El aprendizaje por refuerzo (RL) se volvió una pieza central en el alineamiento de modelos de lenguaje: va desde el clásico RLHF dentro de asistentes IA hasta los flujos más nuevos de RL con recompensas verificables (RLVR) para razonamiento y tareas de agente. NVIDIA publicó una guía técnica que explica cuándo conviene usar RL en agentes empresariales, cómo estructurar el bucle de entrenamiento y qué ofrece su ecosistema Nemotron y NeMo.
Los laboratorios de frontera ya mostraron que RL mejora capacidades generales. OpenAI entrenó sus modelos serie o con RL a gran escala, y DeepSeek-R1 demostró cómo la group relative policy optimization (GRPO) con recompensas verificables mejora matemática, código y razonamiento.
NVIDIA Nemotron 3 Super se post-entrenó con RL multi-entorno usando 21 verificadores de NVIDIA NeMo Gym y 37 datasets, generando cerca de 1,2 millones de rollouts de entorno.
¿Por qué importa el RL para agentes?
Las organizaciones necesitan agentes especializados para flujos concretos: triage de seguridad, descubrimiento científico, automatización de CLI, soporte al cliente, análisis de datos, uso de herramientas internas. Customizar modelos abiertos como Nemotron hace esto práctico, permitiendo especializar accuracy y velocidad con control sobre datos, IP y despliegue.
Prompting, RAG y herramientas llegan lejos. Pensá al modelo como el cerebro del agente, al harness como su cuerpo y a las herramientas como el espacio donde puede actuar. Mejorar el harness o agregar herramientas ayuda, pero no siempre cambia la conducta del modelo.
Si el agente repite errores en llamadas a herramientas, falla en flujos largos, formatea salidas mal o elige la estrategia equivocada, se necesita señal de entrenamiento. Ahí encaja el RL.
Cuándo usar SFT, DPO, RLHF o RLVR
Antes que "¿qué algoritmo uso?", la pregunta correcta es "¿qué conducta quiero aumentar y cómo la voy a medir?".
- SFT: cuando hay demostraciones del comportamiento deseado, como instrucciones, conversaciones multi-turn, esquemas de salida, formatos de tool-call o flujos de dominio.
- DPO: cuando existen pares de preferencia donde una respuesta es mejor que otra.
- RLHF: cuando las preferencias humanas son sutiles y no se capturan con reglas, y se cuenta con reward models y infraestructura de entrenamiento cuidadosa.
- RLVR: cuando la correctitud se puede chequear algorítmicamente. Ejemplos: JSON válido, comandos CLI correctos, tests que pasan, respuestas matemáticas exactas, llamadas a herramientas exitosas, resultados de simulador.
Para casos verificables de agente y uso de herramientas, un camino común es: SFT si hace falta, después GRPO con recompensas verificables, después evaluar, inspeccionar fallas y repetir.
GRPO como default para RLVR
GRPO se volvió el punto de partida práctico para flujos RLVR. Genera múltiples completaciones por prompt, las puntúa con un verificador y actualiza el modelo según el desempeño relativo dentro del grupo. Comparado con RLHF estilo PPO, tiene menos piezas móviles y trabaja de forma natural con recompensas basadas en reglas.
También aparecen variantes más nuevas. DAPO suma sampling dinámico y clipping asimétrico para preservar señal útil y diversidad exploratoria. GSPO optimiza a nivel de secuencia en lugar de token, mejorando estabilidad de entrenamiento sobre todo en modelos Mixture-of-Experts (MoE).
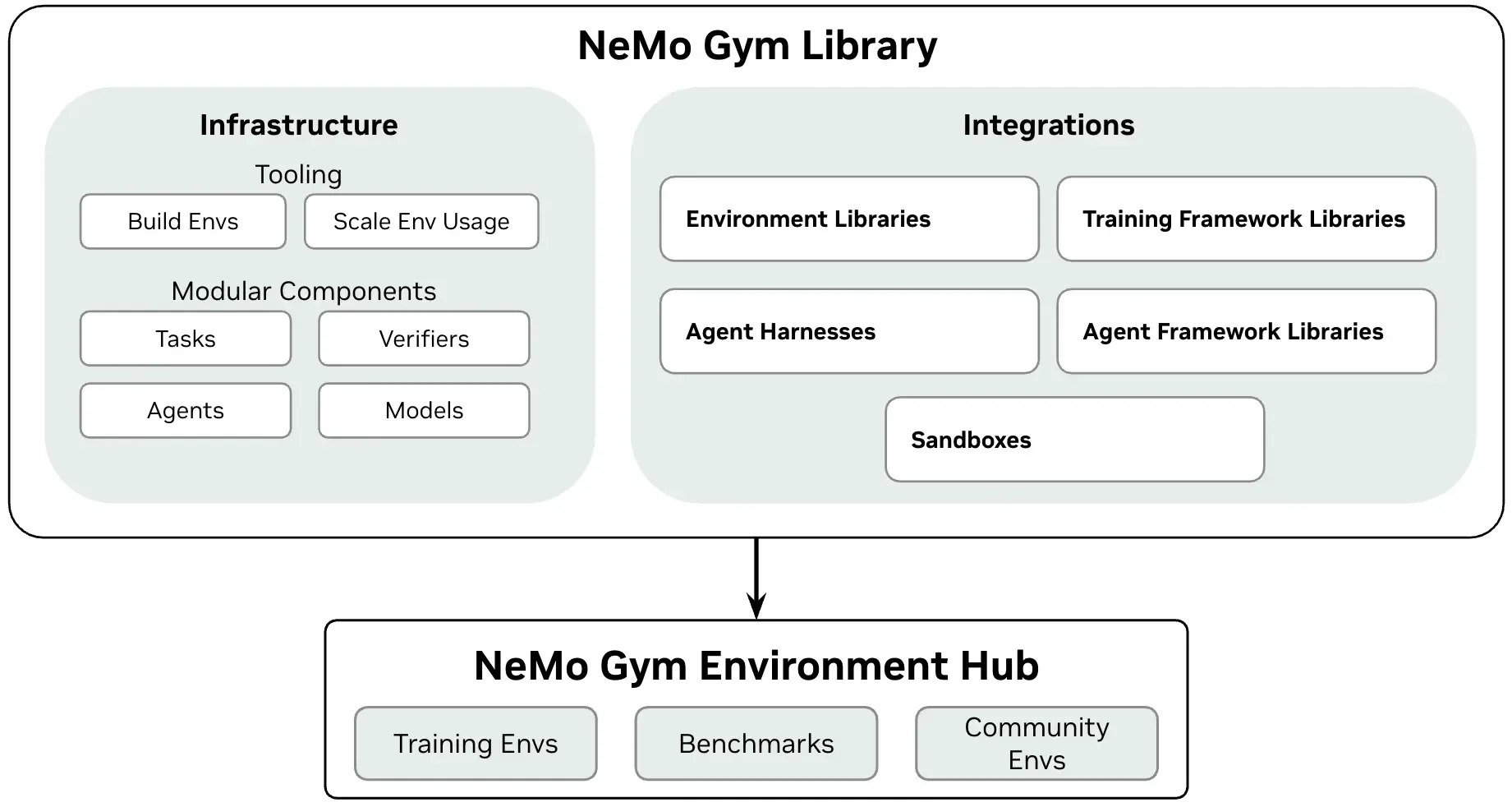
El bucle mínimo de RL
Una corrida de entrenamiento por refuerzo para LLMs o agentes tiene siete piezas:
- Policy model: el modelo que estás entrenando.
- Task: el input que recibe.
- Action: la salida, tool-call, parche de código, comando o trayectoria multi-paso.
- Environment: el sistema que ejecuta la acción y devuelve feedback.
- Verifier: la señal que puntúa éxito o produce recompensas.
- Rollouts: intentos muestreados del modelo actual.
- Policy update: el paso de entrenamiento que aumenta la probabilidad de mejores salidas.
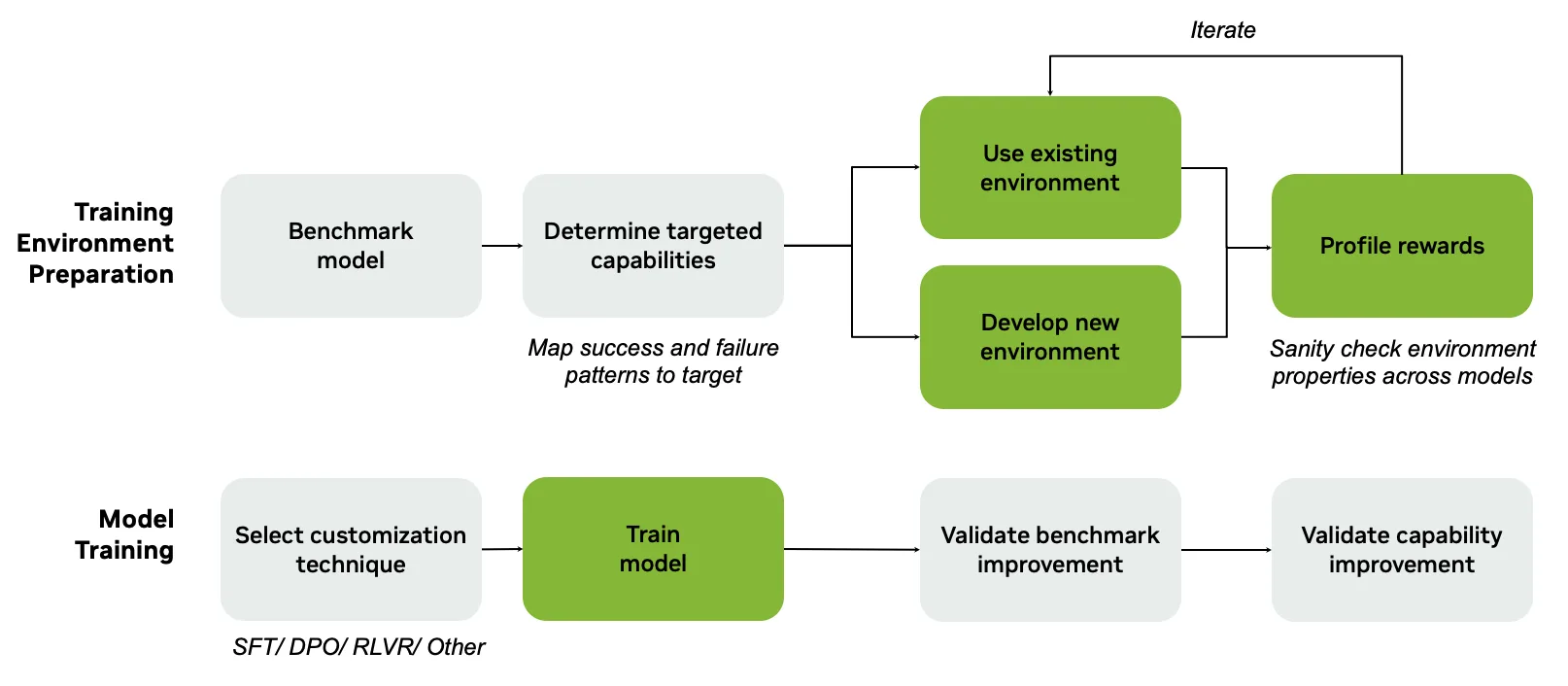
Empezá siempre con evaluación antes que con entrenamiento. Corré el modelo actual sobre un set de tareas apartado, inspeccioná las fallas y perfilá el verificador antes de actualizar pesos. El RL funciona mejor cuando el modelo a veces produce la conducta correcta pero no de forma confiable. Si la recompensa está mal, el RL optimizará la conducta equivocada.
Datos y entornos: agentes necesitan más que un dataset
Para SFT alcanza con pares input-output que enseñen la conducta deseada. Para RLVR hacen falta tareas, lógica de entorno con verificadores y herramientas capaces de puntuar salidas. La generación sintética de datos ayuda a cubrir cuando los ejemplos reales son escasos: generá variantes, casos borde, escenarios de tool-call y salidas esperadas, después filtrá con validadores, reward models o revisión LLM-as-judge.
NVIDIA NeMo Data Designer permite generar datasets estructurados desde cero o con datos semilla, controlar relaciones entre campos, batching y validación contra especificaciones. Después, NeMo Gym puede correr esas tareas por entornos para generar trayectorias puntuadas desde modelos o teacher agents.
Los datos sintéticos no son ground truth. Mantené un set semilla pequeño de calidad humana, deduplicá agresivo, apartá tareas de eval y revisá las fallas antes de usar los datos para entrenamiento.
Para RL agente que abarca tareas single-step, multi-step y multi-turn, el entorno tiene que definir el harness. Un agente de código puede necesitar muchas tool-calls antes de que pasen los tests, un agente de análisis de datos puede necesitar inspeccionar archivos, correr queries, generar gráficos y validar resultados, un agente científico puede necesitar buscar literatura, llamar simuladores y revisar hipótesis.
Diseño de recompensas: empezar simple
El diseño de la recompensa es donde muchos proyectos RL se complican de más.
Arrancá con la recompensa más simple que pruebe que el bucle funciona. Para RLVR, puede ser binaria: +1 si la salida pasa el verificador, 0 si no. Agregá señales intermedias solo cuando midan progreso real. Para un agente de código podría ser: +0.1 eligió la herramienta correcta, +0.2 produjo un artefacto intermedio válido, +0.3 pasó un test parcial, +1.0 completó la tarea, -1.0 acción insegura.
Demasiado shaping enseña al modelo a optimizar el checklist en lugar de la tarea. Una buena función de recompensa cumple tres propiedades:
- Mide la tarea real.
- Es difícil de hackear.
- Falla de forma visible cuando está mal.
Antes de entrenar, correr la función contra 50-100 salidas del modelo y revisar manualmente los puntajes. Si la recompensa discrepa con tu juicio, arreglá la recompensa antes de gastar GPUs.
Cómputo: presupuesto para entrenamiento y rollouts
El costo de RL viene de dos cargas: rollout y entrenamiento. Ambas dependen del batch, del tamaño del modelo y de la longitud de secuencia. El costo de rollout escala además con el número de tool-calls, turnos de conversación y pasos de entorno.
Software de inferencia como vLLM mejora la latencia de rollout, y NeMo Gym mejora la orquestación de llamadas a herramientas.
Para equipos que arman esto en Chile o LatAm, la palanca de costo suele ser rollout más que training. Un agente con 20 tool-calls por trayectoria y 512 rollouts por batch fácilmente consume 10 veces más GPU-hora en generación que en el step de update. Perfilar esto temprano ahorra semanas.