
Anthropic anunció este viernes la actualización de su modelo de gama alta a Claude Opus 4.8, una versión que mejora a Opus 4.7 en benchmarks de codificación, razonamiento agéntico y trabajo del conocimiento. La compañía lo lanza al mismo precio del modelo anterior y junto a varias funciones nuevas para usuarios y desarrolladores.
Los usuarios de claude.ai ahora tienen control sobre cuánto esfuerzo dedica Claude a una tarea. Claude Code suma una función llamada dynamic workflows que permite atacar problemas a gran escala. Y el modo rápido para Opus 4.8, donde el modelo trabaja a 2,5× la velocidad, queda tres veces más barato que en versiones anteriores.
¿Qué capacidades trae Opus 4.8?
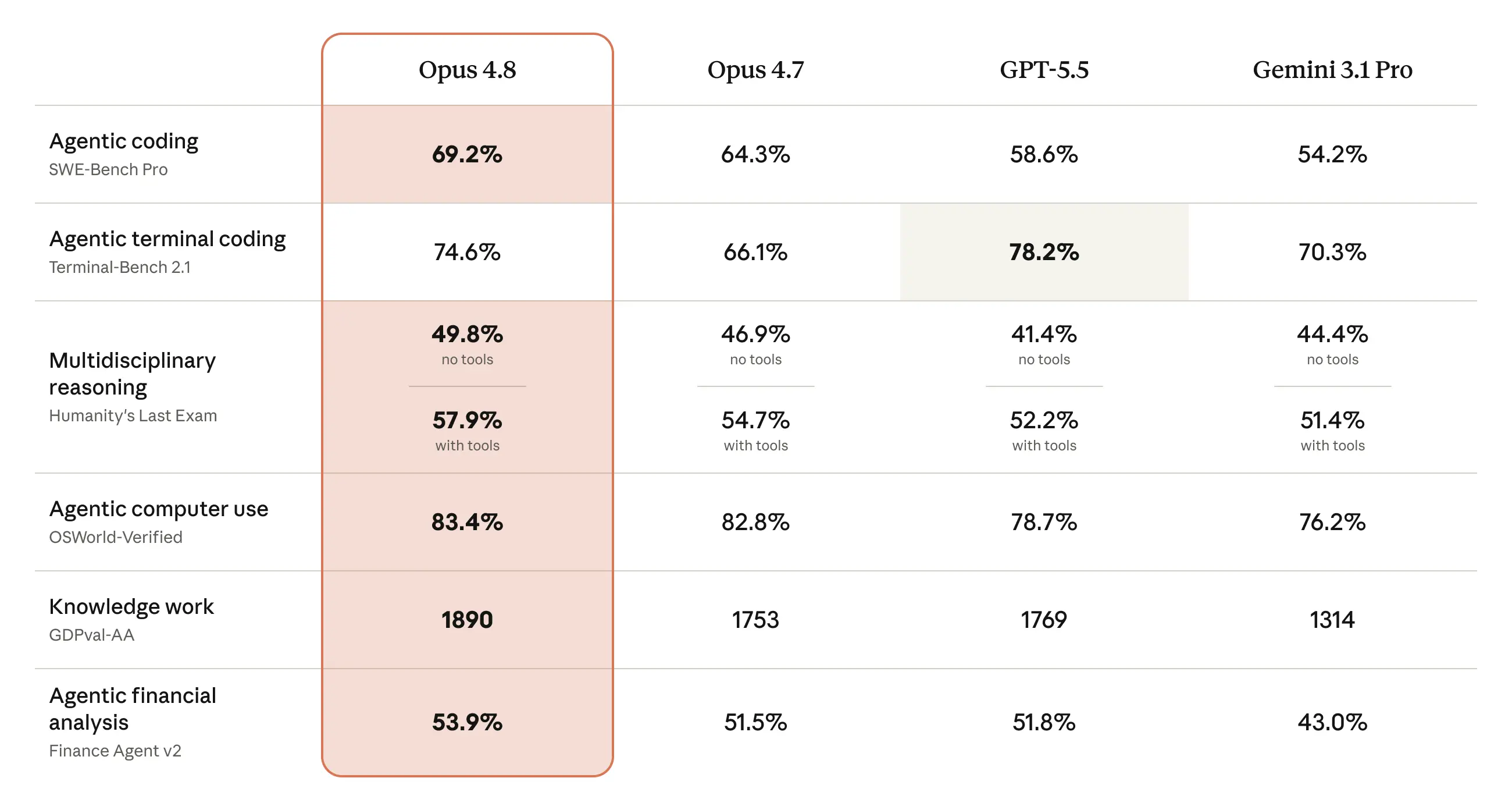
La tabla publicada por Anthropic compara a Opus 4.8 con su predecesor y con otros modelos en pruebas de codificación, habilidades agénticas, razonamiento y tareas prácticas de trabajo del conocimiento. Hay más detalles y un rango más amplio de evaluaciones en el System Card de Claude Opus 4.8.
Lo que dicen los primeros testers
Los testers tempranos describen un modelo más confiable y con mejor criterio en tareas agénticas. Una muestra de citas que Anthropic publicó:

Claude Opus 4.8 tiene un juicio notablemente mejor. En Claude Code hace las preguntas correctas, detecta sus propios errores, contradice cuando un plan no se sostiene y construye confianza alrededor de exploraciones multi-servicio complejas antes de hacer cambios grandes. Es un gran modelo para construir.

En nuestro benchmark Super-Agent, Claude Opus 4.8 es el único modelo que completa cada caso de punta a punta, superando a Opus anteriores y a GPT-5.5 con costo paritario. Para productos agénticos en traducción, investigación profunda, generación de slides y análisis, entrega una confiabilidad poderosa.

En CursorBench, Claude Opus 4.8 supera a los Opus anteriores en cada nivel de esfuerzo. El uso de herramientas es significativamente más eficiente, requiere menos pasos para la misma inteligencia y lleva tareas de punta a punta.

Claude Opus 4.8 es el modelo de uso de computador y agente de navegador más fuerte que hemos probado, anotando 84% en Online-Mind2Web, un salto significativo frente a Opus 4.7 y GPT-5.5. Se mantiene reflexivo y enfocado de la forma que las cargas agénticas de nuestros clientes necesitan para ser confiables de punta a punta.

Claude Opus 4.8 usa herramientas de manera limpia y sigue instrucciones con la consistencia que nuestras cargas de ingeniería autónomas necesitan para correr sin supervisión. Mejora a Opus 4.6 y resuelve los problemas de verbosidad en comentarios y llamadas a herramientas que vimos con Opus 4.7. Este lanzamiento se traduce en avances de capacidad más rápidos para ingenieros que construyen sobre Devin.

Claude Opus 4.8 marca un nuevo estándar para IA empresarial. En Genie, el agente de IA de Databricks para datos y trabajo del conocimiento, el modelo desbloquea un salto de escala en razonamiento agéntico, abordando preguntas multi-paso más profundas, más rápido que cualquier Opus anterior. Su fortaleza multimodal además permite razonar directamente sobre PDFs, diagramas y otro contenido no estructurado con un costo por token 61% más bajo que Opus 4.7.
¿Por qué importa la honestidad del modelo?
Una de las mejoras más prominentes en Opus 4.8 es su honestidad. Anthropic entrena a sus modelos para evitar afirmaciones que no pueden sostener, pero un problema general de los modelos de IA es que a veces saltan a conclusiones, asegurando con confianza haber hecho progreso cuando la evidencia es delgada. Los testers tempranos reportan que Opus 4.8 es más probable de señalar incertidumbres sobre su trabajo y menos probable de hacer afirmaciones no respaldadas. Esto se confirma en las evaluaciones de Anthropic, que muestran que Opus 4.8 es alrededor de cuatro veces menos probable que su predecesor de dejar pasar fallas en código que escribió sin marcarlas.
Antes del lanzamiento Anthropic corrió una evaluación detallada de alineamiento. En rasgos positivos, el equipo de Alignment concluyó que Opus 4.8 "alcanza nuevos máximos en nuestras medidas de rasgos pro-sociales como apoyar la autonomía del usuario y actuar en su mejor interés". La evaluación además mostró tasas de comportamiento desalineado, como engaño o cooperación con uso indebido, sustancialmente menores que Opus 4.7 y similares al modelo mejor alineado de la compañía, Claude Mythos Preview.
También se lanza hoy
Junto con Claude Opus 4.8, Anthropic anunció las siguientes actualizaciones:
- Dynamic workflows. Esta función nueva, disponible en research preview, permite a Claude asumir tareas aún más grandes en Claude Code. Claude puede planificar el trabajo y luego correr cientos de sub-agentes en paralelo en una misma sesión (y con Opus 4.8 los agentes pueden correr por más tiempo). Luego verifica sus salidas antes de reportar al usuario. Por ejemplo, Claude Code con Opus 4.8 puede ejecutar migraciones a escala de codebase a través de cientos de miles de líneas de código desde el kickoff hasta el merge, usando el test suite existente como vara. Hay más detalles disponibles para los planes Enterprise, Team y Max en este post.
- Control de esfuerzo en claude.ai y Cowork. Un control nuevo junto al selector de modelo permite a los usuarios elegir cuánto esfuerzo pone Claude en una respuesta. En niveles más altos Claude piensa con más frecuencia y profundidad para dar mejores respuestas. En niveles bajos responde más rápido y usa más lento sus límites de tasa. La función está disponible en todos los planes.
- La Messages API ahora acepta entradas de sistema dentro del arreglo de mensajes. Los desarrolladores pueden actualizar las instrucciones de Claude a mitad de una tarea sin romper el caché del prompt ni rutear la actualización a través de un turno de usuario. Sirve para actualizar permisos, presupuestos de tokens o contexto de entorno mientras un agente corre.
¿Cuánto cuesta y dónde se accede?
Claude Opus 4.8 está disponible en todas partes desde hoy. El precio para uso regular no cambia respecto a Opus 4.7: USD 5 por millón de tokens de entrada y USD 25 por millón de tokens de salida. El precio del modo rápido es USD 10 por millón de entrada y USD 50 por millón de salida. Los desarrolladores pueden usarlo vía el identificador claude-opus-4-8 en la Claude API.
Opus 4.8 corre por defecto en alto esfuerzo, el balance que Anthropic considera óptimo entre calidad y experiencia. En tareas de codificación ese nivel gasta una cantidad de tokens similar al default de Opus 4.7 pero con mejor rendimiento. Los usuarios pueden elegir "extra" (xhigh en Claude Code) o "max", y el modelo gastará más tokens para obtener mejores resultados.
¿Qué viene después?
Anthropic adelantó que trabaja en modelos que entreguen muchas de las mismas capacidades de Opus a menor costo. Además, planea liberar una clase nueva de modelo con inteligencia incluso mayor que Opus. Como parte de Project Glasswing, un grupo reducido de organizaciones está usando Claude Mythos Preview para trabajo de ciberseguridad. Los modelos de ese nivel de capacidad requieren salvaguardas cibernéticas más fuertes antes de su liberación general, y la compañía espera traer modelos de clase Mythos a todos sus clientes "en las próximas semanas".
Para desarrolladores en LatAm
Para equipos chilenos y latinoamericanos que ya consumen la Claude API vía Bedrock o Vertex, la migración a claude-opus-4-8 no exige cambios de schema. El factor relevante es el ahorro: el costo de PDFs y diagramas (multimodal) bajó 61% según el caso de Databricks, y el modo rápido pasó a USD 10/USD 50 por millón de tokens, un tercio del precio anterior. En equipos de ingeniería que corren agentes 24/7, la diferencia mensual se traduce directamente en runway extendido.



