
Google está experimentando con cómo los sitios web manejan a los agentes de inteligencia artificial. Lo hace a través de una nueva categoría experimental llamada Agentic Browsing dentro de su herramienta de análisis Lighthouse, según reportó The Decoder.
La categoría se basa en estándares propuestos y aún no es definitiva. Pero ya importa para los usuarios, porque los agentes IA están diseñados para completar formularios, hacer reservas o comparar productos de forma confiable. Eso ocurre siempre que las páginas estén construidas para ser leídas por máquinas.
¿Qué mide exactamente Agentic Browsing?
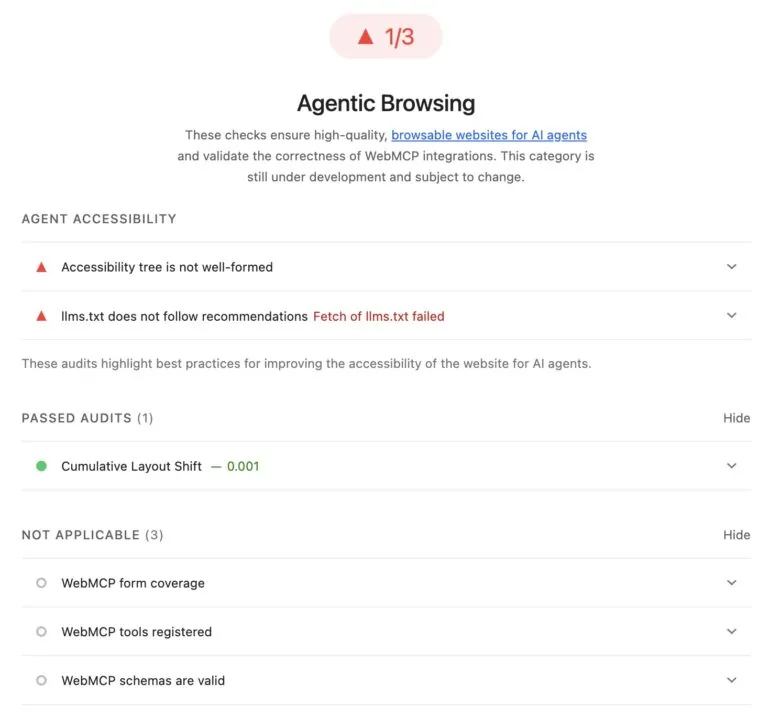
A diferencia de los tests clásicos de Lighthouse, esta categoría no entrega un puntaje de 0 a 100. Solo muestra una proporción de chequeos aprobados. La auditoría cubre cuatro frentes:
- Integración con la API WebMCP de Google, que permite a los desarrolladores exponer lógica y formularios específicamente a los agentes.
- El accessibility tree como modelo de datos central para máquinas (el mismo árbol que ya usan los lectores de pantalla).
- Estabilidad visual medida por Cumulative Layout Shift (CLS), una métrica preexistente de Core Web Vitals.
- Presencia de un archivo llms.txt en la raíz del sitio.
¿Qué pasó cuando se probó con Airbnb?
Airbnb aprueba apenas uno de los tres chequeos disponibles de Agentic Browsing. El accessibility tree no está bien formado, la búsqueda del archivo llms.txt falló y todas las auditorías de WebMCP aparecen como no aplicables.
¿Vale la pena adoptar llms.txt o WebMCP?
El detalle más curioso es que Google mismo considera que llms.txt es inútil para búsqueda con IA. El archivo es uno de los focos centrales del hype actual sobre GEO (Generative Engine Optimization), la supuesta optimización necesaria para que motores generativos rankeen un sitio. Que el propio Google lo incluya en una auditoría y a la vez declare que no le sirve en su pipeline de búsqueda IA es contradictorio. O está validando el estándar por presión externa, o lo evalúa solo para agentes de terceros.
Para preparar un sitio para la era de los agentes, las recomendaciones oficiales de Google son tres y van por el lado clásico:
1. Usar HTML semántico (tags como <article>, <section>, <nav>).
2. Marcar elementos con atributos ARIA apropiados.
3. Reducir layout shifts al mínimo.
Ninguna de las tres requiere adoptar formatos propietarios.
El costo de adaptarse antes de tiempo
Para sitios chilenos y latinoamericanos hay una pregunta práctica: ¿conviene invertir en llms.txt y WebMCP ahora? Considerando que el propio Google duda de la utilidad de llms.txt y que WebMCP es un estándar Google que aún no tiene equivalente en OpenAI o Anthropic, la respuesta más conservadora es esperar. Adoptar HTML semántico y ARIA es trabajo que rinde para SEO clásico, accesibilidad y eventualmente para agentes. El resto es apuesta sobre estándares no consolidados, y la historia reciente del SEO está llena de meta-tags y schemas que un actor empujó y nadie más adoptó.



