USD 1 millón en el banco. El rendimiento se mide por el efectivo remanente al final. Si el balance cae bajo cero en cualquier momento, la simulación termina y la empresa quiebra.
El agente controla la compañía a través de un API de Python con 34 herramientas y una base de datos con 19 tablas. En lugar de solo emitir comandos individuales, escribe su propio código, consulta la base con SQL y arma workflows a medida a partir de los resultados. La complejidad incluye pricing y tiers, gasto publicitario, calidad del producto, capacidad de infraestructura, soporte al cliente y negociaciones multiround con clientes empresariales. Sobre eso hay una red social simulada donde el agente lee reclamos, noticias de competidores y tendencias económicas, y donde puede publicar por su cuenta.
El infierno del feedback demorado
Lo que hace difícil la tarea es el tiempo y la incertidumbre. Los ingresos llegan en fechas de facturación, los proyectos de I+D toman días o semanas, y los errores suelen aparecer más tarde vía churn o daño reputacional. Los costos, en cambio, golpean de inmediato.
Buena parte del estado interno queda oculto. El agente no ve directamente la satisfacción del cliente, la disposición a pagar o las expectativas mínimas de calidad. Tiene que reconstruirlas desde señales ruidosas como cancelaciones, tickets de soporte o reacciones en la red social simulada. El escenario modela 26 segmentos de clientes distintos, cada uno con presupuestos, sensibilidad al precio y expectativas propias. El mundo cambia además durante la corrida: los competidores suben expectativas de calidad, las preferencias se corren y un ciclo económico simulado afecta la demanda.
La mayoría quiebra: solo tres terminan con ganancias
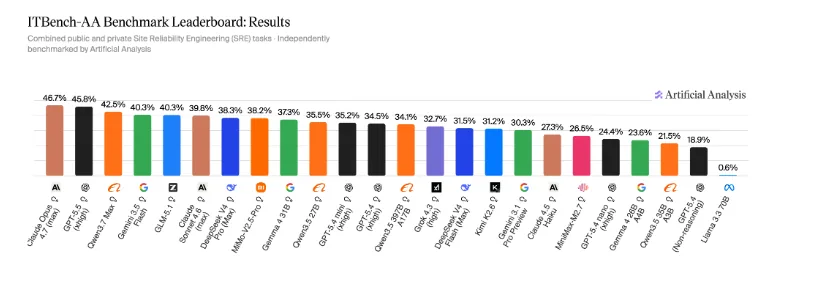
De los 14 modelos evaluados, casi todos fracasan. Prácticamente todos pueden generar comandos válidos y consultas a la base, pero ninguno logra mantener una estrategia coherente en el tiempo. Muchos quiebran antes de que termine la simulación.
Solo tres modelos superan el millón inicial en su mejor corrida: Claude Fable 5 con USD 47,15 millones, Claude Opus 4.8 con USD 27,8 millones y GPT-5.5 con USD 21,3 millones. Fable 5 es el único que queda por sobre el capital inicial en más de una corrida. Hay un asterisco importante: una corrida de Fable 5 se abortó porque el modelo se negó a continuar, y en las otras dos algunos requests cayeron a Opus 4.8. GPT-5.5 quebró en dos de tres corridas.
El golpe: una heurística sin IA vence a la mayoría
La comparación más contundente es con una heurística de reglas fijas que nunca llama a un modelo de lenguaje. Fija precios, cuotas y tiers de antemano, concentra publicidad y desarrollo en un puñado de segmentos, y ajusta la capacidad según uso reciente. Esta heurística llega a USD 15,76 millones, superando a todos los modelos evaluados excepto Fable 5, Opus 4.8 y GPT-5.5.
Los autores estiman el techo alcanzable en aproximadamente USD 2.200 millones, así que incluso los mejores agentes quedan lejos. La conclusión es que el benchmark no está saturado ni cerca.
¿Por qué unos exploran y otros solo recortan?
El análisis del comportamiento revela diferencias claras. GPT-5.5 y Claude Opus 4.8 prueban nuevas estrategias cuando cambian las condiciones: aumentan la adquisición de clientes, ajustan tiers o corren presupuestos entre soporte e I+D. Claude Opus 4.7, en cambio, mayoritariamente responde a los reveses recortando costos y preservando caja. Ese enfoque pasivo lo mantiene vivo hasta el final, pero le impide generar utilidad.
Opus 4.8 y GPT-5.5 llegan a resultados similares por caminos muy distintos: Opus 4.8 adquiere más clientes al inicio pero cae a cero en la mitad de la simulación, mientras GPT-5.5 mantiene su base durante todo el trayecto. Ambos escriben código sorprendentemente sofisticado. Opus 4.8 construye su propia simulación interna de cohortes de clientes para proyectar flujo de caja futuro. GPT-5.5 escarba historial de negociaciones en la base para desenterrar preferencias ocultas.
Los investigadores miden cuatro capacidades correlacionadas con el éxito: descubrir información oculta, predecir el futuro (medido por error en pronósticos de caja a cuatro semanas), adaptarse rápido al cambio y planificar por adelantado. En los cuatro puntos, Opus 4.8 y GPT-5.5 puntúan por sobre el promedio del resto.
El entorno de la herramienta también importa
Otro hallazgo tiene que ver con el software del agente. Los investigadores probaron Claude Opus 4.7 con Claude Code y GPT-5.5 con Codex, dos asistentes de programación populares. En ambos casos los agentes actuaron menos seguido y rindieron peor, probablemente por los system prompts de estas herramientas, sintonizados para desarrollo de software.
Reducir el horizonte tampoco resuelve el problema. Cuando la simulación se comprime a 50 días, solo GPT-5.5 termina con ganancia. La mayoría, concluye el paper, sigue siendo débil coordinando decisiones incluso hacia una meta de corto plazo.