
Electrónica
Dos mini PCs locales para 50 millones de tokens al día
Un periodista de tecnología cuenta cómo armó un stack casero con un AMD Ryzen AI Max+ 395 de 96 GB para correr Qwen3.5 sin pagar APIs frontera.
Tom's Hardware
5 notas publicadas

Un usuario del subreddit Local LLaMA muestra que seis módulos Intel Optane DCPMM de segunda mano alcanzan para alojar un mixture-of-experts de un billón de parámetros con una sola GPU.

Un entusiasta de LLMs locales empaquetó un Jetson Orin NX Super 16GB, más de 30 sensores y un avatar de ojos saltones en una maleta para conversar sin WiFi ni red celular.

El proyecto corre MiniMax M2.5, Gemma 4, Qwen3.6, DeepSeek V4 y los modelos on-device de Apple, con sandbox por hardware y más de 20 plugins integrados.
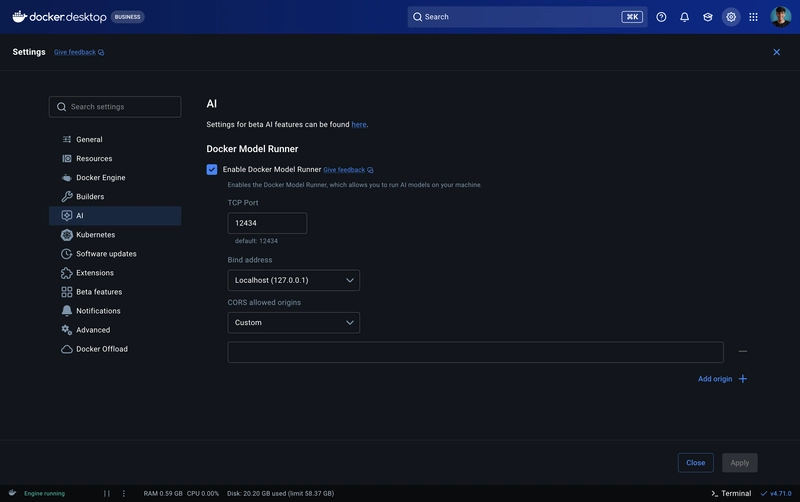
Una guia paso a paso para apuntar Claude Code a un modelo local servido por Docker Model Runner. Cero tokens cloud, util para codigo propietario o trabajo offline.
Otros temas que aparecen junto a #llm local en nuestra cobertura editorial.