IA
PyTorch integra Helion en vLLM para acelerar inferencia FP8
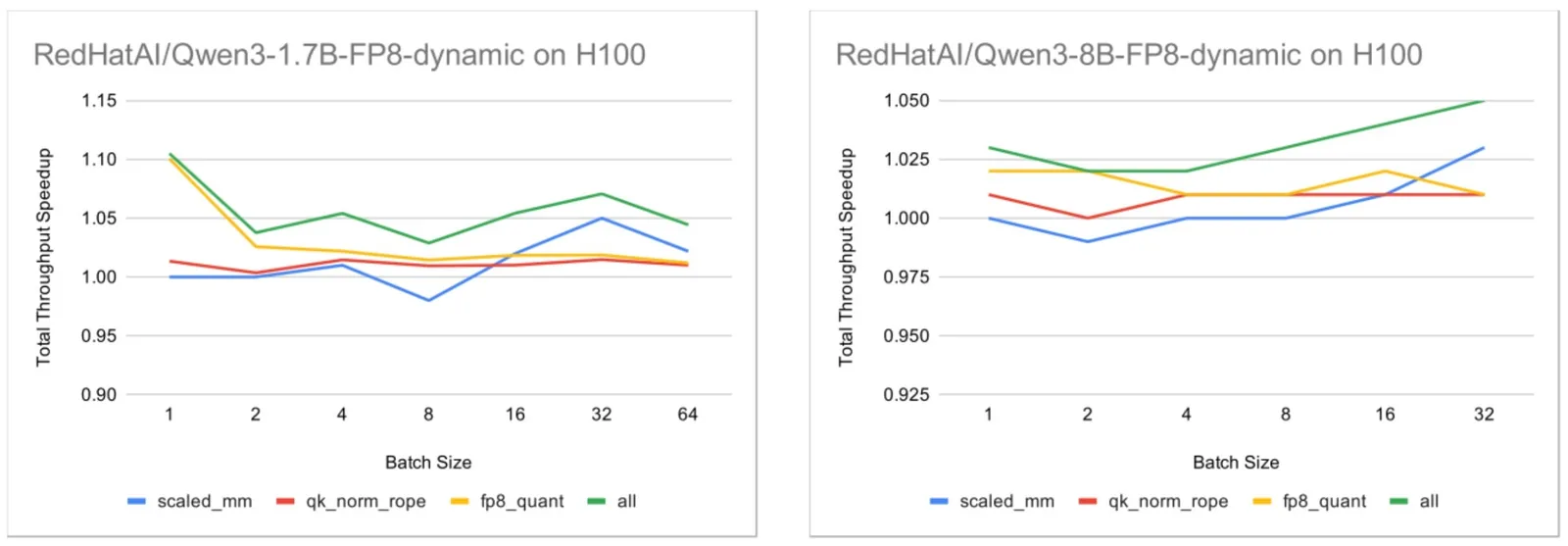
La integración con vLLM aceleró normalización, cuantización fusionada y scaled_mm en H100, mientras que B200 sigue limitado por el backend GEMM de Triton sobre Blackwell.
PyTorch Blog
7 notas publicadas

Hugging Face abre una serie de tres partes sobre profiling con PyTorch, empezando por matmul más bias en bf16 sobre una NVIDIA A100 80GB.
El compilador Inductor agrupa operaciones dependientes en un solo kernel Triton, eliminando lanzamientos extra y tráfico de memoria intermedio.
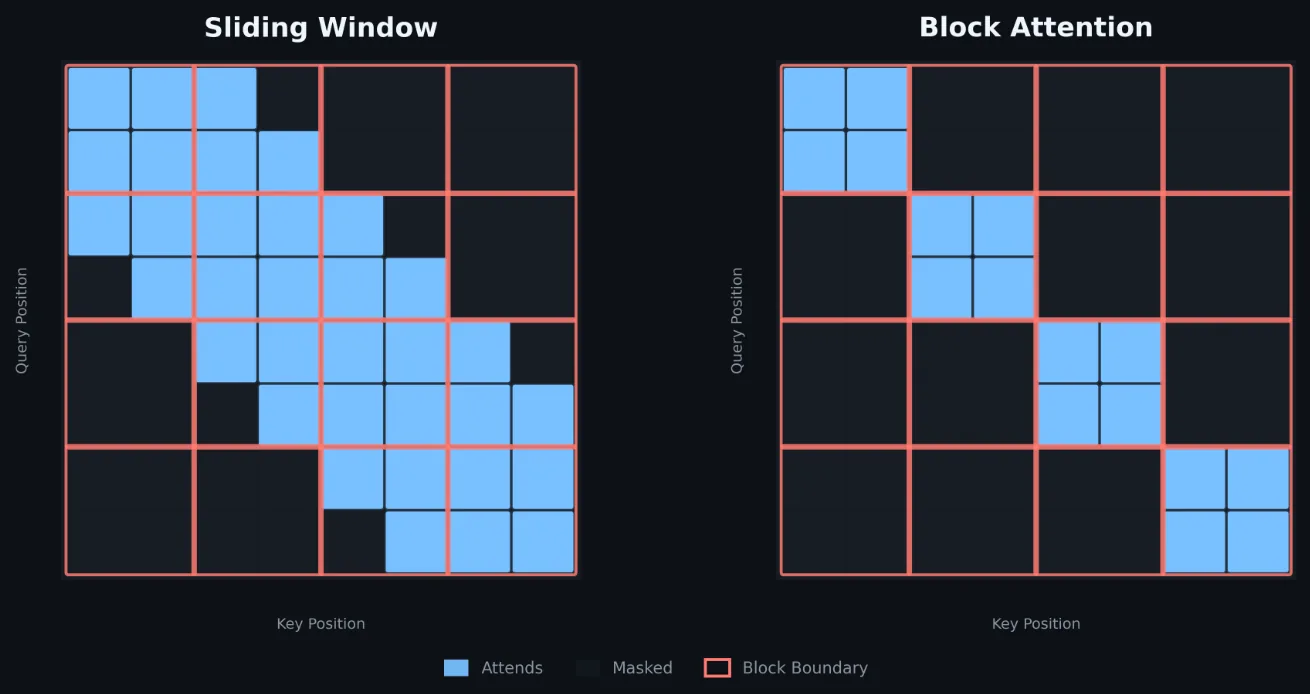
El kernel Triton desarrollado por Meta para GPUs Blackwell aprovecha el patrón block-diagonal de los modelos de ranking para eliminar pasos enteros del algoritmo y acelerar 2,50x el backward pass.

El nuevo wheel CUDA para aarch64 ya viaja en el índice por defecto de PyPI, cerrando dos años de --index-url y reinstalaciones silenciosas que rompían vLLM en Grace Hopper.

El nuevo delegado MLX lleva inferencia GPU optimizada a Mac con chips de Apple, con soporte para Llama, Qwen, Gemma, Whisper y cuantización de 2 a 8 bits, además de NVFP4.
Arm libero una serie de Jupyter Labs que muestran como exportar un modelo PyTorch a un artefacto .pte y correrlo en Raspberry Pi 5 o Cortex-M con NPU Ethos-U.