
IA
Claude Opus 5 lidera benchmarks y cuesta menos que Fable 5
El modelo de Anthropic encabeza el Artificial Analysis Intelligence Index con 61 puntos y baja el costo por tarea hasta la mitad en los tramos de razonamiento intermedios.
The Decoder
26 notas publicadas

El nuevo modelo insignia de Anthropic lidera en programacion agentica y trabajo de conocimiento, y cuesta la mitad por token que Fable 5.

Moonshot AI lanzo su modelo mas capaz, con pesos abiertos prometidos para el 27 de julio; supera a GPT-5.5 y Opus 4.8 en sus propios benchmarks, pero cobra como la gama Claude Sonnet.

La plataforma mide no solo si un robot completa la tarea, sino cuando falla, por que falla y con cuanta confianza estadistica se puede afirmar que una politica es mejor que otra.
Los primeros benchmarks del nuevo procesador Arm de AWS lo ubican por delante del Intel Xeon 6, aunque todavía por debajo del AMD EPYC Turin en la nube EC2.

La plataforma de NVIDIA Research busca resolver uno de los problemas sin resolver de la robótica: cómo medir de verdad si una política de control funcionará fuera del laboratorio.

El modelo empata en el Intelligence Index de Artificial Analysis, gana el duelo de programación y llega con un costo por tarea más bajo que sus rivales directos.
El modelo de xAI queda detrás de Fable 5 y GPT-5.5 en varios benchmarks de programación, pero cuesta 2 dólares por millón de tokens de entrada y usa 4,2 veces menos tokens que Opus 4.8.

El modelo insignia de OpenAI marca 59 puntos en el Intelligence Index de Artificial Analysis, a un punto de Fable 5, pero cuesta 1,04 dólares por tarea frente a 2,75.
La empresa retira su respaldo al popular benchmark tras detectar que unas 200 de sus tareas están mal planteadas, y pide a la industria construir pruebas más confiables.

En la final del AtCoder World Tour 2026, un sistema de OpenAI resolvió los cinco problemas de la división de algoritmos y superó por amplio margen a los mejores programadores competitivos del mundo.

El modelo abierto chino igualó a Opus 4.8 en un benchmark interno de Databricks a 1,28 dólares por tarea frente a 1,94, y pasa a ser el modelo de trabajo diario de sus desarrolladores.

Los nuevos índices de Artificial Analysis colocan al modelo de Anthropic primero en finanzas, derecho y medicina, pero una sola tarea puede costar más de cien veces que una alternativa abierta.
Phoronix midió el impacto de la extensión vectorial en el SoC de 16 núcleos X100/A100 con Bianbu 4.0, Linux 6.18 y GCC 15.2, y descubrió que apagar RVV por sysfs simplemente rompe el sistema.

El AI Security Institute demostró que aumentar 10× el presupuesto de tokens sube el desempeño hasta 25 puntos en tareas de ingeniería de software y modifica la curva real de progreso del frontier.

Un benchmark de genómica lista por primera vez Luna Pro, Terra Pro y Sol Pro; Sol Pro alcanza 31,5% de pass rate en la prueba.
Consume 40% más tokens de salida que Sonnet 4.6 y triplica los ciclos de agente. El costo promedio salta de USD 1,20 a USD 2,29, aún más caro que el propio Opus 4.8.

Princeton diseñó un benchmark donde agentes IA dirigen una startup ficticia por 500 días simulados. La mayoría quiebra, y una heurística sin IA supera a casi todos los modelos probados.

Phoronix midió la CPU Olympus de 88 núcleos frente al SoC Altra Max de 128 Neoverse-N1, en igual stack Ubuntu 24.04 LTS sobre System76 Thelio Astra.
El nuevo tope de gama de Anthropic lidera el Artificial Analysis Intelligence Index con 64,9 puntos, pero su corrida completa de benchmarks bordea los USD 10.000, el doble que Opus 4.8.

Phoronix midió a NVIDIA Vera de 88 cores contra el Ampere eMAG de 32 cores de 2018, sobre Ubuntu 24.04 y GCC 16.1: el promedio geométrico mejora 7x solo por hardware ARM.

El benchmark STAC-AI LANG6 con Llama 3.1 8B y 70B muestra hasta 2,8x más rendimiento por GPU frente a Hopper en cargas de inferencia con documentos EDGAR.
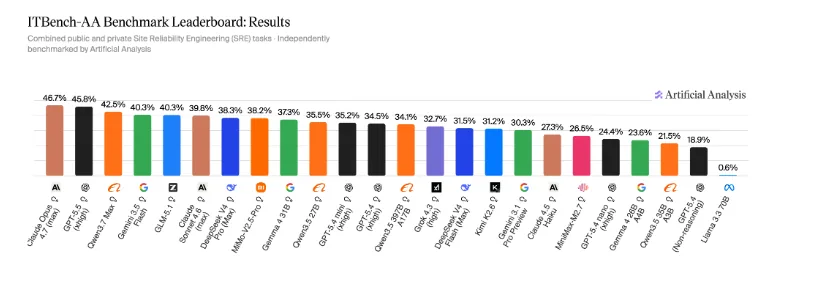
El primer benchmark IBM-Artificial Analysis para agentes en operaciones IT de empresa coloca a Claude Opus 4.7 al frente con 47%, seguido por GPT-5.5 con 46% y Qwen3.7 Max con 42%.

El benchmark CiteVQA de la Universidad de Pekín muestra que hasta el mejor modelo (Gemini 3.1 Pro Preview) saca solo 76/100 cuando se exige que la cita apunte al párrafo correcto del PDF.

El modelo más rápido en su clase de inteligencia consume tantos tokens en tareas de agentes que supera incluso al Gemini 3.1 Pro en costo total.

Tsinghua publicó un benchmark de 400 casos en cuatro dimensiones de razonamiento; los modelos comerciales doblan a los open source, pero la lógica desnuda a toda la categoría.
Otros temas que aparecen junto a #benchmarks en nuestra cobertura editorial.