NVIDIA entregó una barrida limpia en MLPerf Training v6.0, la última edición del benchmark estándar de la industria desarrollado por el consorcio MLCommons. La compañía logró el menor tiempo de entrenamiento a escala y la mayor performance por acelerador en cada test medido. También fue la única plataforma que presentó resultados en cada prueba.
¿Qué cambió respecto de la versión anterior del benchmark?
MLCommons introdujo en esta ronda nuevos benchmarks de pre-entrenamiento pensados para reflejar las últimas tendencias del modelado en IA, incluyendo DeepSeek-V3, un Mixture of Experts (MoE) masivo de 671 mil millones de parámetros que sirve también de base para el popular reasoning model DeepSeek-R1, y GPT-OSS-20B, un MoE más pequeño pero capaz.
La plataforma de NVIDIA fue la única en presentar resultados sobre ambos workloads. El sistema NVIDIA GB300 NVL72 marcó el techo de performance, con un diseño que conecta 72 GPUs Blackwell Ultra y 36 CPUs Grace como una sola unidad mediante NVLink y NVLink Switch.
Escala sin precedentes sobre el fabric de red
Entrenar modelos de frontera exige infraestructura masiva y la capacidad de ejecutar workloads de forma eficiente sobre miles de procesadores interconectados. En varias entradas de esta ronda, los cloud service providers asociados a NVIDIA escalaron a 8.192 GPUs Blackwell operando al unísono sobre datacenters cloud diversos. Esas presentaciones probaron la robustez real del stack Blackwell en flotas hyperscale de producción, mostrando tendencias de escalamiento fuertes sobre entornos de cluster variados.
Sacarle el máximo rendimiento a cada iteración a esa magnitud exige moverse mucho más allá de un único dominio NVLink, apoyándose en plataformas de red scale-out como NVIDIA Spectrum-X Ethernet y NVIDIA Quantum InfiniBand. El paralelismo experto dentro de los modelos MoE genera flujos bursty de baja entropía, un patrón que típicamente reduce el ancho de banda efectivo bajo ECMP estático cuando los flujos grandes colisionan en enlaces compartidos.
Para resolverlo, el Advanced Adaptive Routing de Spectrum-X Ethernet distribuye el tráfico paquete por paquete sobre todos los caminos disponibles según la carga en tiempo real, manteniendo el ancho de banda efectivo cerca de la capacidad teórica del fabric mientras la SuperNIC ConnectX receptora maneja la entrega fuera de orden.
¿De dónde sale el 1,3x sobre DeepSeek-V3 sin tocar el hardware?
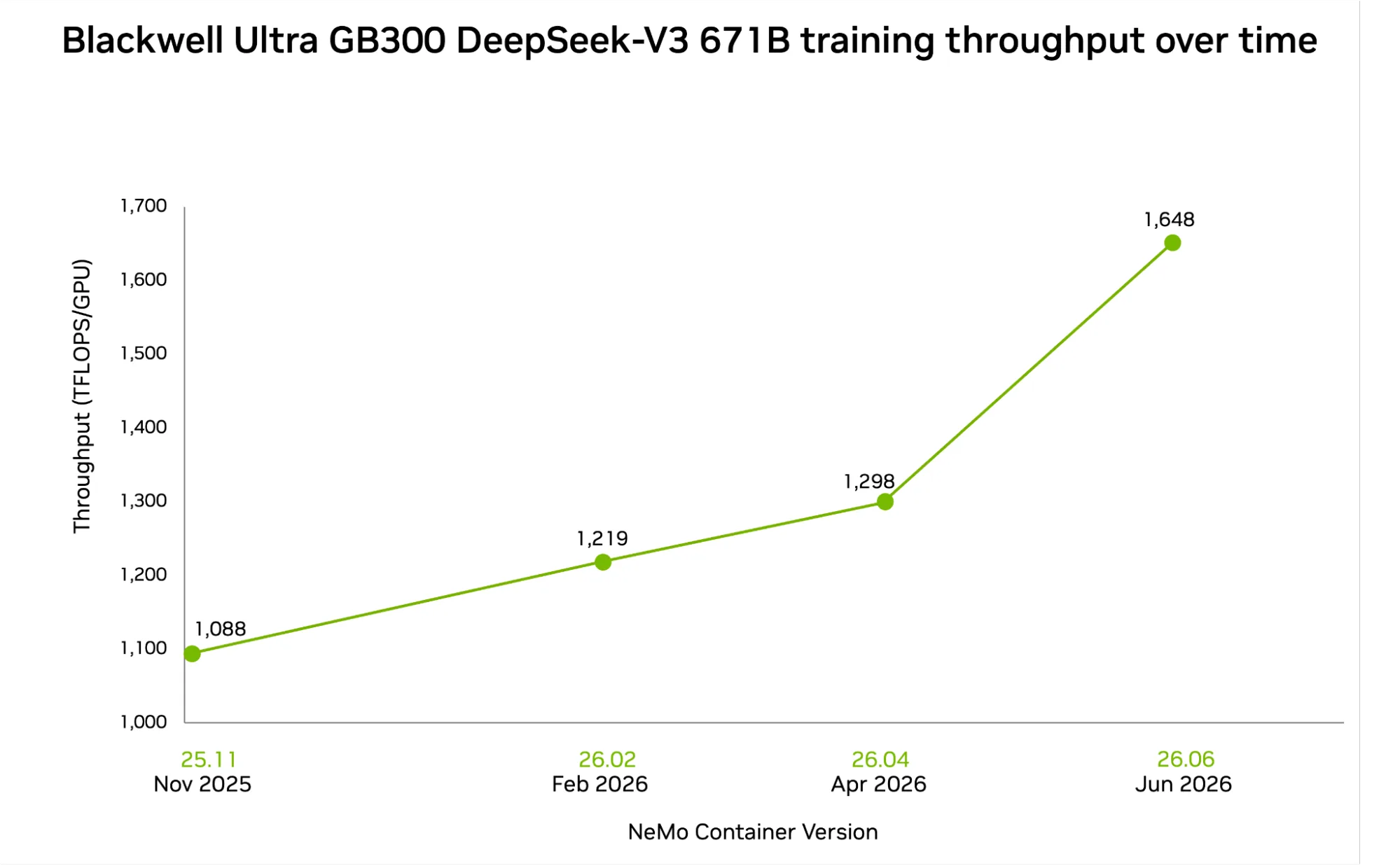
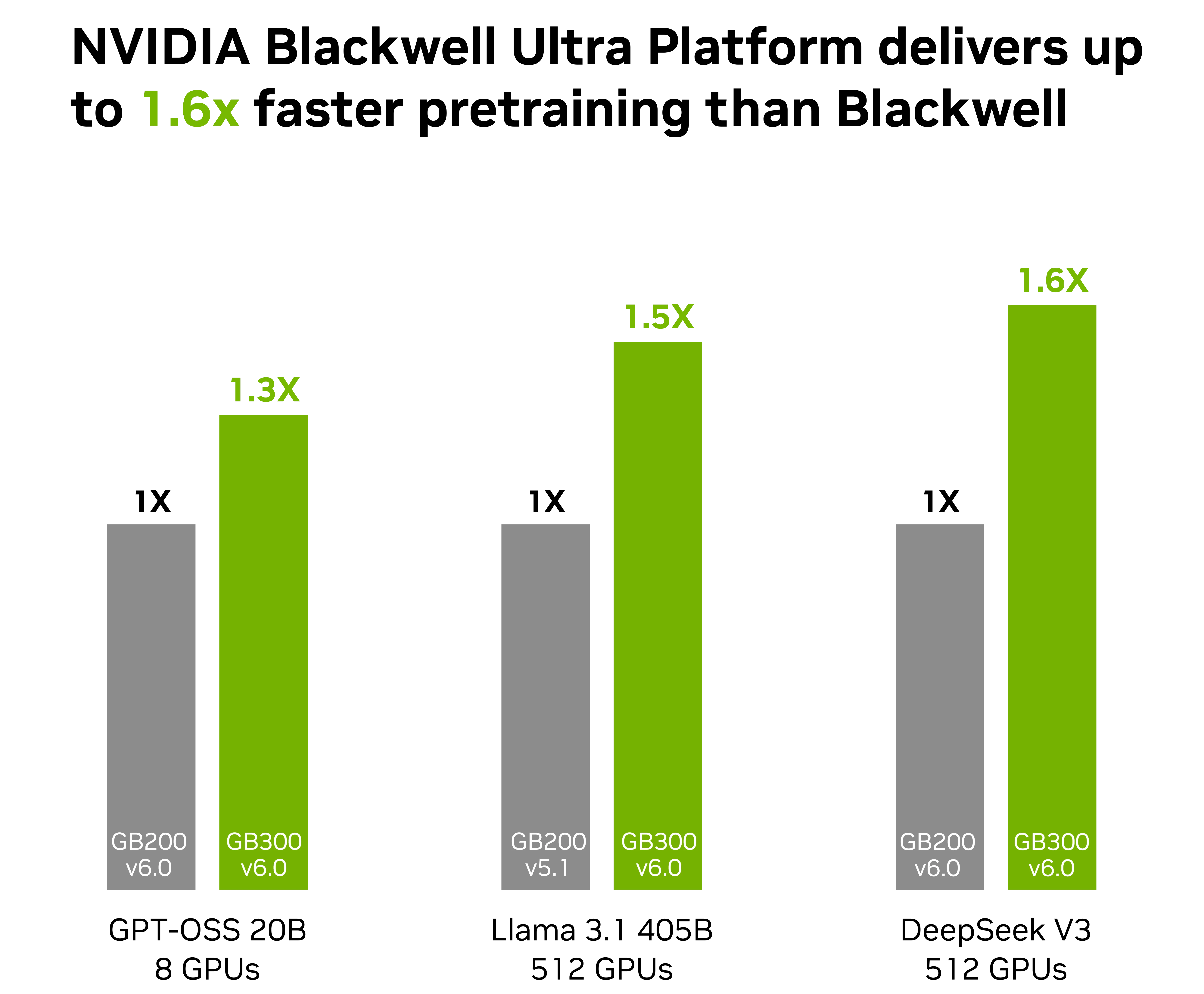
Las capacidades de hardware solo valen lo que el software que las maneja. Para extraer la performance máxima de modelos MoE complejos como DeepSeek-V3, NVIDIA desplegó varias optimizaciones de software de punta en esta ronda de MLPerf Training. El resultado: el throughput de DeepSeek-V3 aumentó 1,3 veces en tres meses sin cambios de hardware. Estos son los seis frentes clave.
CUDA graphs de iteración completa para MoEs token-dropless
Históricamente las arquitecturas MoE token-dropless costaban correr enteras dentro de CUDA graphs por las sincronizaciones dinámicas CPU-GPU. Para MLPerf 6.0, NVIDIA implementó por primera vez CUDA graphs de iteración completa. Resolvieron dos problemas: pasaron los operadores expertos (quantizer, grouped GEMM, token dispatcher) a un modo sin sincronización, y gestionaron la memoria del dispositivo sin participación del host vía paged stashing.
CuTe DSL y fusión de kernels
Para fusionar capas memory-bandwidth-bound con operaciones grouped GEMM y la ejecución sin sincronización que exigen los CUDA graphs, NVIDIA usó CuTe DSL. Esto permite combinar operaciones de matemática y manejo de memoria directo en la capa del hardware, manteniendo la data local a los registros y evitando viajes caros a la memoria global. Junto con la habilitación de CUDA graphs, estas fusiones avanzadas entregaron más de 8% de beneficio end-to-end en DeepSeek-V3 y un 93% de speedup end-to-end en GPT-OSS.
Bloque de atención en MXFP8
Tradicionalmente el entrenamiento MoE usaba precisión de 16 bits para el cómputo de atención. Esta ronda introdujo una receta MXFP8 que entregó speedup sin impactar la calidad del modelo. La receta mantiene los tensores de entrada de cada batched matrix multiply del bloque de atención en precisión 8-bit, sacando ventaja de la matemática FP8 más rápida sobre el hardware. El kernel está disponible en cuDNN a través de la librería Transformer Engine.
Router y optimizaciones HybridEP
El router del MoE asigna dinámicamente tokens a capas expertas especializadas, lo que vuelve su performance crítica para evitar cuellos de botella a nivel cluster. NVIDIA fusionó múltiples kernels elementwise dentro del router, incluyendo cómputo de top-k y scores. Para maximizar la utilización del hardware, los kernels migraron de FP64 a FP32. Esta optimización entregó un speedup de 5x sobre el kernel, y en conjunto con afinamiento dedicado de permute/unpermute aportó 5% de ganancia end-to-end.
Overlap 1F1B sobre all-to-all
NVIDIA mejoró el esquema 1F1B (One Forward, One Backward) all-to-all introducido en Megatron-Core para esconder la comunicación MoE detrás de cómputo. Para esta ronda priorizaron el stream de comunicación, usaron kernels CuTe DSL despachados dinámicamente y habilitaron el soporte de wgrad diferido. En estado estacionario consiguieron casi 100% de overlap sobre la comunicación all-to-all, lo que aportó un beneficio total de 8% de performance.
Balance entre etapas de pipeline
A medida que los kernels individuales se vuelven más rápidos, los desbalances entre etapas de pipeline parallel se vuelven más pronunciados. Para DeepSeek-V3, el modelo usa un layout híbrido con tres capas densas al frente y Multi-Token Prediction más logits GEMM con cross-entropy al final. Aprovechando el layout flexible de Megatron-Core para balancear etapas y adoptando MXFP8 para el logit projection GEMM, redujeron el desbalance del pipeline a menos del 1%, lo que se tradujo en 4% de ahorro de performance end-to-end.
¿Qué hardware nuevo trajo Blackwell Ultra?
Las mejoras de hardware del Blackwell Ultra GB300, incluyendo presupuestos más grandes de memoria y energía, permitieron mayor localidad de modelos y throughput respecto del GB200. La optimización full-stack sobre librerías y frameworks de NVIDIA (cuDNN, Transformer Engine, Megatron Core, Megatron Bridge) aseguró que las ganancias de eficiencia se trasladaran directo a despliegues a escala de producción y aceleraran los cronogramas de entrenamiento de IA empresarial.
Comparativa rápida: Blackwell Ultra vs alternativas anunciadas
| Plataforma | Tests en MLPerf 6.0 | DeepSeek-V3 (671B) | GPT-OSS-20B | Escala máxima |
|---|---|---|---|---|
| NVIDIA GB300 NVL72 | Todos | Sí | Sí | 8.192 GPUs |
| AMD MI355X | Parciales | Parcial | No | N/A |
| Google TPU v6e | Parciales | No | No | N/A |
| Intel Gaudi 3 | Parciales | No | No | N/A |
Solo NVIDIA presentó submission completo en cada categoría medible.
¿Qué significa para entrenadores y para Chile?
El piso del precio para entrenar modelos de frontera todavía es prohibitivo para clientes chilenos individuales, pero el dato útil para integradores y centros de cómputo locales que evalúan inversión en aceleradores es claro: cualquier comparación seria contra rivales (AMD MI355X, TPU v6e de Google, Intel Gaudi 3) debe hacerse sobre los mismos benchmarks completos. NVIDIA aprovecha hoy la combinación de hardware más maduro (GB300 con NVLink Switch) y el ecosistema de software más afinado (Megatron-Core, Transformer Engine, cuDNN). Para quien evalúe armar un cluster local de inferencia o fine-tuning, la lectura es que el costo total de propiedad sigue cayendo por software sobre el silicio existente.