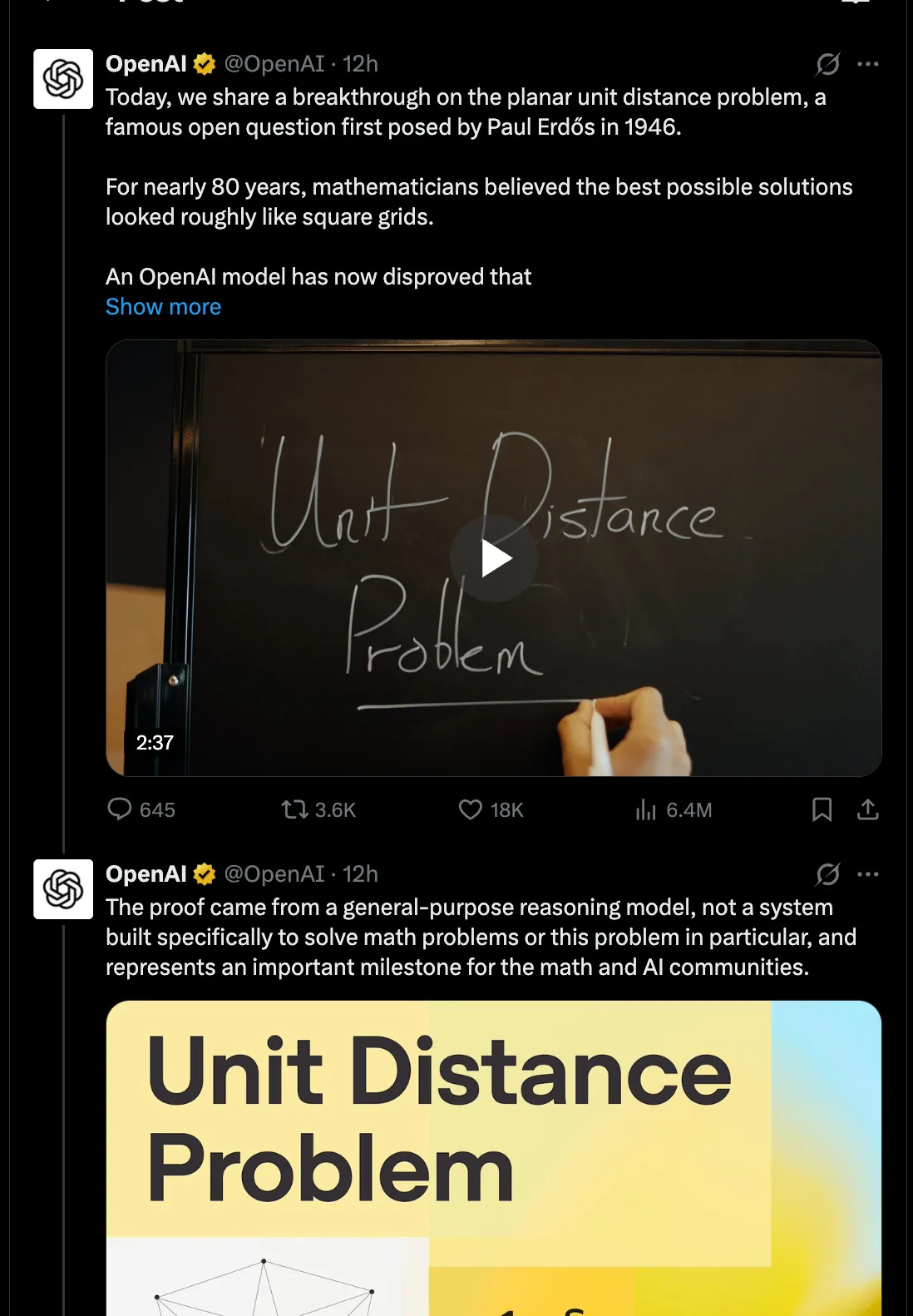
OpenAI anunció que un modelo interno de razonamiento extendido refutó una creencia de larga data sobre el problema de las distancias unitarias en el plano, una pregunta de geometría discreta planteada por Paul Erdős en 1946. La compañía estimó el costo total de la corrida en menos de USD 1.000 y un tiempo de cómputo de alrededor de 32 horas, con un modelo que circulaba en la comunidad bajo el nombre tentativo GPT 5.6.
El detalle clave es que el resultado lo produjo un LLM de propósito general, no un sistema especializado en demostración formal estilo AlphaProof o Lean. Investigadores de OpenAI subrayaron que esto sugiere que el razonamiento extendido podría generalizar más allá del dominio matemático, una propiedad que ya se había insinuado con el resultado oro del modelo en la Olimpiada Internacional de Matemática 2025.
¿Qué es el problema de las distancias unitarias?
Erdős preguntó en 1946 cuál es la cantidad máxima de pares de puntos a distancia exactamente 1 que puede haber en un conjunto de n puntos del plano. El problema parece simple pero conecta con combinatoria, geometría algebraica y teoría de incidencias, y su cota superior óptima permanece abierta ocho décadas después. El modelo de OpenAI no resolvió la conjetura completa, pero refutó un caso particular que la comunidad daba por cierto.
Los autores de la carta técnica subrayan un matiz importante.
"Esto es una refutación, no una demostración, lo que habría sido más impresionante, pero igualmente apunta hacia lo que viene", señalan en el documento abierto publicado por OpenAI.
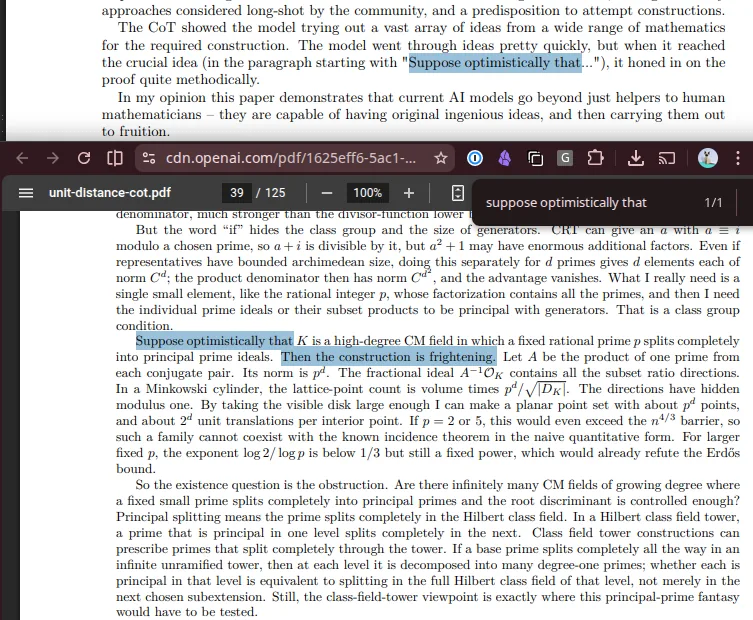
El modelo produjo 125 páginas de salida razonada, y una sección específica, bautizada en redes como "el momento de la página 39", concentró la atención técnica: muestra al sistema construyendo una configuración geométrica explícita que contradice la cota conjeturada.
¿En qué se distingue de AlphaProof?

Cuando DeepMind presentó AlphaProof en 2024, el sistema combinaba un LLM con un verificador formal en Lean: cada paso debía pasar por el chequeador para ser válido. El modelo de OpenAI, en cambio, no usa un asistente formal: la cadena de razonamiento se sostiene únicamente en el LLM, y los humanos revisan el resultado a posteriori. Según comentarios de investigadores citados por Latent Space, esa diferencia es relevante porque sugiere que la capacidad de razonamiento profundo no depende de un solucionador externo.
La carta técnica de OpenAI compara explícitamente el approach con métodos tradicionales de búsqueda combinatoria y argumenta que el modelo encontró la configuración refutadora en un espacio de búsqueda que sería intratable por fuerza bruta.
¿Cuánto cuesta hacer esto y por qué importa?
El dato del costo bajo USD 1.000 es central: implica que el modelo no necesitó un cluster de inferencia masivo durante días, sino una corrida acotada. Si el número es preciso y reproducible, baja la barrera para que grupos de investigación con presupuestos modestos puedan intentar problemas matemáticos abiertos usando LLMs de razonamiento. La comparación con corridas anteriores es ilustrativa: AlphaProof en su versión IMO 2024 requería tiempos de cómputo significativamente mayores y verificación formal posterior.
Para investigadores chilenos y latinoamericanos esto abre una ventana concreta: el costo de USD 1.000 está dentro del rango de un fondo concursable mediano (Anillo, Fondecyt Iniciación), y no exige hardware local. Aún falta saber cuándo OpenAI dará acceso público a este modelo de razonamiento extendido, pero el precedente sugiere que la próxima generación de investigación matemática asistida por IA podría descentralizarse rápidamente.
¿Es esto el inicio de "matemática automatizada"?
No. La comunidad matemática ya avisó dos cosas. Primero, una refutación de un caso particular no es lo mismo que demostrar la conjetura completa ni resolver el problema general de Erdős. Segundo, el resultado todavía debe pasar revisión por pares: si la configuración geométrica producida por el modelo es correcta, debería ser verificable manualmente por matemáticos humanos en cuestión de semanas. Si no lo es, el episodio se convertirá en otra anécdota sobre alucinaciones sofisticadas en LLMs.
Lo que sí marca el resultado es un cambio en el tipo de tareas que los modelos de razonamiento extendido pueden abordar: no solo problemas de competencia escolar (IMO, Putnam) con soluciones conocidas, sino preguntas de investigación abiertas donde nadie sabía la respuesta de antemano.



