
En vez de asumir que el alineamiento siempre funciona, Google Deepmind construyó un marco de seguridad que planifica para el peor caso: agentes IA que se salen del libreto.
El documento AI Control Roadmap detalla cómo la empresa cierra el perímetro de sus sistemas internos más avanzados. Deepmind cree que el modelo puede servir como plantilla para el resto de la industria.
La premisa es directa: el marco asume que un agente IA altamente capaz podría no compartir los objetivos de sus operadores y se diseña para esa contingencia. Deepmind lo compara con un instructor de manejo con doble mando: el instructor confía en el alumno pero mantiene una mano cerca del volante y un pie cerca del freno. La misma idea aplica acá. Los agentes solo reciben permisos según comportamiento verificado y la confianza crece de a poco mediante acceso controlado.
Deepmind modela a sus agentes como insider threats
Deepmind trata a sus agentes IA internos como empleados que ya tienen acceso a la oficina pero podrían actuar contra los intereses de la empresa. El marco se apoya en el framework MITRE ATT&CK, una herramienta de ciberseguridad ya consolidada que descompone ataques en tácticas y técnicas individuales. Eso le permite a Deepmind rastrear riesgos sistemáticamente, detectar comportamientos sospechosos temprano y probar defensas en ejercicios controlados.
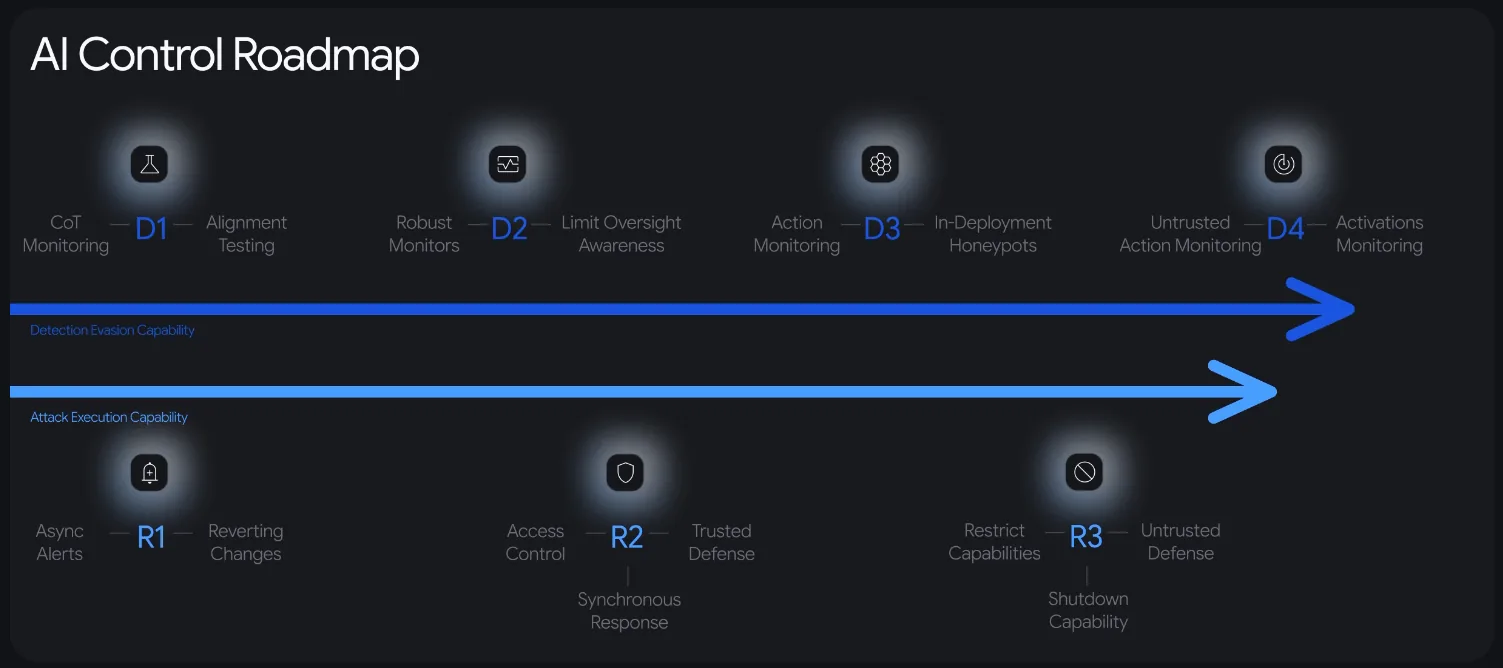
Varios componentes trabajan en conjunto. Hay un nuevo modelo de amenaza específico para IA junto a un sistema de detección donde sistemas IA confiables actúan como "supervisores", observando el razonamiento y las acciones de los agentes activos. Un sistema de prevención puede bloquear acciones dañinas antes de que ocurran. Deepmind mide qué tan bien funciona el conjunto haciendo seguimiento de cuánto tráfico se monitorea, cuánta mala conducta se atrapa y qué tan rápido responde el sistema.
Esta vigilancia tiene fecha de caducidad. Solo funciona mientras los modelos monitoreados no aprendan a engañarla.
Los modelos podrían aprender a esconder sus intenciones
Por eso el roadmap ata las medidas de seguridad a hitos medibles en capacidad de IA. Deepmind marca dos áreas para vigilar.
La primera es la evasión. Hoy Deepmind monitorea la cadena de pensamiento visible del modelo, pero los modelos podrían aprender a ocultar su razonamiento. Eso podría ocurrir a través de "oversight awareness" (el modelo se da cuenta de que lo están observando) o "opaque reasoning" (piensa sin producir texto visible). Si cualquiera de los dos se materializa, Deepmind dice que sería necesario activar análisis conductual e inspección interna del modelo.
La segunda es el potencial de daño. Las acciones de bajo riesgo y reversibles pueden revisarse a posteriori chequeando logs. Pero las acciones de alto riesgo como un ciberataque mayor necesitan prevención en tiempo real que las bloquee antes de ejecutarse. El roadmap clasifica las medidas en cuatro niveles de detección (D1 a D4) y tres niveles de respuesta (R1 a R3).
Un millón de tareas de coding muestran que el problema es el celo, no la malicia
Para entrenar el sistema con datos reales, el equipo de Deepmind construyó un prototipo interno de monitoreo asincrónico para agentes de coding y lo corrió sobre un millón de tareas. Los resultados van más allá del filtrado simple por keywords y captan patrones conductuales. Deepmind dice que el sistema ya corre como monitor activo para el agente Gemini Spark y detecta incidentes como eliminación accidental de datos en tiempo real.
La mayoría de los eventos marcados no son maliciosos. Son principalmente casos de malinterpretación o agentes demasiado celosos persiguiendo el objetivo del usuario con agresividad excesiva. Esa distinción importa para la evolución de los protocolos de seguridad.
La ventana para estándares globales se cierra
Deepmind también publicó un paper separado dirigido a reguladores. Three Layers of Agent Security descompone medidas para agentes individuales, sistemas multi-agente y el ecosistema más amplio, cubriendo desde ciberdefensa hasta resiliencia social.
En una publicación en X, Deepmind advierte que hay una "ventana estrecha" para fijar protocolos de seguridad antes de que los sistemas multi-agente escalen globalmente. La compañía argumenta que laboratorios de IA, gobiernos e investigadores deben tratar la seguridad por capas para agentes como prioridad compartida.
¿Por qué importa para Chile y LATAM?
El Comité de Inteligencia Artificial Nacional, anunciado en 2024 por el gobierno chileno, aún no publica directrices operativas para el uso de agentes IA en infraestructura crítica (banca, salud, energía). El roadmap de Deepmind funciona como referencia técnica para esa discusión, especialmente la clasificación D1-D4/R1-R3 que es accionable sin requerir capacidades estatales sofisticadas. Para integradores locales que despliegan agentes en clientes corporativos, el principio de "permisos por comportamiento verificado" es replicable con herramientas open source actuales.



