Anthropic liberó Claude Fable 5, la variante de acceso general de sus modelos clase Mythos. Con el lanzamiento desplegó una serie de medidas de seguridad: algunas declaradas explícitamente al usuario y otras que modifican el modelo sin avisarle. El paso adelante en capacidades vino acompañado de un endurecimiento del control que apunta a proteger, o blindar, la ventaja competitiva de la compañía.
Las políticas aplicadas de forma despareja por Anthropic están en camino de convertirse en una fábula clásica sobre por qué las nociones estrechas y auto-cumplidas de seguridad y control rara vez funcionan, según Nathan Lambert en su blog Interconnects.
El modelo más inteligente disponible
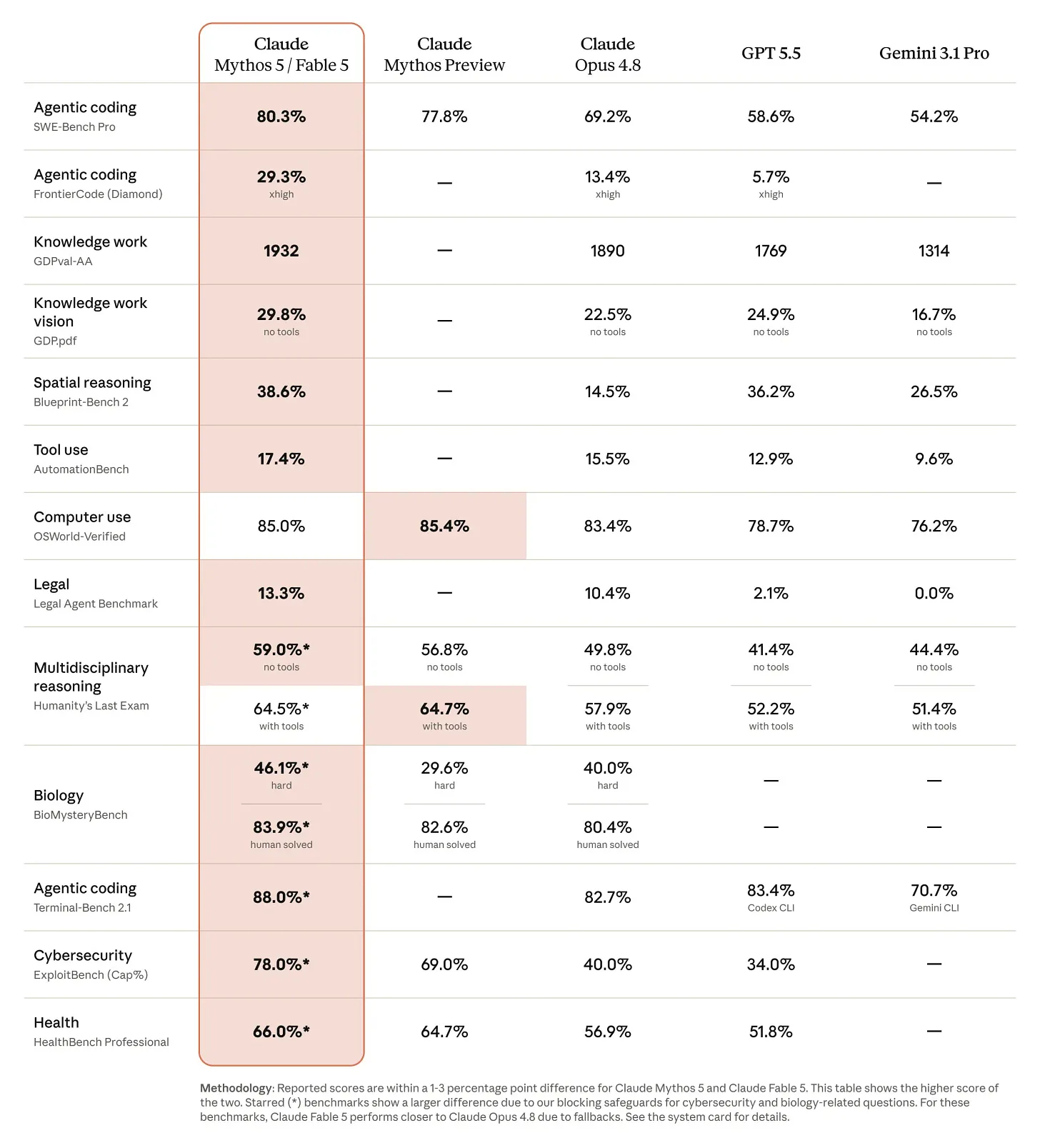
Antes de entrar en el detalle de seguridad, conviene establecer la calidad del modelo. Claude Fable 5 es, sin dudas, el modelo más inteligente disponible al público general, con un salto notable en prácticamente todos los benchmarks relevantes del momento, a solo 2× el precio de los modelos Opus actuales (todavía menos que la variante Pro de GPT 5.5). Por sí solo es un momento bisagra para el rubro. Ver un modelo dar un paso tan grande en capacidades, varios años después de la carrera post-ChatGPT, es asombroso.
No hay un breakthrough claro asociado a este modelo, como inference-time scaling o RL. La explicación pública es que el avance vino de mejoras a lo ancho de todo el stack. Como detalle relevante: el modelo se demoró más de dos meses adicionales después de terminar de entrenarse antes de estar disponible públicamente. Dada la dinámica competitiva de la economía IA, la versión más inteligente de este modelo ya está bien avanzada.
Un asterisco sobre estos puntajes: no necesariamente son los puntajes que va a obtener el público, ya que algunos prompts serán degradados a Opus 4.8 por los filtros de seguridad actuales.
Los modelos más smart engendran nuevos juegos de seguridad
Hay múltiples piezas de tooling de seguridad asociadas al lanzamiento, incluyendo políticas obligatorias de retención de datos y filtros de prompt agregados. Para sus áreas foco de ciberseguridad, destilación dirigida de modelos y biología de investigación, Anthropic detalla nuevos clasificadores de seguridad en su blog post de lanzamiento.
Cita textual de Anthropic:
"Fable 5 viene con un nuevo set de clasificadores: sistemas de IA separados que detectan posibles abusos, incluyendo intentos de jailbreak, y previenen que el modelo principal responda. Cuando los clasificadores de Fable detectan una solicitud relacionada con ciberseguridad, biología y química, o destilación, la respuesta la maneja automáticamente Claude Opus 4.8. Los usuarios serán informados cada vez que esto ocurra. Nuestros datos tempranos muestran que más del 95% de las sesiones de Fable no involucran fallback alguno."
Ejemplos de los filtros primarios de ciberseguridad y biología, que sí avisan al usuario cuando se activan, están proliferando online y parecen bastante sensibles. Pueden ser una experiencia frustrante, pero Anthropic está plenamente dentro de su derecho de aplicarlos y es intelectualmente consistente al hacerlo.
La parte preocupante: intervenciones silenciosas
La parte dañina de la historia de seguridad cae en la letra chica del System Card de Claude Fable 5:
"Hemos agregado resguardos relacionados con el desarrollo de LLMs frontera. Nos preocupa el riesgo de acelerar el ritmo general de desarrollo de IA. Hemos implementado nuevas intervenciones que limitan la efectividad de Claude para solicitudes que apunten al desarrollo de LLMs frontera (por ejemplo, construir pipelines de pretraining, infraestructura de entrenamiento distribuido o diseño de aceleradores ML). A diferencia de nuestras intervenciones para ciberseguridad, biología y química, e intentos de destilación, estos resguardos no serán visibles para el usuario. Fable 5 no caerá a un modelo distinto. En cambio, los resguardos limitarán la efectividad mediante métodos como modificación de prompt, vectores de steering o fine-tuning con parámetros eficientes (PEFT)."
Anthropic documenta cómo esto va a impactar a un porcentaje chico de usuarios, lo cual es cierto. Lambert advierte sobre el impacto en el grupo pequeño de usuarios que sostienen la difusión y comprensión de la IA fuera de los pocos labs frontera, un mecanismo crucial para la seguridad continua de la tecnología.
"IA categóricamente desalineada"
Anthropic está documentando que la proliferación de capacidades de IA es una preocupación para ellos, pero la resuelven engañando a sus usuarios. Un modelo de IA que se vuelve menos inteligente automáticamente sin notificarme es categóricamente IA desalineada, escribe Lambert. El paso siguiente en esa línea (no que Anthropic lo haya hecho, pero podría) es que un modelo manipule silenciosamente un workplace cuando considere que el uso de IA no es seguro.
Además, la implementación acá es más compleja que la documentada para ciberseguridad o biología: modificar el modelo mismo o los datos presentados, todo sin notificar al usuario.
La dualidad de estas políticas es extremadamente confusa y dibuja una inconsistencia fuerte que arroja dudas sobre las políticas de seguridad. Esta medida de "safety" se presenta como mucho más relacionada con mantener su posición competitiva. Si todas las políticas de seguridad tomaran una sola forma, sería mucho más coherente intelectualmente y fácil de respaldar.
Distillation panic y actores chinos
Anthropic ha sido muy vocal sobre su preocupación por ataques de destilación de actores chinos en particular. Sus afirmaciones no son lo suficientemente transparentes con los hechos, ni con el contexto de por qué no pueden prevenir el comportamiento, para ser completamente creíbles.
A pesar de la información limitada, en las comunidades amplias de IA y Washington DC hubo discusiones serias sobre tomar acciones contra los model builders chinos basadas en esa supuesta destilación. La hipótesis de Lambert es que los API builders no tienen un tiempo fácil para prevenir hacks o jailbreaking porque es una propiedad fuertemente arraigada de los modelos de razonamiento querer producir trazas de razonamiento, y patchearlo completo haría al modelo mucho menos inteligente.
Edit del 11 de junio
Lambert agregó una edición a la nota original: Anthropic cambió su manipulación silenciosa del modelo en consultas de investigación de IA para usar también un clasificador, como en los otros dominios de seguridad. Esto resuelve una preocupación clave que tenía sobre el maltrato de "seguridad" en el lanzamiento. "Hay que reconocer a Anthropic la rapidez del cambio", escribe, "pero no resuelve completamente la confianza que se rompió".
¿Por qué importa para LatAm?
Para una pyme de Santiago que decida integrar Fable 5 en un producto propio, el problema no es solo precio. Es que no podés saber con certeza cuándo el modelo te está respondiendo con su capacidad completa o cuándo se autocensuró por una sospecha de su clasificador interno. Esa opacidad rompe el contrato implícito de un servicio enterprise: pagás por una capacidad y esperás recibirla. Anthropic dice que afecta a menos del 5% de los casos, pero ese 5% queda repartido en sesgos invisibles que ningún SLA cubre.