Puntos clave
- Investigadores de Nvidia presentan Lyra 2.0, un sistema que genera entornos 3D coherentes con una extensión de hasta 90 metros a partir de una sola foto.
- El sistema almacena la geometría 3D ya generada como orientación y se entrena específicamente contra pérdidas de calidad para resolver dos debilidades centrales de los modelos de video anteriores.
- Según Nvidia, Lyra 2.0 supera a seis competidores y puede exportar las escenas generadas a motores de física como Isaac Sim para entrenar robots en entornos generados.
Investigadores de Nvidia han revelado Lyra 2.0, un sistema que genera grandes entornos 3D coherentes a partir de una sola fotografía. Las escenas resultantes pueden explorarse en tiempo real y usarse directamente en simulaciones de robots.
Los modelos de IA existentes para la generación de escenas 3D tienen dificultades con trayectorias de cámara largas: cuanto más se aleja la cámara virtual de su punto de partida, más se distorsionan los colores y las estructuras. Cuando la cámara regresa a una ubicación vista previamente, el modelo a menudo reinventa el entorno desde cero. Los investigadores de Nvidia buscan resolver este problema con Lyra 2.0.
El sistema toma una sola foto y genera videos controlados por cámara que simulan un recorrido virtual por una escena. Estos videos luego se convierten automáticamente en representaciones 3D que pueden visualizarse en tiempo real y utilizarse en entornos de simulación. Según el artículo de investigación, las escenas generadas pueden abarcar aproximadamente 90 metros.
Cómo Lyra 2.0 soluciona los dos mayores problemas en la generación de escenas 3D
Los modelos de video actuales fallan en dos desafíos fundamentales, según los investigadores. Primero, el modelo olvida las áreas vistas previamente en cuanto salen del encuadre. Segundo, los pequeños errores se acumulan durante la generación de video paso a paso, convirtiéndose en distorsiones significativas con el tiempo.
Para abordar el primer problema, Lyra 2.0 almacena la geometría 3D para cada cuadro generado. Cuando la cámara se mueve de regreso hacia un área visitada anteriormente, el sistema recupera los cuadros anteriores y utiliza su información espacial como referencia. El modelo de video sigue encargándose de la generación real de la imagen, lo que significa que los errores en la geometría almacenada no se transfieren directamente a los nuevos cuadros.
Para evitar la desviación (drift), los investigadores exponen deliberadamente el modelo a sus propios resultados defectuosos durante el entrenamiento. Esto le enseña a reconocer y corregir la degradación de calidad en lugar de transmitir los errores.
Lyra 2.0 supera a seis métodos de la competencia
En pruebas de rendimiento sobre dos conjuntos de datos, Lyra 2.0 supera a otros seis métodos —incluyendo GEN3C, Yume-1.5 y CaM— en casi todos los criterios medidos, como calidad de imagen, consistencia de estilo y control de cámara, según Nvidia. Una variante más rápida del modelo genera videos aproximadamente 13 veces más rápido con una calidad comparable.
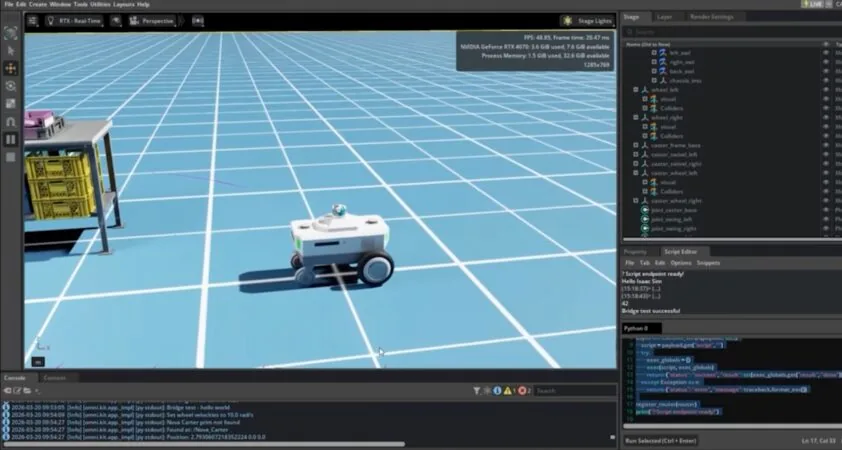
Las escenas 3D generadas pueden explorarse paso a paso a través de una interfaz interactiva y exportarse como mallas (meshes) a motores de física como Nvidia Isaac Sim. Esto podría permitir que los robots se entrenen en entornos completamente generados sin necesidad de capturar datos 3D del mundo real, afirma la compañía. Por ahora, sin embargo, Lyra 2.0 solo soporta escenas estáticas.
Noticias de IA sin exageraciones
Suscríbete a THE DECODER para una lectura sin anuncios, un boletín semanal sobre IA, nuestro informe exclusivo "AI Radar" seis veces al año, acceso completo al archivo y acceso a nuestra sección de comentarios.
Vía The Decoder.