En una entrevista doble inusual, los lideres tecnicos de Databricks Matei Zaharia y Reynold Xin hablaron en el Data + AI Summit 2026 con Latent Space sobre lo que tomara que cada empresa construya su propia "nube de agentes". La conversacion abrio en el contexto del post de Satya Nadella sobre frontier ecosystems y la valorizacion reciente de Databricks, que ronda los 175 mil millones de dolares.
¿Que es Omnigent y por que importa?

Desde abrir el codigo de la capa que va por encima de los agentes de programacion hasta repensar las bases de datos para la era de los agentes, los cofundadores de Databricks estan empujando a la compañia mas alla del lakehouse hacia un sistema operativo completo para datos e IA. En el episodio, Matei y Reynold desempacaron junto a Shawn "swyx" Wang varias piezas centrales: Omnigent, LTAP, Lakebase, seguridad de agentes, formatos abiertos, Mosaic y por que las bases de datos importan mas que nunca cuando los agentes empiezan a hacer trabajo real.
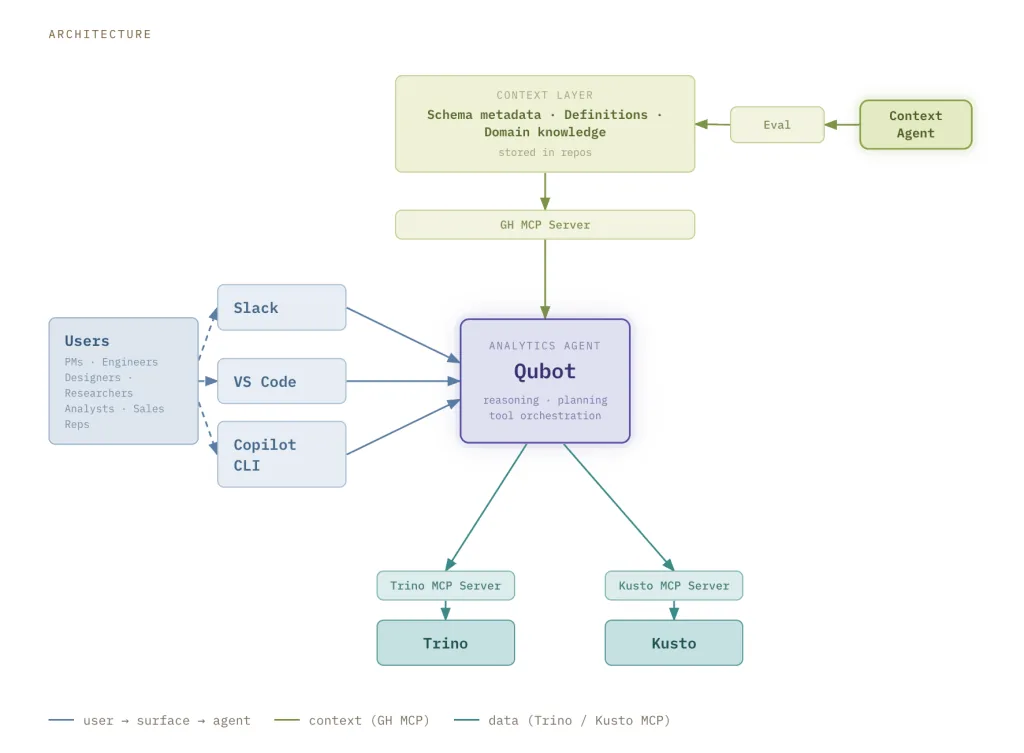
El punto mas profundo del episodio es Omnigent: el meta-harness open source de Databricks para combinar, controlar y compartir agentes entre Claude Code, Codex, Cursor, Pi, agentes a medida y herramientas internas. Matei explica por que los agentes de programacion y los agentes empresariales tropiezan con los mismos problemas: portabilidad, colaboracion, historial de sesiones, seguridad, control de gasto y la necesidad de una API comun sobre cada harness.
Despues, Reynold recorre el sueño de Databricks con bases de datos: por que CDC (change data capture) es tan fragil que en la firma bromean diciendo que significa "continuous data corruption", por que HTAP fue el santo grial de la ingenieria de bases de datos, y por que en Databricks creen que LTAP obtiene la mayoria de los beneficios al unificar la capa de almacenamiento en vez de colapsar todos los motores de consulta. La entrevista tambien cubre la escala de infraestructura de Databricks, la cultura detras del prototipado rapido, la diferencia entre clientes tech y clientes enterprise, el duelo Databricks vs Snowflake, la pregunta de si las bases de datos vectoriales debieron existir alguna vez, la estrategia Mosaic, Genie, AI Runtime, el fine-tuning con RL y la tesis de que el software tradicional se reescribe una vez que los datos estan en el lugar correcto y los agentes se ubican encima.
El giro: de big data a contexto para agentes

Databricks nacio como una compañia para la era del big data. La aparicion de Spark en el AMPLab de Berkeley, que mas tarde se transformo en el producto Lakehouse, convencio a las empresas de que no necesitaban un data lake, un warehouse, una plataforma ML y una capa de gobernanza por separado. Solo necesitaban una fundacion abierta donde todos sus datos pudieran vivir y ser razonados.
Desde entonces mucho cambio, pero los datos solo se volvieron mas importantes. Los datos ya no son algo que uno guarda y analiza ad hoc, son el contexto necesario que los agentes precisan para actuar. El encuadre paso de "donde guardamos todos nuestros datos?" a "como exponemos la rebanada correcta de estado, historia, permisos y logica de negocio a un sistema de IA en el momento exacto en que esta trabajando?".
Si el rendimiento de los modelos de frontera se vuelve un commodity, la ventaja durable pasa a ser el contexto especifico de cada empresa que los rodea: datos propietarios, accesos gobernados, estado operativo, logs transaccionales, flujos de trabajo y feedback loops. Lo que deja a Databricks bien posicionada.
Recien salida del Data + AI Summit 2026, la compañia se mueve igual de rapido para mantenerse al dia y acaba de anunciar Genie One, Omnigent, LTAP y mas, dando una pista de la mision central de su nueva etapa: Databricks intenta convertirse en el sistema operativo para los agentes empresariales.
Los modelos se vuelven suficientemente buenos, pero los agentes solo son utiles si tienen el contexto correcto, los permisos, la memoria, el estado, los controles de costo y el acceso a datos de negocio en vivo. En el fondo, el problema de obtener significativamente mejor rendimiento de los modelos en produccion es un problema de sistemas, justo el tipo de problema para el que la gente que viene de datos esta preparada.
Lo que toca el episodio
- Por que Databricks construyo Omnigent como meta-harness sobre los agentes de IA existentes.
- Por que los agentes de programacion y los agentes empresariales a medida necesitan la misma infraestructura.
- La API comun para sesiones de agentes, archivos, streams, llamadas a tools y cancelacion.
- Por que importan las sesiones persistentes, los cloud sandboxes, el compartir, la busqueda y la colaboracion.
- Por que Databricks abrio el codigo de Omnigent en lugar de mantenerlo propietario.
- El uso interno de agentes en Databricks, los cloud sandboxes y los flujos de codificacion.
- La escala de Databricks: entre 50 y 60 millones de maquinas virtuales por dia y exabytes antes del desayuno.
- Por que la seguridad de agentes necesita politicas contextuales y con estado.
- Como un agente podria leer documentos confidenciales, instalar un paquete npm comprometido y filtrar datos.
- Por que el control de gasto importa cuando un agente puede quemar 500 dolares leyendo logs.
- Oportunidades de startups en torno a analitica, calidad, skills y gasto de agentes de codificacion.
- LTAP, Lakebase y por que Databricks quiere repensar el stack de base de datos.
- OLTP vs OLAP, CDC y por que los pipelines de datos se rompen a las 3 de la mañana.
- Por que HTAP fue historicamente el santo grial de la ingenieria de bases de datos.
- Por que en Databricks creen que LTAP es "HTAP bien hecho".
- Como escribir datos transaccionales en formatos columnares cambia la analitica.
- Por que los agentes necesitan contexto operativo en vivo desde las bases de datos, no solo telemetria.
- Como Databricks prototipa sistemas estrategicos sin proceso interminable.
- Clientes enterprise vs clientes tech, gobernanza, procurement y cultura DIY.
- El riesgo del "sindrome del segundo sistema" al reescribir un motor de base de datos.
- Construir un motor de base de datos desde una decada de trazas y quadrillones de data points.
- Por que las bases de datos vectoriales nunca debieron ser una categoria separada.
- Por que los formatos abiertos y la IA cambiaron la carrera con Snowflake.
- La historia de Mosaic, DBRX, Genie, modelos de parseo de documentos y entrenamiento de modelos especializados.
- Por que la personalizacion de modelos y el fine-tuning con RL podrian volverse mainstream.
- Por que "llevar los datos al lugar correcto, poner un agente encima" podria reescribir el software tradicional.
Los perfiles de los invitados y los enlaces: