NVIDIA publicó la guía oficial para configurar Slurm block scheduling sobre racks GB200 NVL72, una arquitectura que cambia las asunciones de los schedulers tradicionales porque extiende la coherencia NVLink a través de todo el rack. La consecuencia práctica: si el scheduler trata la red como un árbol best-effort —como hace el plugin clásico topology/tree—, fragmenta el job y la performance se desploma cuando los nodos cruzan dominios.
¿Qué hace única a la arquitectura GB200 NVL72?
GB200 NVL72 es, según NVIDIA, un computador exascale en un solo rack: 72 GPUs Blackwell distribuidas en 18 compute trays, unificadas por NVLink de quinta generación. Las comunicaciones dentro del rack operan a velocidades NVLink: 1,8 TB/s bidireccionales por GPU, para un agregado de 130 TB/s por rack. Cruzar la frontera del dominio coherente baja a 50 GB/s (400 Gb/s) típicos vía InfiniBand o Ethernet — un acantilado de performance que obliga a tratar el dominio NVLink como una frontera dura del scheduler.

¿Cómo funciona block scheduling en Slurm?
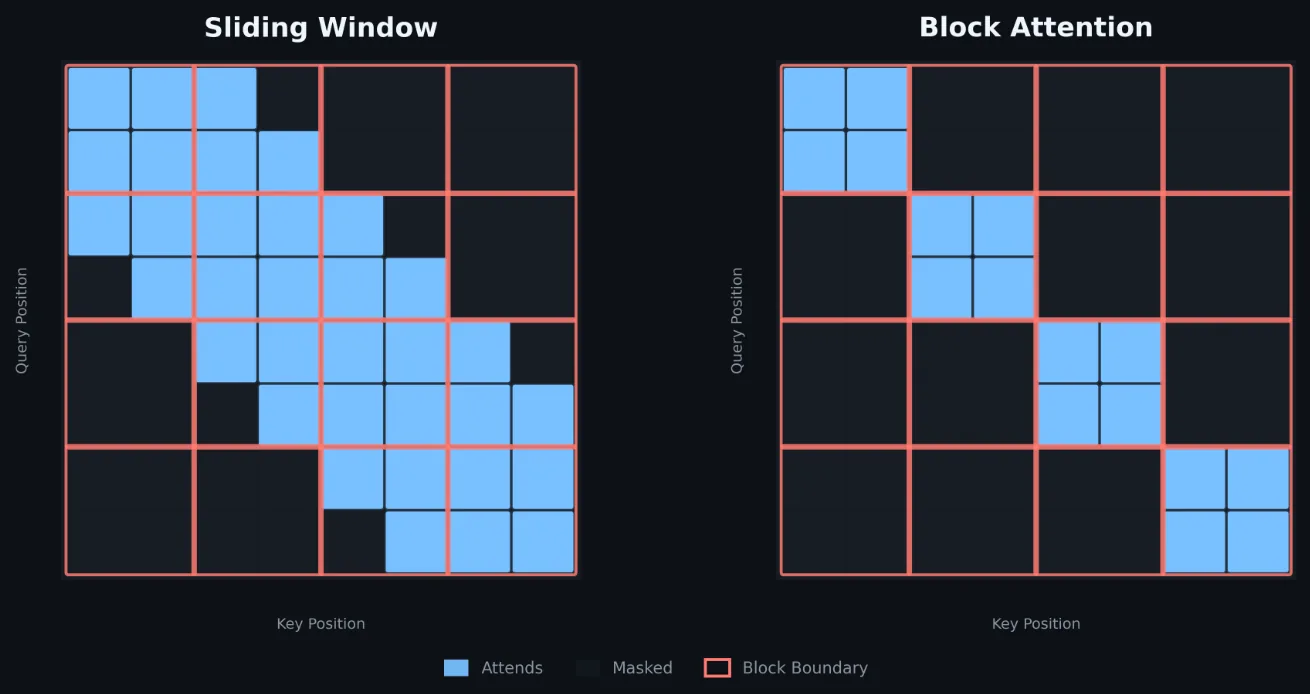
Slurm soporta scheduling consciente de topología desde hace años con el plugin topology/tree, que modela el fabric como un árbol jerárquico de switches y nodos. El objetivo histórico es minimizar la cantidad de switches que un job cruza, pero es best-effort: si hace falta empezar antes, el job puede quedar fragmentado entre varios leaf switches.
El acantilado de performance al cruzar dominios NVLink obligó a un enfoque distinto. De un esfuerzo conjunto entre NVIDIA y SchedMD, nace el plugin topology/block en Slurm 23.11, diseñado para arquitecturas rack-scale como GB200 NVL72 y GB300 NVL72.

Si un job pide una asignación que cabe dentro de un bloque (18 nodos o menos), los nodos siempre vienen de un único bloque y el job no se fragmenta.

Con el comportamiento por defecto, un job que pide 16 nodos obliga al scheduler a esperar hasta que haya 16 nodos libres dentro de un mismo dominio NVL72. Esto sube los tiempos de cola si la flota está fragmentada. Para destrabar esta restricción, Slurm introdujo el argumento --segment, que actúa como un knob para definir el grupo atómico de nodos que debe ir junto.
Ejemplo: un job que pide 12 nodos con --segment=4 puede repartirse entre tres bloques distintos, manteniendo grupos de 4 nodos NVLink-locales. Sin --segment=4 el job no podría ejecutarse si no hay un bloque libre con 12 nodos.

¿Cuándo usar --segment chico vs grande?
Una sutileza importante: Slurm puede asignar múltiples segmentos del mismo job al mismo bloque. La elección del tamaño de segmento depende del patrón de comunicación:
- Tensor Parallelism (TP): requiere segmentos pequeños y compactos para mantener la comunicación latency-sensitive sobre NVLink.
--segment=1o--segment=4. - Expert Parallelism (EP): requiere segmentos más grandes para que las operaciones all-to-all sucedan dentro de un único dominio NVLink.
--segment=16o--segment=18.
--segment=16 también es útil para distribuir nodos balanceadamente entre bloques: 32 nodos con --segment=16 se reparten 16+16 en lugar del 18+14 por defecto.

Los flags --consolidate-segments y --spread-segments, agregados en Slurm 25.11, permiten controlar el placement de los segmentos.
¿Cómo se configura?
La recomendación de NVIDIA para administradores es definir un bloque por cada dominio NVL72 del clúster (18 nodos). Para jobs menores a 18 nodos sin --segment, Slurm los mantiene en cola hasta encontrar recursos suficientes en un mismo bloque, garantizando que toda la comunicación use NVLink.
La configuración recomendada es el archivo topology.yaml, introducido en Slurm 25.05. Ejemplo con dos dominios NVL72:
---
- topology: gb200-nvl72
cluster_default: true
block:
block_sizes:
- 18
blocks:
- block: block01
nodes: node[0001-0018]
- block: block02
nodes: node[0019-0036]El plugin soporta múltiples niveles de agrupación jerárquica. El primer nivel suele ser el dominio NVL72; niveles superiores pueden reflejar la realidad física del fabric (filas de datacenter, salas, etc.). En clústeres con fat-tree completo se recomienda un solo nivel, dado que la penalización por cruzar leaf switches es menor que la penalización por cruzar dominios NVLink.
Verificación de la topología configurada:
$ scontrol show topology
BlockName=block01 BlockIndex=0 Nodes=node[0001-0018] BlockSize=18
BlockName=block02 BlockIndex=1 Nodes=node[0019-0036] BlockSize=18¿Y los usuarios? --segment=1 y --segment=16
Para usuarios, las guías son:
--segment=1cuando NVLink solo se necesita entre los 4 GPUs de un nodo (máxima flexibilidad para el scheduler).--segment=16en lugar de--segment=18cuando se necesita un dominio NVL72 completo, porque deja margen al scheduler para usar bloques con nodos drenados o caídos.
Los administradores pueden pasar de la guidance a la enforcement con un script cli_filter/lua simple que rechace jobs con configuraciones no permitidas:
function slurm_cli_pre_submit(options, pack_offset)
if options["segment"] == "18" then
slurm.log_error("error: using --segment=18 is currently not allowed.")
return slurm.ERROR
end
return slurm.SUCCESS
endImplicancias para integradores en Chile y LatAm
Para equipos que están dimensionando clústeres de entrenamiento o inferencia LLM en Chile, Brasil o México, hay tres puntos prácticos:
- No basta con tener GB200 en hoja de spec: si Slurm está configurado con
topology/tree, los jobs grandes van a fragmentarse y la performance efectiva caerá decenas de puntos porcentuales. - Versiones mínimas:
topology/blockrequiere Slurm 23.11+,topology.yamlrequiere 25.05+, y--consolidate-segments/--spread-segmentsrequieren 25.11. Distros como Rocky Linux y RHEL todavía empaquetan versiones anteriores en sus repos por defecto. - IMEX integration: Slurm también integra el driver-level GPU memory isolation de NVIDIA IMEX, clave para multi-tenant en clústeres compartidos por varias áreas (universidades, hospitales, fintech). Sin IMEX, la aislación entre jobs depende del tenant.