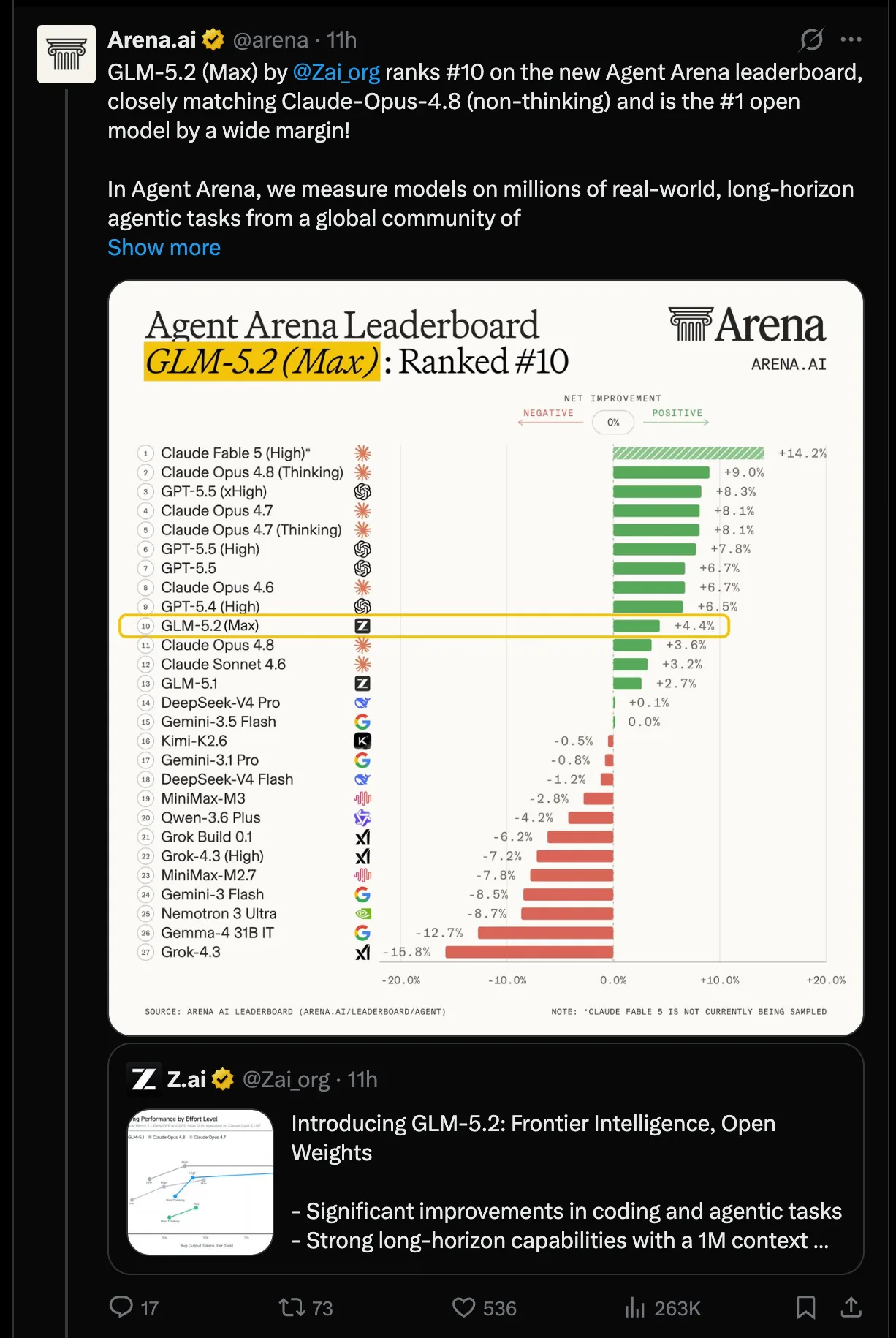
Snowflake comparó GLM-5.2 de Zhipu AI y Claude Opus 4.7 de Anthropic en un benchmark práctico. El modelo chino aguantó el envión: con 103 tareas corridas tres veces cada una, donde los modelos debían escribir código que funcionara tanto en DuckDB como en Snowflake, ambos quedaron prácticamente parejos. GLM resolvió el 66% de las tareas y Opus el 67%, según los datos publicados por Sridhar Ramaswamy, CEO de Snowflake.
¿Dónde Opus 4.7 saca ventaja real?

La diferencia aparece en la precisión al primer intento: Opus alcanzó 53,7% contra 47,6% de GLM. Eso muestra que el output del modelo chino es menos consistente. Además, Opus es más eficiente: GLM requiere un promedio de 99 iteraciones por tarea contra las 80 de Opus y quema 860 millones de tokens contra los 439 millones de Opus, casi el doble.
La fortaleza específica de GLM, según el CEO de Snowflake, es validar código de forma confiable contra DuckDB y Snowflake al mismo tiempo, y por eso solo GLM pudo resolver ciertas tareas concretas. Su debilidad es rendirse demasiado temprano y chequear obsesivamente las cosas equivocadas. En un caso, GLM hizo 411 tool calls en 24 minutos (chequeando row counts, distribuciones, valores null y tipos de columna) y aun así falló los tres intentos. Opus resolvió la misma tarea con 49 calls en 9 minutos.
El claim previo de que GLM produce código más limpio no se sostuvo, según Ramaswamy. Más chequeos no llevan a más resultados correctos. Aun así, el equipo de Snowflake quiere ponerlo disponible para sus clientes.
¿Cuánto cuesta cada modelo?
El precio es el punto donde GLM cambia la ecuación. Según el pricing oficial de Zhipu, GLM-5.2 cuesta USD 1,40 por millón de tokens de input y USD 4,40 por millón de tokens de output. Algunos proveedores terceros incluso bajan ese precio. Opus 4.7 corre a USD 5 input y USD 25 output, mientras que GPT-5.5 sale USD 5 input y USD 30 output.
| Modelo | Input | Cached Input | Output |
|---|---|---|---|
| GLM-5.2 | USD 1,40 | USD 0,26 | USD 4,40 |
| Claude Opus 4.7 | USD 5,00 | USD 0,50 | USD 25,00 |
| GPT-5.5 | USD 5,00 | USD 0,50 | USD 30,00 |
| GPT-5.4 | USD 2,50 | USD 0,25 | USD 15,00 |
El mayor consumo de tokens de GLM achica esa brecha de precio, pero sigue siendo dramáticamente más barato. Anthropic y OpenAI enfrentan presión real, y justo en coding, el caso de uso emblemático sobre el que ambos labs occidentales construyeron su pitch.
¿Qué pasa si la presión llega al revenue?
Si esa presión desacelera el crecimiento de ingresos o, peor aún, los achica, el mercado de IA inflado enfrenta un stress test real. Las valuaciones de OpenAI y Anthropic descansan en el supuesto de que el revenue sigue trepando rápido. Esas valuaciones están atadas a miles de millones de apuestas en infraestructura de IA, desde data centers hasta órdenes de chips.
El cambio de junio de 2026 (aprox. CLP 740 por dólar) deja a un equipo chileno que sirva 100 millones de tokens al mes con Opus pagando alrededor de CLP 1,85 millones en output, contra solo CLP 325.000 con GLM-5.2 al mismo volumen. Para startups y consultoras de la región, la diferencia entre USD 4,40 y USD 25 por millón de tokens no es un detalle de margen, es el factor que define si el producto es viable o no.
¿Qué le falta a GLM para ser una alternativa total?
Tres puntos quedan abiertos. Primero, la consistencia al primer intento: 47,6% vs 53,7% significa que sin retry logic, GLM falla más a menudo y hay que envolverlo en orquestación que reintente. Segundo, la latencia: 99 iteraciones promedio versus 80 ya es 24% más lento end-to-end, y el ejemplo de los 411 tool calls en 24 minutos muestra que el peor caso puede ser mucho peor. Tercero, la disponibilidad regional: el endpoint oficial de Zhipu corre en China y agregar latencia trans-pacífica para usuarios chilenos puede empujar el TTFT (time-to-first-token) a niveles incompatibles con UX interactiva.
Los proveedores terceros (Together AI, Fireworks, OpenRouter) que sirven GLM-5.2 desde infraestructura US/EU resuelven la latencia, pero suben el precio. La ecuación final depende de cuánto se castigue el costo unitario al pagar el routing geográfico.