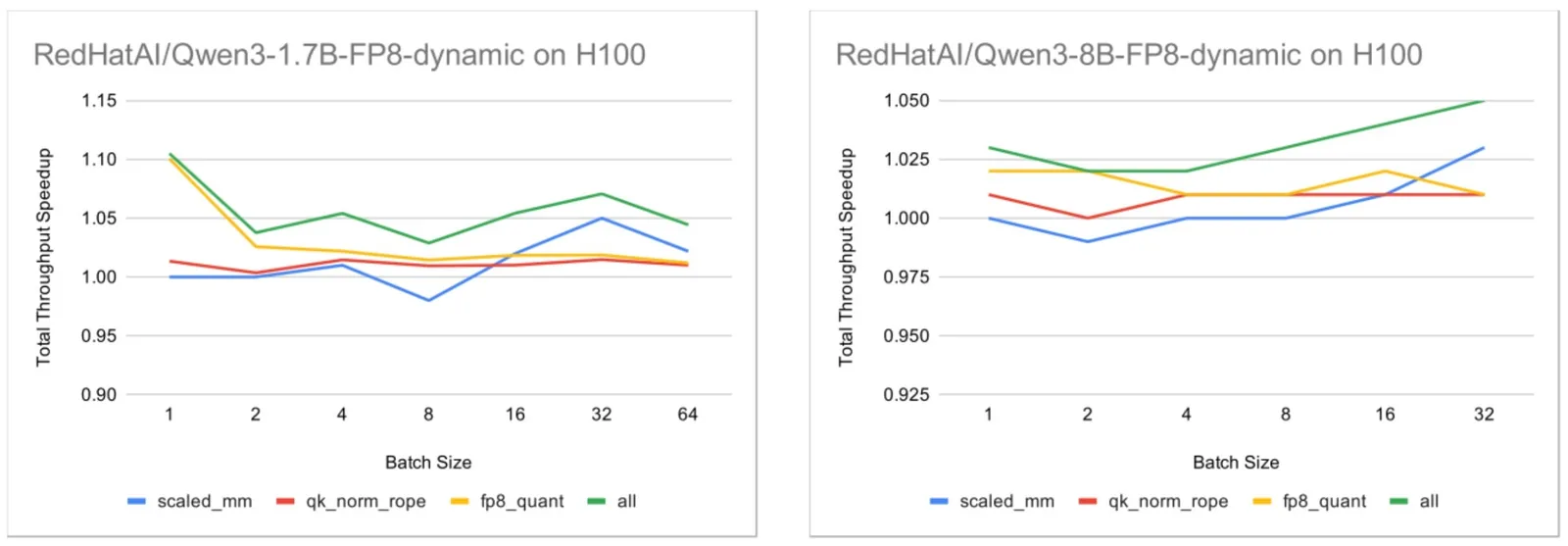
A medida que los LLM transicionan de la simple generación de texto al razonamiento complejo, el aprendizaje por refuerzo (RL) desempeña un papel central. Algoritmos como la Optimización de Política Relativa de Grupo (GRPO) impulsan esta transición, permitiendo que los modelos de grado de razonamiento mejoren continuamente a través de una retroalimentación iterativa. A diferencia del ajuste fino supervisado estándar, los bucles de entrenamiento de RL se bifurcan en dos fases distintas y de alta intensidad: una fase de generación con un requisito de latencia estricto y una fase de entrenamiento que requiere un alto throughput.
Para hacer que estas cargas de trabajo sean viables, los investigadores e ingenieros están recurriendo a tipos de datos de baja precisión como FP8 para potenciar el rendimiento en el entrenamiento y en la generación orientada al throughput. Además, en algunos escenarios donde la generación está limitada por el ancho de banda de la memoria de la GPU, el uso de parámetros de baja precisión puede mejorar el rendimiento debido a la menor cantidad de bytes por parámetro.
Este artículo profundiza en los desafíos sistémicos del RL de baja precisión y en cómo NVIDIA NeMo RL —una biblioteca de código abierto dentro del framework NVIDIA NeMo— acelera las cargas de trabajo de RL mientras mantiene la precisión.
FP8 para capas lineales en RL
Nuestra receta utiliza la cuantización FP8 por bloques introducida por el Informe Técnico de DeepSeek-V3. La Tabla 1 proporciona los detalles de los formatos de tensores en las capas de proyección lineal.
Con esta receta, las capas lineales se pueden computar con matemática FP8, que tiene el doble de throughput máximo en comparación con la matemática BF16. Otros módulos, incluyendo la atención, la normalización, las funciones no lineales y las proyecciones de salida, se computan con matemática BF16.
El desafío del desacuerdo numérico en RL
Los pipelines de RL suelen utilizar motores separados: vLLM para los rollouts y NVIDIA Megatron Core para el entrenamiento. Cada uno utiliza kernels de NVIDIA CUDA personalizados y únicos para maximizar el rendimiento. Esto introduce inherentemente diferencias numéricas que se magnifican acumulativamente en precisiones más bajas debido a la lógica adicional de cuantización y descuantización. Cuantificamos esta diferencia numérica como un error de probabilidad multiplicativa de tokens:
\(\texttt{token-mult-prob-error} = \frac{1}{n}\sum_{i=1}^{n(\texttt{tokens})}exp(\left| \texttt{log-train-fwk}_i – \texttt{logprobs-inference-fwk}_i \right|)\)
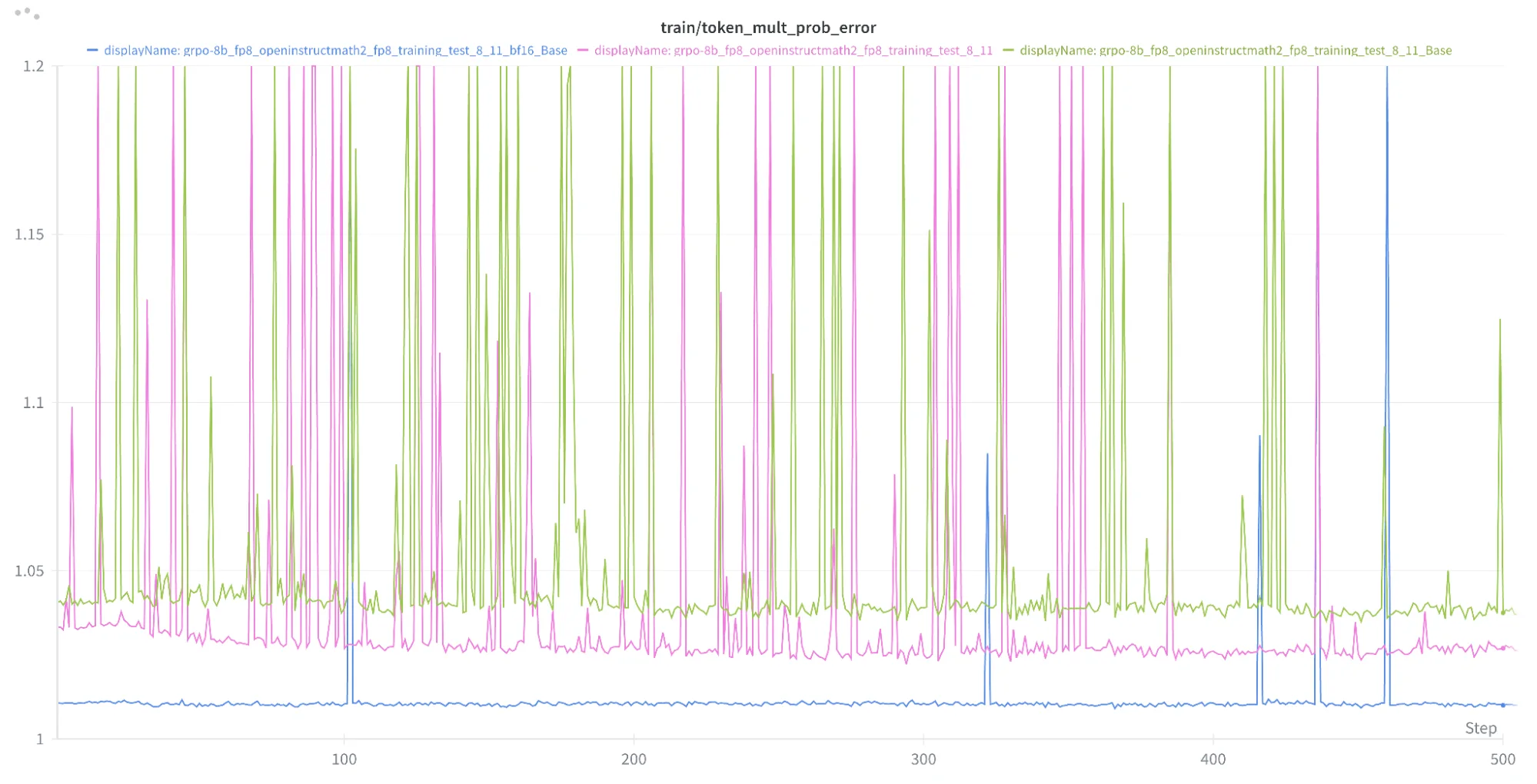
Una alineación perfecta obtiene una puntuación de 1, y normalmente consideramos que los valores 'aceptables' son inferiores a 1.03-1.05 cuando no se utilizan técnicas adicionales.
FP8 de extremo a extremo en capas lineales reduce el desacuerdo numérico
Durante el desarrollo de la receta FP8, experimentamos con tres variantes:
- Receta base: BF16 tanto para la generación como para el entrenamiento.
- Candidata a receta 1: FP8 se aplica exclusivamente durante la generación, mientras que el entrenamiento del modelo de política se realiza en BF16.
- Receta final: FP8 de extremo a extremo: utilizamos FP8 tanto en los motores de generación como en los de entrenamiento.
Observamos que, en comparación con la candidata a receta 1 con FP8 solo para la generación, la receta final muestra consistentemente un menor desacuerdo numérico entre la generación y el entrenamiento. Cabe notar que la receta base siempre ofrece el desacuerdo numérico más bajo. La Figura 1 muestra la métrica del error de probabilidad multiplicativa de tokens de las tres recetas.
Mitigando el desacuerdo numérico con muestreo por importancia
El muestreo por importancia (importance sampling) se utiliza para corregir el desajuste de distribución entre el modelo (es decir, la distribución) que genera los datos y el modelo (la distribución) que se está entrenando. Es un peso por token multiplicado por la pérdida. Puede consultar nuestra documentación de GRPO para obtener el trasfondo teórico detallado del muestreo por importancia.
Los experimentos muestran que:
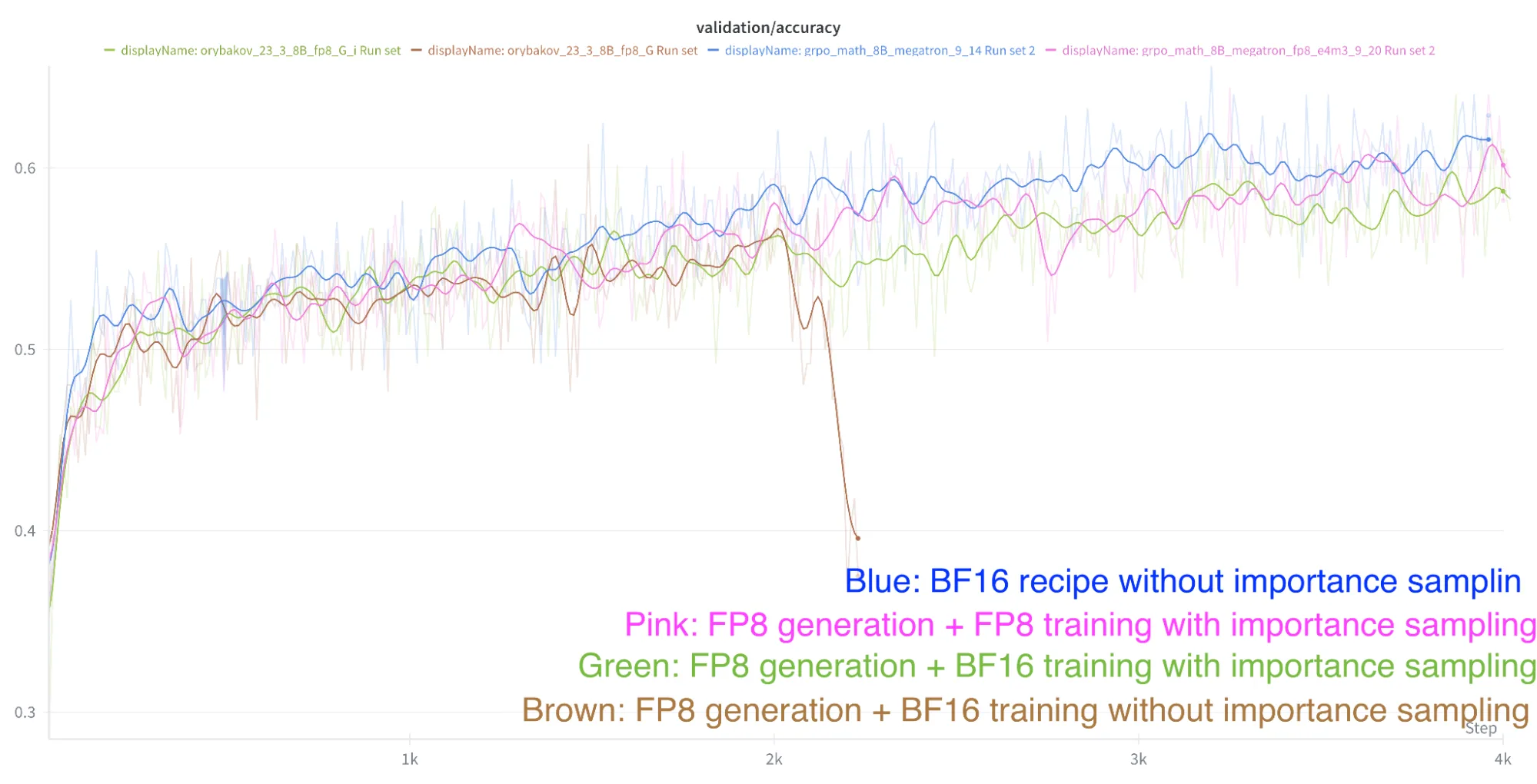
- Para la candidata a receta 1 (generación en FP8 y entrenamiento en BF16), el muestreo por importancia puede reducir la brecha de precisión respecto al RL en BF16, pero no puede cerrarla por completo.
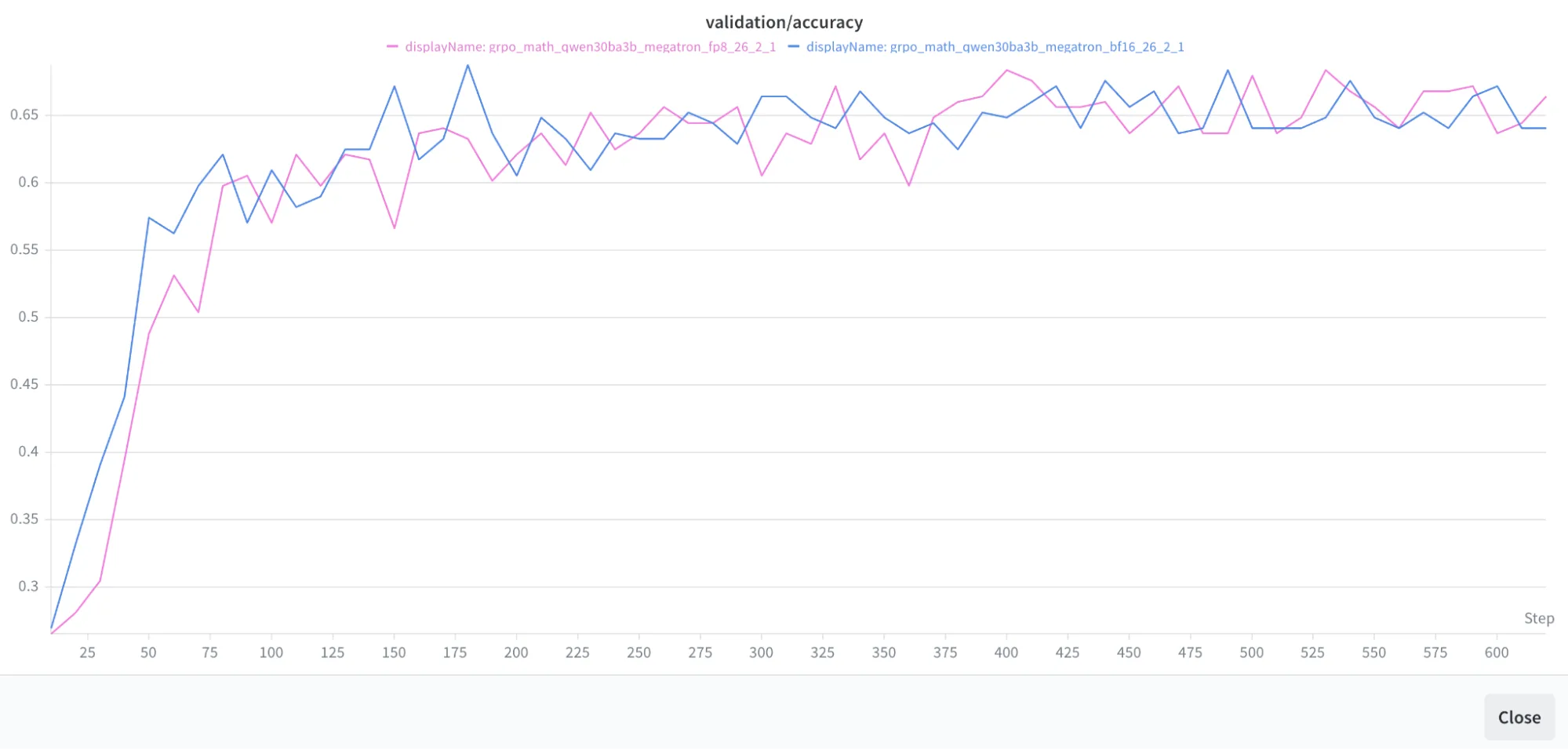
- Para la receta final (FP8 de extremo a extremo), el muestreo por importancia cierra completamente la brecha respecto al entrenamiento en BF16. La Figura 2 muestra la precisión de validación durante el entrenamiento para diferentes recetas.
Resultados para el FP8 lineal de extremo a extremo
Evaluamos la receta FP8 de extremo a extremo tanto en modelos densos como en modelos de mezcla de expertos (MoE), midiendo la precisión de validación y el throughput de entrenamiento frente a la línea base de BF16.
FP8 de extremo a extremo en modelos densos: Llama 3.1 8B Instruct
La Tabla 2 muestra la precisión de la receta FP8 de extremo a extremo y la receta BF16 en el entrenamiento GRPO del modelo Llama 3.1 8B instruct y el dataset de matemáticas entrenado hasta los 4000 pasos.
En términos de aceleración, la receta FP8 logra una mejora consistente de más del 15% en el throughput en comparación con BF16. La Figura 3 muestra el entrenamiento GRPO (tokens por segundo por GPU) de las dos recetas a lo largo de 1000 pasos.
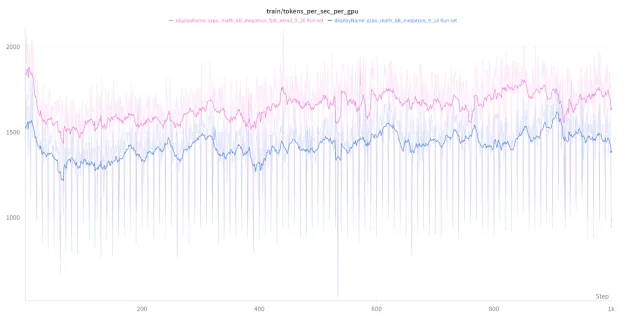
Aunque la aceleración teórica de FP8 sobre BF16 es de 2x, en la práctica es menor porque solo las capas lineales se benefician de un throughput matemático más rápido, mientras que las capas de atención y elementwise se mantienen iguales. Los kernels de cuantización adicionales añadidos antes de las capas lineales introducen cierta sobrecarga. La aceleración del 15%-25% coincide con nuestras pruebas independientes de vLLM. Con optimizaciones adicionales, como la fusión de kernels de cuantización en vLLM, proyectamos que la aceleración puede mejorar aún más hasta 1.25x.
FP8 de extremo a extremo en modelos MoE: Qwen3-30B
Se realizaron experimentos similares en modelos de mezcla de expertos (MoE), con resultados para Qwen3-30B que muestran curvas de precisión coincidentes. FP8 logra una precisión similar a BF16. La ganancia de velocidad está siendo investigada.
Extendiendo FP8 para KV cache y atención
Con un modelo transformer, las capas lineales no son el único cuello de botella. El crecimiento de la KV cache y el cómputo de la atención a menudo dominan el tiempo de rollout de extremo a extremo en los flujos de trabajo de RL con longitudes de secuencia de salida (OSL) largas, al tiempo que saturan el ancho de banda de la memoria y ralentizan la generación de tokens. Esto nos motivó a explorar FP8 para la KV cache y la atención en el bucle de RL. Se utiliza FP8 con escalado por tensor.
Implementar FP8 para la KV cache en un entorno de RL es un desafío único porque los pesos de la política cambian en cada paso. A diferencia de la inferencia estática, donde la calibración ocurre una sola vez, el RL requiere un manejo dinámico de las escalas de cuantización.
NeMo RL adopta el siguiente enfoque para resolver esto:
- Recalibración: Al final de cada paso de entrenamiento, el entrenador recalibra las escalas de Query, Key y Value (QKV) utilizando los pesos de política actualizados.
- Selección de datos: Esta calibración se realiza utilizando los datos de entrenamiento (prompts y respuestas generadas) para asegurar que las escalas reflejen la distribución actual.
- Sincronización: Las escalas recién calculadas se sincronizan luego con el motor de inferencia (vLLM) para la fase de rollout subsiguiente.
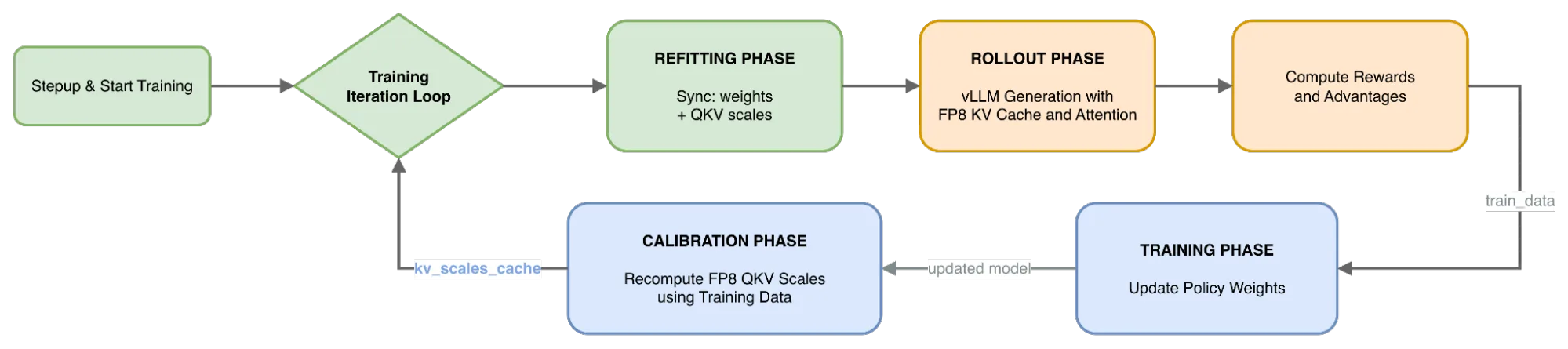
Este diseño garantiza que el motor de rollout siempre utilice las escalas de cuantización óptimas derivadas del estado más reciente de la política, minimizando la degradación de la precisión. La sobrecarga de calibración es mínima, consumiendo aproximadamente el 2-3% del tiempo total del paso.
Resumen de resultados para FP8 en KV cache y atención
Ejecutamos resultados en el modelo Qwen3-8B-Base utilizando el algoritmo GRPO, con FP8 aplicado en el rollout y BF16 para el entrenamiento. Si bien la divergencia KL por desajuste es ligeramente superior al cuantizar tanto la KV cache como la atención...
Vía NVIDIA Developer.