El equipo oficial de PyTorch publicó en su blog una guía extensa sobre cómo funciona la infraestructura de pruebas del framework, después de que muchos contribuidores nuevos se toparan repetidamente con la misma frustración. Ejecutar un test por el nombre que aparece en el archivo fuente devuelve "no tests collected", pero en CI el mismo test falla con un nombre completamente distinto como TestLinalgCUDA.test_matmul_cuda_float32.
TL;DR
- Los tests de PyTorch se generan en tiempo de import, por lo que los fallos de CI muestran nombres con sufijos de device y dtype que difieren del template del archivo fuente.
- Para debug local,
pytest -kytest/run_test.pyson las rutas más rápidas para reproducir un fallo generado. - Los tests device-generic, los metadatos de operadores expuestos vía OpInfos y el sharding de CI son las tres piezas clave que hay que entender para contribuir o debuggear tests de PyTorch.
¿Por qué los tests de PyTorch se sienten distintos?
La infraestructura de tests de PyTorch está construida para escalar. Dependiendo de los decoradores usados y de los metadatos de operadores expuestos vía OpInfos, un único método de test puede expandirse automáticamente en muchos devices, dtypes y operadores. Eso es lo que le permite a PyTorch validar miles de combinaciones sin escribir miles de tests a mano. Pero también significa que el test escrito en el archivo fuente no siempre es el test exacto que corre en CI.
Muchos helpers que discute la guía viven bajo torch.testing._internal, la infraestructura interna de tests del proyecto. Si el objetivo es probar código propio fuera del repo, PyTorch recomienda usar APIs públicas como pytest y torch.testing.assert_close.
El misterio del "no tests collected"
Uno de los primeros momentos confusos para nuevos contribuidores es tratar de correr un test por el nombre de clase y método que ven en el archivo:
pytest test/test_torch.py::TestTorch::test_matmulEn muchos archivos de test esto responde "no tests collected". Y no es porque el test no exista. Es porque la clase del archivo fuente es un template, no la clase final que ve el runner. Cuando se importa el archivo, instantiate_device_type_tests() expande el template en clases concretas por device como TestTorchCPU, TestTorchCUDA o TestTorchMPS. Si el test también está parametrizado por dtype, el método generado incluye el device y el dtype en el nombre, por ejemplo test_matmul_cuda_float32.
Para debug local suele ser más fácil filtrar por patrón de nombre generado que apuntar directo a la clase template:
pytest test/test_torch.py -k "test_matmul"
pytest test/test_torch.py -k "test_matmul_cuda_float32"Cómo funcionan los tests device-generic
PyTorch corre sobre CPU, CUDA, MPS y XPU, y muchos tests necesitan validar comportamiento en float16, float32, float64, bfloat16 y varios enteros. Escribir un test separado por cada combinación de device y dtype se vuelve rápidamente inmantenible. La solución que adoptó PyTorch son los templates de test. El contribuidor escribe un solo método con parámetros de device y dtype:
def test_basic(self, device, dtype):
...Cuando Python importa el archivo, instantiate_device_type_tests() expande ese template sobre los device types y dtypes seleccionados. Una sola clase template puede producir TestMatmulCPU, TestMatmulCUDA y TestMatmulMPS, con métodos como test_basic_cuda_float32.
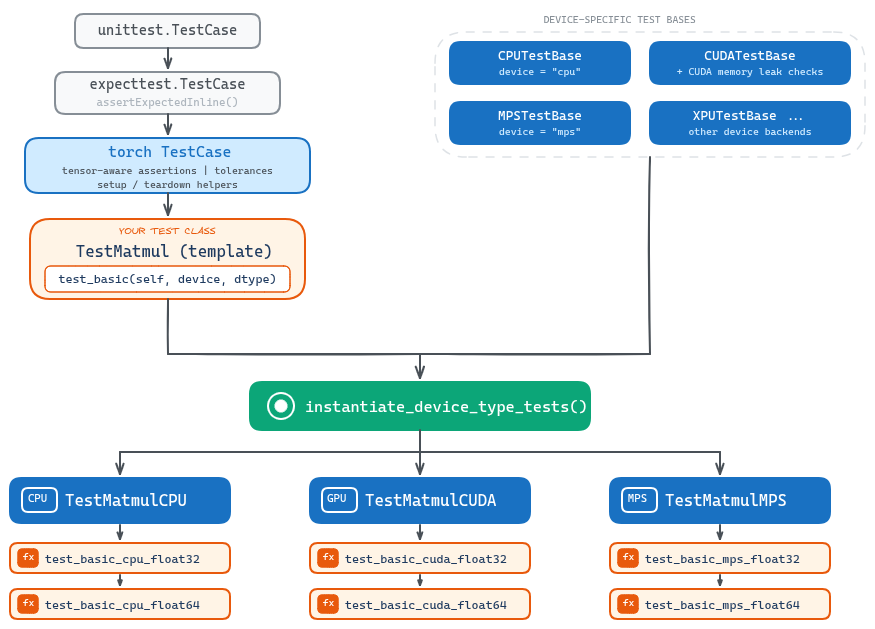
El patrón de los nombres generados es:
<ClassName><DEVICE>.<method>_<device>_<dtype>Un template como TestMatmul.test_basic termina como TestMatmulCUDA.test_basic_cuda_float32. El device aparece en mayúscula en la clase y en minúscula en el método. Por eso los fallos de CI muestran nombres generados en vez del template. El nombre generado dice exactamente qué device y qué dtype falló.
La arquitectura a vista de pájaro
La infraestructura de tests se entiende mejor pensándola como capas conectadas. Los contribuidores interactúan típicamente con las capas del medio: instantiation por device, decoradores de parametrización, OpInfos y utilidades de test. La orquestación de CI queda por encima, y las utilidades base proveen el cimiento compartido.

OpInfos: testeo de operadores por metadatos
Los OpInfos son entradas de metadatos que describen cómo debe testearse un operador de PyTorch. En vez de escribir un test separado por cada operador, PyTorch usa templates genéricos que leen los OpInfos y corren los mismos chequeos sobre muchos operadores.
Un OpInfo define nombre del operador, variantes, dtypes soportados, sample inputs, skips esperados, decoradores y reglas de tolerancia. Los tests genéricos en archivos como test_ops.py consumen op_db vía el decorador @ops(...), que pasa el operador, device y dtype seleccionados al test. Así una sola entrada por operador participa en distintos tipos de cobertura: forward correctness, dtype/device behavior, gradient checks, caminos relacionados con compile, y validación estilo Meta/FakeTensor.
Cuando aparece un test generado como TestCommonCUDA.test_variant_consistency_eager_torch_matmul_cuda_float32, típicamente significa que un test genérico basado en OpInfo está corriendo contra el OpInfo de torch.matmul para un device y dtype específicos.
El decorador @ops(...) es un ejemplo del patrón más amplio de parametrización. Para casos no relacionados con operadores hay @parametrize(...), y para tests específicos de módulos existe @modules. La idea es la misma en los tres: mantener un solo cuerpo de test y dejar que la infraestructura genere las combinaciones útiles.
Correr tests en local
Para debug del día a día conviene arrancar con pytest -k. Funciona bien con los nombres generados y evita depender de nombres de clases template que ya no están directamente disponibles.
pytest test/test_torch.py -k "test_matmul"
pytest test/test_torch.py -k "test_matmul_cuda_float32" -xPara runs tipo CI está test/run_test.py, que es el runner interno de PyTorch para archivos completos, selección de tests afectados y comportamiento CI como sharding.
python test/run_test.py test_torch
python test/run_test.py -hLas variables de entorno replican el comportamiento CI en local. PYTORCH_TESTING_DEVICE_ONLY_FOR limita los tests a ciertos device types, PYTORCH_TEST_WITH_SLOW=1 incluye tests marcados con @slowTest, y PYTORCH_TEST_WITH_DYNAMO=1 corre los tests con cobertura de TorchDynamo.
Debug de fallos en CI y flujo con Dr. CI
Cuando un job de CI falla, los detalles útiles son el nombre generado con su sufijo de device y dtype, más el shard. En pull requests de PyTorch aparece un comentario automatizado de Dr. CI que agrupa jobs fallidos y patrones recurrentes, y apunta a los logs relevantes.
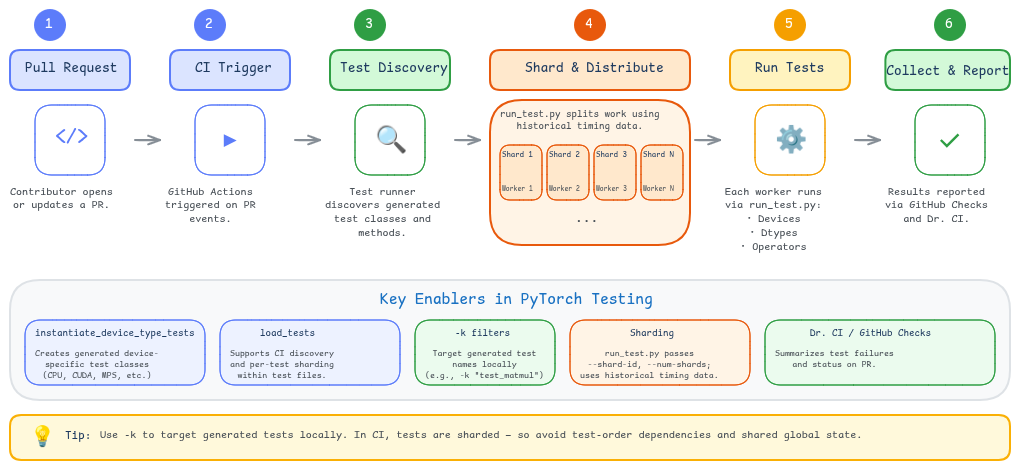
El flujo práctico de debug es: partir del resumen de Dr. CI, abrir los logs del job en hud.pytorch.org, identificar el nombre del test generado y el shard, y reproducir el fallo con pytest -k o run_test.py. Los fallos que solo se dan en CI y no localmente suelen venir de diferencias de entorno, contaminación entre tests, supuestos sobre sharding o diferencias de precisión numérica.
Errores comunes al escribir tests
- Apuntar al nombre del template directamente: después de la expansión el nombre original ya no es descubrible. Usar filtros con
pytest -ko nombres de clase y método generados. - Usar
torch.randnen tests dtype-generic: solo cubre floating-point y complejos. Falla en enteros y booleanos. Preferirmake_tensor, que maneja todas las categorías de dtype pero exige device y dtype explícitos. - Hardcodear devices: usar el argumento
deviceque provee el test generado, no constantes comodevice="cuda". Eso mantiene el test portable.