
DeepSeek acaba de lanzar su cuarta generación de modelos insignia con DeepSeek-V4-Pro y DeepSeek-V4-Flash, ambos orientados a permitir una inferencia de contexto de millones de tokens altamente eficiente.
DeepSeek-V4-Pro es el modelo más grande de la familia, con 1.6 billones (1.6T) de parámetros totales y 49 mil millones (49B) de parámetros activos. DeepSeek-V4-Flash es un modelo más pequeño de 284 mil millones (284B) de parámetros con 13 mil millones (13B) de parámetros activos, diseñado para cargas de trabajo de mayor velocidad y eficiencia. Ambos modelos admiten una ventana de contexto de hasta 1 millón de tokens, abriendo nuevas posibilidades para la programación con contexto largo, análisis de documentos, recuperación y flujos de trabajo de IA agéntica.
Innovaciones arquitectónicas para la inferencia de contexto largo
La familia V4 se basa en la arquitectura MoE de DeepSeek, con un mayor enfoque en la optimización del componente de atención de la arquitectura transformer. Estas innovaciones están diseñadas para lograr una reducción del 73% en los FLOPs de inferencia por token y una reducción del 90% en la carga de memoria del caché KV en comparación con DeepSeek-V3.2.
Eso es importante porque el contexto largo se está convirtiendo en un requisito central para las aplicaciones agénticas. Los agentes almacenan más que un simple prompt y su respuesta. Llevan instrucciones del sistema, salidas de herramientas, contexto recuperado, código, registros, memoria y trazas de razonamiento de múltiples pasos a lo largo de un flujo de trabajo. A medida que crecen las ventanas de contexto, la atención y el caché KV se convierten en importantes cuellos de botella.
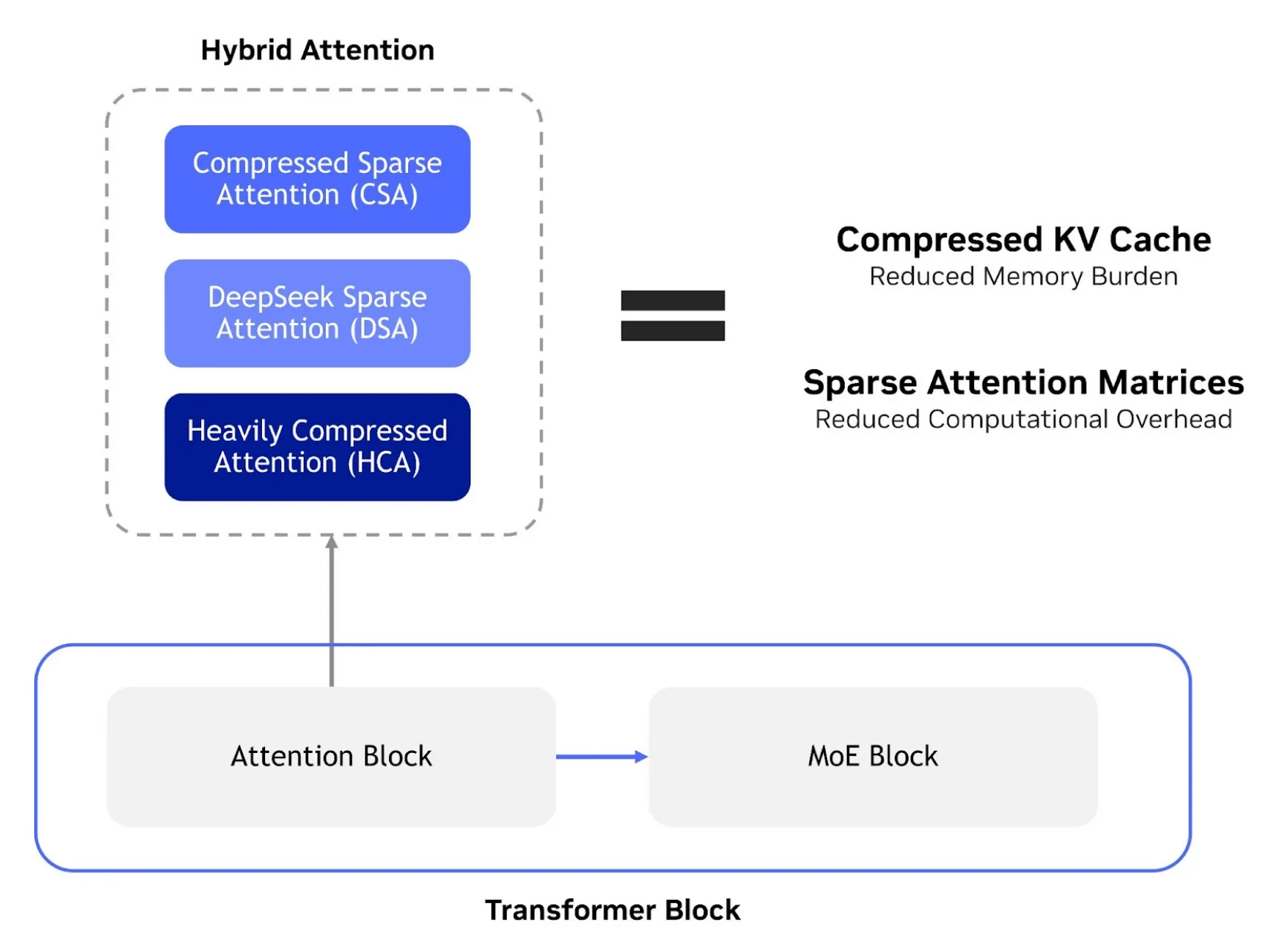
La solución arquitectónica central para estos desafíos es la atención híbrida (hybrid attention), que combina:
- Atención dispersa comprimida (Compressed Sparse Attention o CSA): Aprovecha la compresión dinámica de secuencias para comprimir las entradas KV con el fin de reducir la huella de memoria del caché KV, y luego aplica la Atención Dispersa de DeepSeek (DSA) para hacer más dispersas las matrices de atención y reducir la sobrecarga computacional.
- Atención fuertemente comprimida (Heavily Compressed Attention o HCA): Aplica una compresión mucho más agresiva al consolidar las entradas KV a través de conjuntos de tokens en una sola entrada comprimida, lo que resulta en una reducción significativa en el tamaño del caché KV.
Las innovaciones arquitectónicas de DeepSeek-V4 señalan un cambio desde el chat básico hacia la inferencia de múltiples turnos y contexto largo, y sistemas agénticos. Este nuevo paradigma presiona toda la pila (software, memoria, cómputo y redes), alterando fundamentalmente la dinámica de la economía de la inferencia. A medida que los modelos abiertos alcanzan la frontera de la inteligencia, el enfoque empresarial está pivotando desde la selección de modelos hacia la estrategia de infraestructura. En este panorama, la ventaja competitiva definitiva es la capacidad de implementar (deployment) y escalar estos modelos de alto rendimiento al menor costo por token.
Datos de rendimiento listos para usar con NVIDIA Blackwell
Ya sea que los desarrolladores estén implementando el modelo Pro de 1.6T para razonamiento avanzado o el modelo Flash de 284B para eficiencia de alta velocidad, Blackwell proporciona la escala y el rendimiento de baja latencia requeridos para una nueva era de inferencia de contexto largo de 1M y de inteligencia de billones de parámetros.
La plataforma NVIDIA Blackwell está construida para esta clase de cargas de trabajo. Las pruebas listas para usar (out-of-the-box) de DeepSeek-V4-Pro en NVIDIA GB200 NVL72 demuestran más de 150 tokens/segundo/usuario. Además de estas pruebas iniciales, el equipo de NVIDIA aprovechó la receta del Día 0 de NVIDIA Blackwell B300 de vLLM para producir una instantánea del rendimiento listo para usar en todo el frente de Pareto (Figura 2).
Se espera que este rendimiento aumente aún más a medida que optimicemos toda nuestra pila de codiseño extremo: Dynamo, NVFP4, kernels CUDA optimizados, técnicas avanzadas de paralelización y más.
Construye con endpoints acelerados por GPU de NVIDIA
Los desarrolladores pueden comenzar a construir con DeepSeek V4 a través de endpoints acelerados por GPU de NVIDIA en build.nvidia.com como parte del NVIDIA Developer Program. Los endpoints alojados proporcionan una forma rápida de crear prototipos con los modelos más recientes antes de pasar a rutas de implementación autoalojadas.
DeepSeek V4 también está disponible para descargar el día 0 con NVIDIA NIM, de modo que se puede implementar para construir programación de contexto largo, análisis de documentos y flujos de trabajo agénticos utilizando patrones de API familiares.
Implementación con SGLang
SGLang ofrece tres recetas principales de servicio para DeepSeek‑V4 en NVIDIA Blackwell y Hopper, cada una ajustada para un perfil diferente de latencia/rendimiento (baja latencia, equilibrado y rendimiento máximo), junto con recetas especializadas para cargas de trabajo de contexto largo y para la desagregación de prefill/decode.
Implementación con vLLM
vLLM proporciona recetas de servicio de un solo nodo y multinodo de DeepSeek‑V4 para NVIDIA Blackwell y Hopper, incluyendo recetas de desagregación de prefill/decode multinodo que escalan hasta más de 100 GPUs, con soporte para llamadas a herramientas (tool calling), razonamiento y decodificación especulativa.
Impulsando flujos de trabajo agénticos
DeepSeek V4 es especialmente excelente para agentes, ya que sobresale en la orquestación de contexto largo, razonamiento y llamadas a herramientas. Para comenzar, los desarrolladores pueden configurar DeepSeek V4 como el LLM:
- NVIDIA NemoClaw: Ejecuta OpenClaw en un entorno seguro OpenShell para crear un asistente personal de ejecución prolongada impulsado por DeepSeek V4 para tareas como generación de código, asistente personal, soporte autónomo y más. Ejecuta
nemoclaw onboardy durante el paso 3, ingresa la URL de tu proveedor de DeepSeek V4 y el nombre de su modelo DeepSeek V4.
- NVIDIA AI-Q Blueprint: El blueprint pone a tu disposición o a la de tus agentes un asistente de investigación profunda de primer nivel. El blueprint, basado en LangChain Deep Agents, es extensible, lo que facilita agregar DeepSeek V4 a tu flujo de trabajo para orquestación y planificación.
- NVIDIA Data Explorer Agent: El agente ganó el 1er lugar en el benchmark DABstep; sobresale en análisis de datos, ciencia de datos e investigación tabular. El agente está escrito con el NeMo Agent Toolkit, lo que facilita cambiar para usar DeepSeek V4.
La mejor parte de usar entornos de agentes abiertos y modelos abiertos es que siempre puedes probar nuevos modelos para estar a la vanguardia.
Comienza con DeepSeek
Desde implementaciones en centros de datos con NVIDIA Blackwell hasta microservicios gestionados NIM y flujos de trabajo de fine-tuning, NVIDIA proporciona una gama de opciones para integrar DeepSeek y otros modelos abiertos en diferentes etapas de desarrollo e implementación. NVIDIA es un contribuyente activo al ecosistema open-source y ha lanzado varios cientos de proyectos bajo licencias de código abierto. NVIDIA está comprometida con la optimización del software comunitario, y los modelos abiertos permiten a los usuarios compartir ampliamente el trabajo en seguridad y resiliencia de IA.
Para comenzar, revisa DeepSeek-V4 en Hugging Face o prueba la versión pro en build.nvidia.com.
Vía NVIDIA Developer.



