El Remote Labor Index (RLI) mide con qué frecuencia los agentes IA logran terminar proyectos freelance pagados a un nivel de calidad que un cliente real aceptaría. En ocho meses, la tasa de automatización top más que se cuadruplicó, pasando de 2,5% a 16,1%.
El índice fue desarrollado por el Center for AI Safety (CAIS) junto a Scale Labs, y cubre áreas como 3D y CAD, arquitectura, diseño gráfico, video y animación, audio, análisis de datos y aplicaciones web. Incluye 240 proyectos por un valor combinado de USD 144.000, tomados de encargos verificados de 358 freelancers reales. Evaluadores humanos del CAIS puntúan cada entrega contra una referencia creada por un profesional pagado.
La métrica clave es la tasa de automatización, es decir, el porcentaje de proyectos en que el trabajo del agente IA es calificado como al menos tan bueno como el de un humano.
¿Qué modelos lidera hoy el ranking?
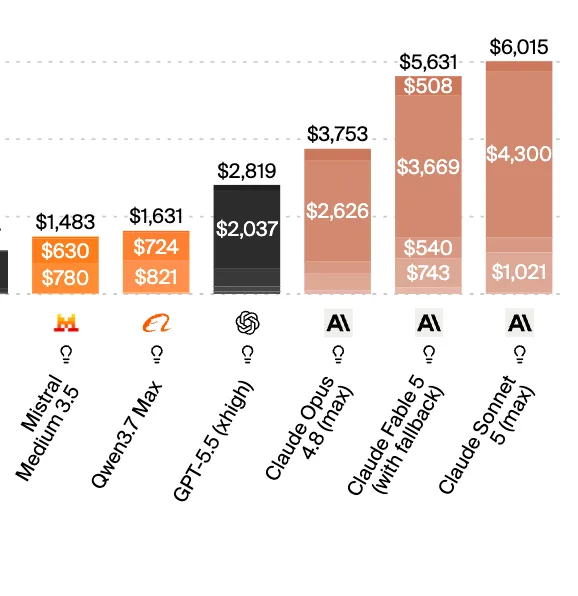
Cuando el benchmark se lanzó a fines de 2025, el mejor agente automatizaba apenas 2,5% de los proyectos. La última corrida entrega un salto importante: Fable 5 alcanza 16,1%, el mayor score registrado hasta ahora. Es aproximadamente el doble del 8,3% de Opus 4.8 y casi el triple del 6,3% de GPT-5.5. Los tres modelos superan a todos los sistemas evaluados antes. El líder previo, Opus 4.6 corriendo sobre el framework Claude Cowork, quedaba en 4,17%.
Los autores del reporte remarcan que la frontera se cuadruplicó en menos de ocho meses.
Hay una precisión importante sobre Fable 5: solo 218 de los 240 proyectos pudieron ser evaluados antes de que el gobierno de EE.UU. restringiera el acceso al modelo. Aún en el peor escenario, donde Fable 5 hubiese fallado todos los proyectos faltantes, su tasa quedaría en 14,6%, más alta que la de cualquier otro modelo probado.
El progreso no sigue la fecha de lanzamiento
En la tabla completa del Scale Labs leaderboard, un modelo más reciente como Gemini 3 Pro cae hasta 1,25%, por debajo de sistemas mucho más antiguos. La lectura del CAIS es que la habilidad para operar software profesional no escala solo con el tamaño o la fecha de release: hay un componente de tooling y de training específico que separa a los agentes que rinden en el mundo real de los que no.
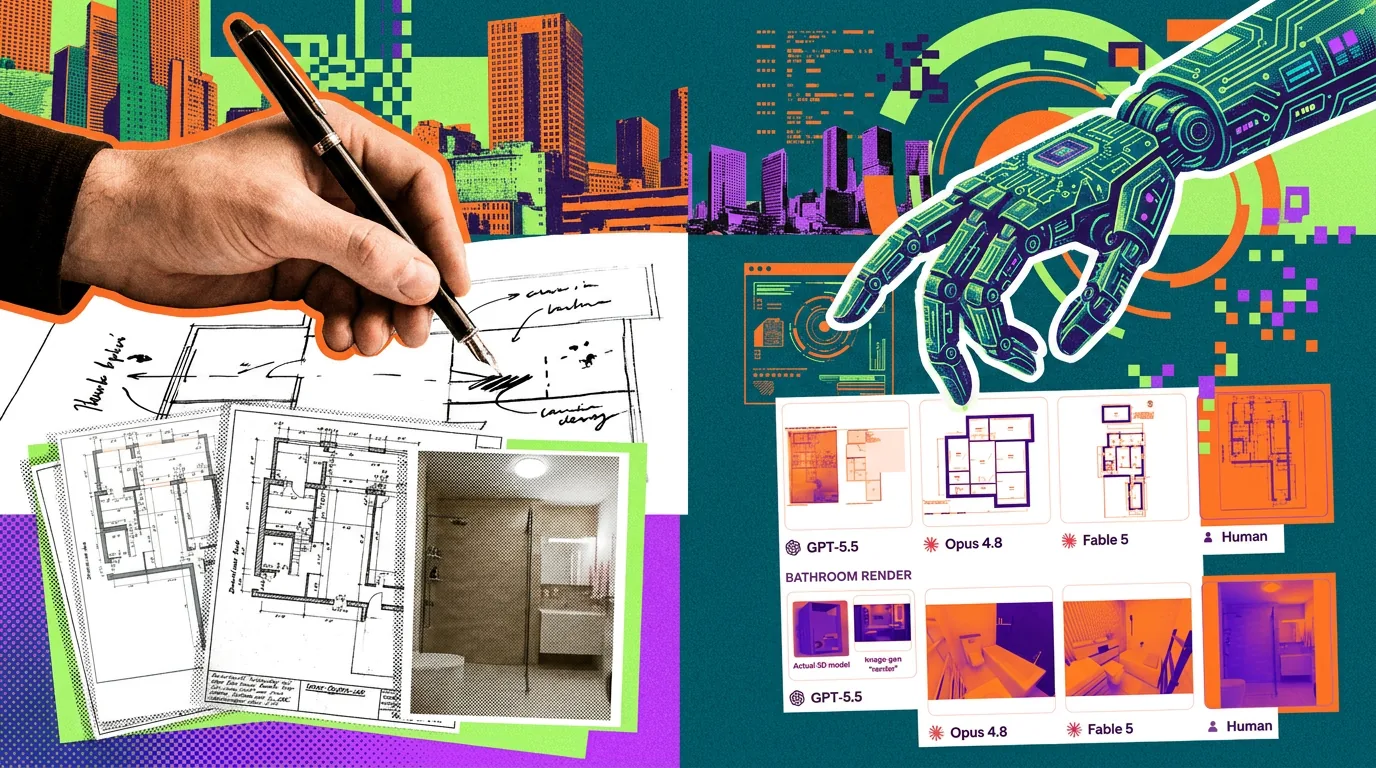
Ejemplos del estudio dejan ver las costuras. En una tarea de diseño de anillos, Fable 5 mejora claramente a los modelos anteriores pero todavía se ve poco profesional al examinarlo de cerca. En un proyecto de arquitectura, GPT-5.5 falseó un render atractivo usando un generador de imágenes mientras que el modelo 3D real quedaba defectuoso.
¿Se pueden reemplazar los evaluadores humanos?
El equipo probó si la evaluación humana, cara y lenta, podía ser reemplazada por jueces IA. La respuesta fue negativa: los jueces automáticos calificaron a los modelos nuevos con demasiada generosidad. Para GPT-5.5, el score del evaluador IA fue casi tres veces más alto que el humano. Para Opus 4.8, unas dos veces y media. El juez automático acertó el orden del ranking, pero los números absolutos quedaron desplazados por lejos.
La explicación del CAIS es directa: para juzgar de manera justa una entrega, hay que abrir los archivos en el software profesional correcto, operarlo bien y formar un juicio como lo haría un cliente pagador. Ese uso concreto y hands-on del software es precisamente lo que a los agentes actuales les cuesta más. Un juez IA choca contra los mismos límites que los agentes que evalúa. El render falseado de GPT-5.5 es un buen ejemplo: para detectar el truco hay que abrir el modelo 3D e inspeccionar la geometría.
El entorno de prueba
Para dejar mostrar toda la capacidad, el equipo corre los modelos con las mismas herramientas que usan desarrolladores día a día, como Claude Code y Codex CLI, extendidos con la capacidad de operar programas gráficos directamente. El entorno de trabajo es una máquina virtual Linux con más de 30 aplicaciones profesionales instaladas, incluidas Blender, GIMP y Audacity. Cada proyecto recibe hasta 24 horas de tiempo de cómputo. El setup usa además un critic loop: un segundo agente IA revisa la salida con el nivel crítico de un cliente exigente, y el primer agente reescribe su trabajo.
Los agentes todavía fallan en llegar a calidad profesional en la mayoría de los proyectos. Ninguno de los tres ejemplos de Fable 5 mostrados en el post original pasaría como trabajo terminado. Pero el ritmo de mejora dentro de un mismo año es rápido, según los autores, y refleja de forma directa cuán veloz avanza la automatización del trabajo remoto.
Comparativa: cómo quedó el ranking RLI
| Modelo | Tasa de automatización | Comentario |
|---|---|---|
| Fable 5 | 16,1% | 218/240 proyectos por restricción de acceso |
| Opus 4.8 | 8,3% | Segundo lugar |
| GPT-5.5 | 6,3% | Tercer lugar |
| Opus 4.6 (Cowork) | 4,17% | Líder previo del benchmark |
| Gemini 3 Pro | 1,25% | Detrás de sistemas más antiguos |
| Baseline lanzamiento | 2,5% | Score top al debutar el índice en 2025 |
Contexto para LatAm y Chile
El RLI mide trabajos que se ofertan en plataformas globales como Upwork, Fiverr y similares, donde una parte importante del oferente es LatAm. Un salto sostenido en la tasa de automatización presiona directamente los rates por hora del freelance regional en categorías de diseño gráfico, video y análisis de datos. Para un desarrollador o diseñador en Santiago, Buenos Aires o Bogotá que hoy compite en dólares en esas categorías, un modelo top pasando de 2,5% a 16% en ocho meses es una señal concreta: la ventana de tareas "básicas pero pagadas" se está cerrando, y el diferencial humano se corre hacia software profesional, revisión crítica y coordinación de clientes que ningún agente automatiza bien todavía.