A medida que las ventanas de contexto crecen, mover pesos de modelos grandes de forma eficiente se vuelve crítico para el rendimiento. Una forma común de abordar esto es la cuantización, una técnica de optimización que comprime los pesos del modelo a un formato de datos más pequeño. Un formato de cuantización es NVFP4, un punto flotante de 4 bits introducido con la arquitectura NVIDIA Blackwell.
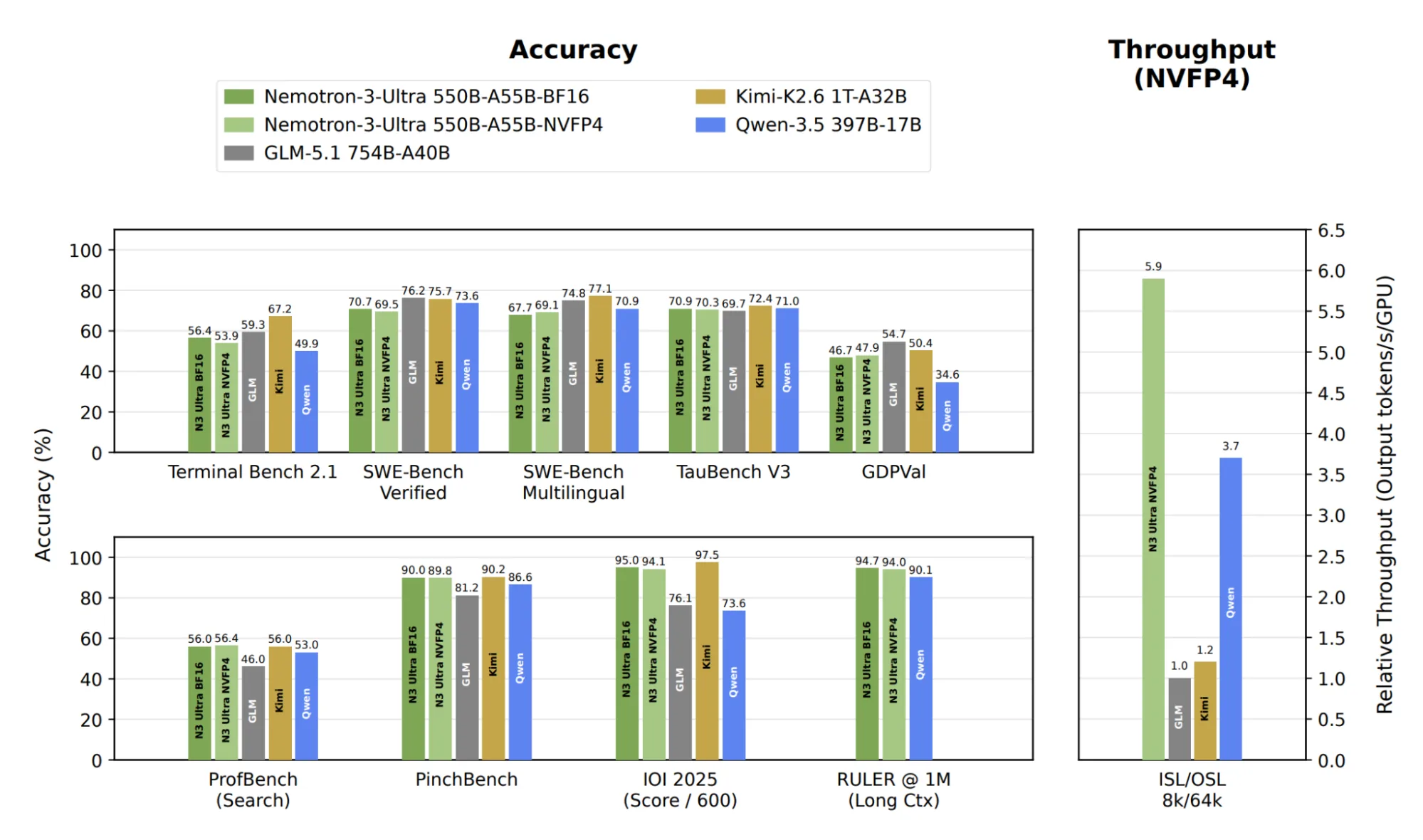
Ese es el enfoque detrás del nuevo checkpoint Nemotron 3 Ultra NVFP4 de NVIDIA: el modelo cuantizado al formato NVFP4 usando NVIDIA Model Optimizer. El resultado es un modelo que alcanza hasta 5,9x más throughput de inferencia que GLM-5.1 754B FP4 en cargas decode-heavy, mientras matchea la precisión de BF16 en casi todos los benchmarks.
¿Qué tiene de especial el checkpoint Nemotron 3 Ultra NVFP4?
Un equívoco común es que cada capa de un checkpoint NVFP4 está almacenada en NVFP4. No es así: distintas capas se cuantizan a distintos formatos de precisión, elegidos según la sensibilidad de cada capa a la arquitectura y su impacto en la precisión del modelo.
Después de la cuantización NVFP4, el modelo Nemotron 3 Ultra se reduce de 1.121 GB en BF16 a 352,3 GB, una compresión de 3,2x. Eso recorta el hardware footprint a la mitad.
Una innovación clave del Nemotron 3 Ultra NVFP4 es que un único checkpoint corre tanto en NVIDIA Hopper como en Blackwell. Logra esto convirtiendo el formato de pesos para que coincida con el hardware donde corre. En Hopper, que no tiene tensor cores FP4 nativos, el framework de serving cambia automáticamente a W4A16. En Blackwell, usa W4A4 nativo.
Si bien W8A8 (pesos de 8 bits, activaciones de 8 bits) parece la elección obvia para Hopper, su footprint de memoria más grande deja poco margen para encajar Multi-Token Prediction (MTP). NVIDIA encontró que MTP solo cabe junto a W4A16, así que W4A16 matchea o supera a W8A8 en toda la línea.
El desafío de cuantizar a FP4: solo 8 valores positivos
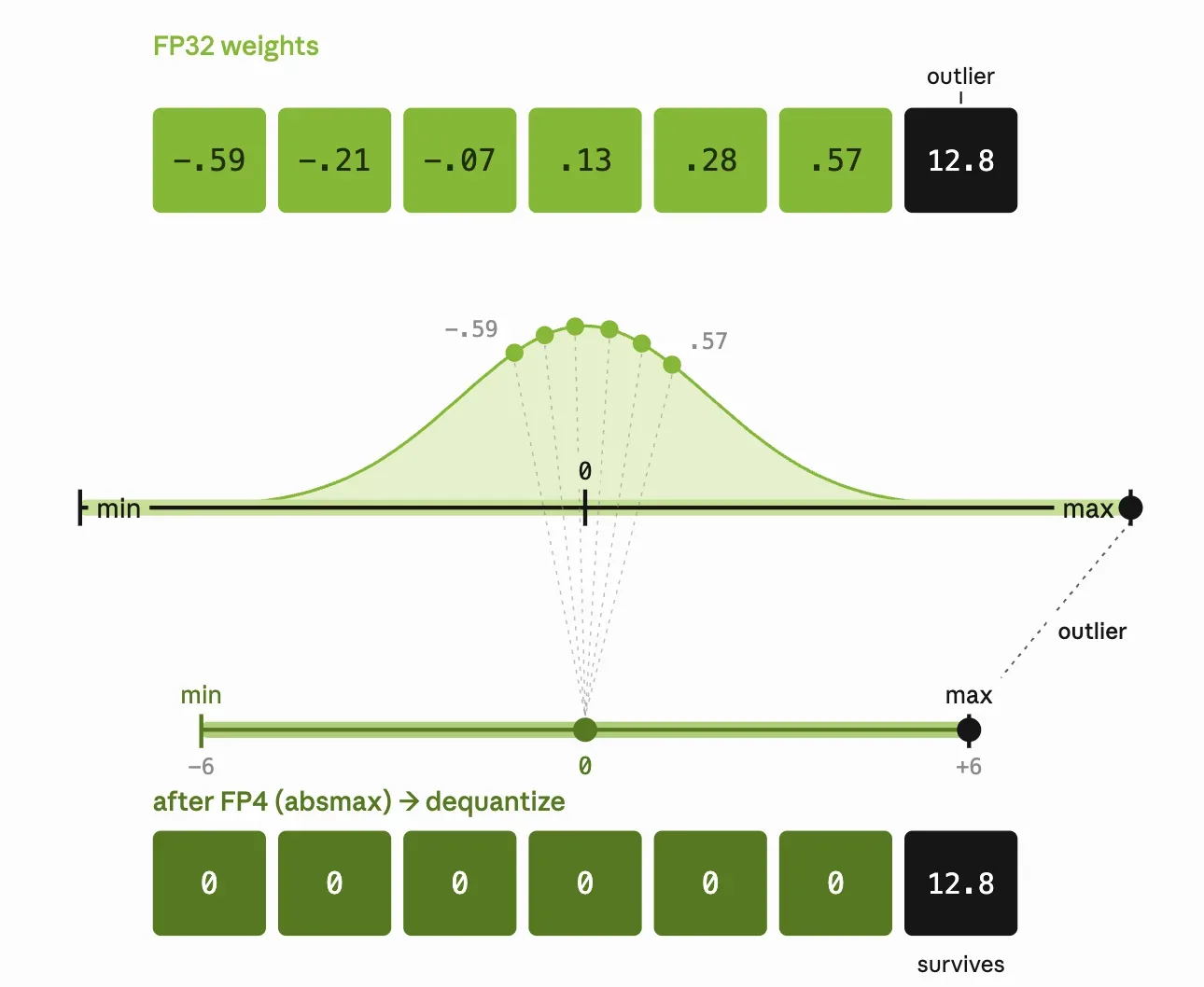
Con cuantización FP4, hay solo 8 valores positivos [0, 0.5, 1, 1.5, 2, 3, 4 y 6] para representar un bloque entero de pesos. Hay que determinar cómo mapear el rango original de valores. Esto se controla mediante un scale, esencialmente un multiplicador que determina la granularidad de la representación. Elegir un mal scale significa o desperdiciar precisión en valores pequeños o cortar valores grandes, lo que perjudica la calidad del modelo.
NVIDIA evalúa tres aproximaciones para elegir el scale óptimo: max scaling, MSE scaling y four-over-six scaling.
Max scaling: simple pero sensible a outliers
Aquí se setea el scale para que el valor más grande del bloque mapee al máximo valor representable en FP4. Con la presencia de un solo outlier grande, el max scaling comprime cada otro valor del bloque a un rango angosto, potencialmente colapsándolos a cero.
# W4A4 — pesos y activaciones a NVFP4 (default, max scaling)
model = mtq.quantize(model, mtq.NVFP4_DEFAULT_CFG, forward_loop=forward_loop)Max scaling (también llamado absmax) es la opción más simple, pero esa sensibilidad a outliers hace que rara vez sea la mejor.
Mean Squared Error scaling
Otro enfoque es MSE scaling, que busca el scale que minimiza el error de reconstrucción promedio en todo el bloque. Sin embargo, un menor MSE no siempre se traduce en mejor precisión del modelo. La calibración MSE redujo el error de pesos per-tensor en 27,1% sobre four-over-six scaling en los experimentos de NVIDIA con Nemotron 3 Ultra, pero no produjo mejora consistente en benchmarks downstream.
Four-over-six: la jugada de Nemotron 3 Ultra
NVFP4 representa solo los 8 valores positivos: 0, 0.5, 1, 1.5, 2, 3, 4 y 6. Después de 4, el siguiente valor salta directo a 6. Cualquier peso que cae en ese rango se redondea agresivamente a 4 o 6, a veces incurriendo en más de 13% de error en un solo valor.
Four-over-six arregla esto: cada bloque de pesos elige de forma independiente entre scaling a un máximo de M=4 o M=6, escogiendo el que minimiza el error de reconstrucción. Four-over-six trabaja sobre los pesos y cae al NVFP4 default para activaciones.
Four-over-six se usó para setear los scales de pesos de los routed experts FP4 en Nemotron 3 Ultra, subiendo el scale global de pesos per-tensor en 1,75x. A través de los 49.152 projection weights en las 48 capas MoE del modelo, recortó el MSE mediano de reconstrucción en 16,4% comparado con la calibración max estándar, y entregó el mejor resultado downstream en el setting balanceado 5,03-BPE: 98,5% de recuperación mediana relativa a BF16, por delante de max (96,8%) y MSE (98,4%).
model = mtq.quantize(model, mtq.NVFP4_FOUR_OVER_SIX_CFG, forward_loop=forward_loop)NVFP4_FOUR_OVER_SIX_CFG se libera en la próxima versión 0.46 de NVIDIA Model Optimizer en julio.
Bits-per-element y AutoQuantize
Effective bits-per-element (BPE) refiere al número promedio de bits requeridos para almacenar todos los pesos del modelo. Un modelo con todos los pesos en BF16 usa 16 effective bits-per-element, mientras que un modelo half-FP8 / half-BF16 usa solo 12. NVFP4 agrega overhead de scaling per-block y per-tensor, llevando su mínimo a 4,5 effective bits-per-element.
El objetivo es buscar la configuración de cuantización que empuje BPE efectivo lo más bajo posible sin sacrificar precisión. Esto es complicado porque las capas no son igualmente robustas. NVIDIA Model Optimizer AutoQuantize (mtq.auto_quantize) lo hace automáticamente: en lugar de un config fijo, recibe un target bit budget (por ejemplo auto_quantize_bits=4.8) y una lista de formatos candidatos como NVFP4_DEFAULT_CFG y FP8_DEFAULT_CFG.
Luego puntúa la sensibilidad de cada capa y busca la asignación de formato per-layer que cumple el budget con la mejor precisión, dejando las capas más sensibles en el formato de mayor precisión o saltándolas por completo.
Para encontrar el bits-per-element correcto para Nemotron 3 Ultra, NVIDIA barrió cinco puntos de operación desde 4,85 hasta 7,19 effective bits-per-element. La señal clave vino de AA-LCR, donde pasar de 4,85 a 5,03 mejoró el benchmark en 2,4 puntos, y el rendimiento se aplanó más allá de 5,03. Esto hace de 5,03 BPE el sweet spot para Nemotron 3 Ultra.
¿Por qué importa para devs y usuarios finales?
Para developers entrenando modelos propios sobre Hopper o Blackwell, NVFP4 con four-over-six de Model Optimizer ofrece la mejor relación precisión/tamaño documentada hasta la fecha en NVIDIA. Para usuarios finales el impacto es indirecto pero relevante: modelos grandes como Nemotron 3 Ultra de 550B parámetros que antes requerían 1.121 GB en BF16 ahora caben en 352 GB, lo que reduce el número de GPUs necesarias para servirlo.
Para empresas chilenas y latinoamericanas que rentan GPU H100 o B200 vía AWS, GCP o Azure, una reducción de 3,2x en footprint significa servir el mismo modelo con un tercio del costo de instancia. Para makers que quieren correr LLMs propios en racks compactos, NVFP4 acerca modelos de frontera al rango de presupuesto de servidores de un solo rack.