Ejecuta agentes de IA locales con modelos más rápidos y clústeres multi-nodo en NVIDIA DGX Spark
El auge de los agentes de IA autónomos y de larga ejecución ha introducido una nueva clase de demanda computacional: tareas que mantienen grandes ventanas de contexto, generan subagentes concurrentes e iteran continuamente sin dependencia de la nube. Las preocupaciones sobre seguridad y privacidad también están acelerando el cambio hacia agentes locales.
Al ejecutar agentes autónomos en hardware propio con NVIDIA NemoClaw para orquestar la ejecución, los desarrolladores pueden mantener el contexto sensible en el dispositivo, conservar el control directo sobre lo que el agente puede acceder y eliminar los costos por token.
NVIDIA DGX Spark está diseñado para construir y ejecutar agentes autónomos localmente. En Computex 2026, NVIDIA facilita significativamente este proceso, introduciendo un camino optimizado desde el desempaquetado hasta la ejecución de agentes de IA en minutos (excluyendo la descarga inicial del modelo, la cual depende de la velocidad de red). También existen mejoras en el rendimiento de modelos con Qwen3.6 y una configuración guiada de clústeres multi-nodo para equipos que necesitan escalar más allá de un solo dispositivo.
Este artículo cubrirá lo que estas actualizaciones significan para los desarrolladores que construyen sistemas de IA agenticos, incluyendo cómo instalar NVIDIA NemoClaw, qué componentes configura y cómo construir y ejecutar su primer agente con OpenClaw en DGX Spark.
Requisitos previos
- Conexión a internet activa para la descarga inicial del modelo.
- Familiaridad con la terminal para pasos de configuración opcionales.
Del desempaquetado a la ejecución de un agente local
Históricamente, lograr que un agente de IA local funcione implicaba encontrar el modelo adecuado, configurar un backend de inferencia, instalar un tiempo de ejecución y conectarlos entre sí. Ese proceso podía tomar la mayor parte de un día incluso para desarrolladores experimentados. La nueva ruta de instalación simplificada de NemoClaw cambia eso.
Para los nuevos sistemas, la experiencia comienza con el desempaquetado y la configuración inicial de DGX Spark. La versión más reciente del software del sistema DGX Spark, la versión de junio de 2026, ofrece la experiencia de usuario (OOBE) más optimizada hasta la fecha, permitiendo que los usuarios accedan a agentes locales más rápido. Con este lanzamiento, las actualizaciones por aire (OTA) ya no se instalan de forma predeterminada durante la configuración inicial, lo que reduce el tiempo de preparación y lleva a los usuarios al escritorio Ubuntu antes.
NemoClaw es un plano técnico de código abierto que empaqueta tres elementos en una sola instalación: modelos abiertos, un arnés de agentes (como Hermes Agent o OpenClaw) y el NVIDIA OpenShell runtime. OpenShell es un entorno de ejecución seguro y aislado diseñado para ejecutar agentes autónomos con mayor protección. Añade controles de acceso, protecciones de privacidad y barandillas operativas al bucle del agente. Combinado con la inferencia en el dispositivo, esto proporciona a los desarrolladores una postura predeterminada de seguridad y privacidad más sólida para cargas de trabajo agenticas.
Paso 1: Instalar NemoClaw
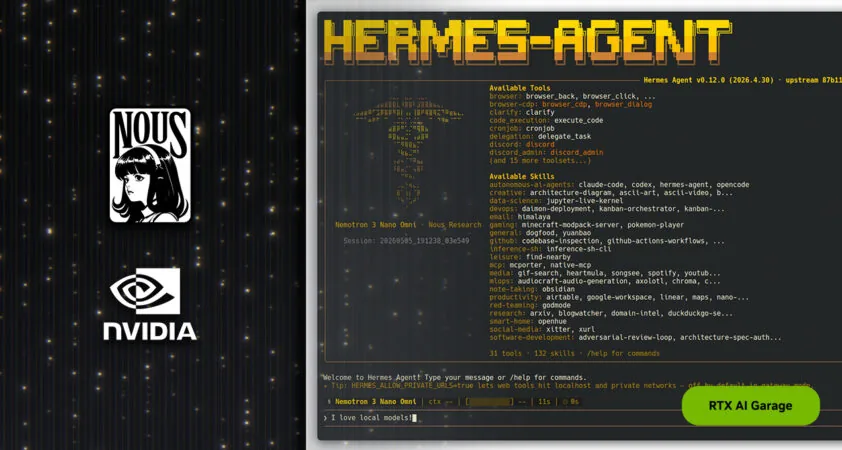
La figura 1, a continuación, muestra la ruta completa desde la finalización del OOBE hasta un agente NemoClaw en ejecución en DGX Spark.

Después de completar el OOBE, DGX Spark se reinicia y abre build.nvidia.com/spark con el playbook de NemoClaw desplegado prominentemente para un recorrido guiado. Ejecute este comando único para instalar Node.js (si es necesario), instalar OpenShell, clonar la última versión estable de NemoClaw, compilar la CLI y ejecutar el asistente integrado para crear un entorno aislado (sandbox).
curl -fsSL https://www.nvidia.com/nemoclaw.sh | bashEl asistente de instalación le guía a través de la configuración:
- Aceptar licencias de NemoClaw y OpenClaw — Confirme ingresando yes.
- Ejecutar instalación rápida — Confirme ingresando Y.
- Ollama local se configura junto con Qwen3.6-35B descargado automáticamente.
Aprenda más sobre cómo instalar NemoClaw en su sistema DGX Spark/GB10: Comience con NemoClaw en DGX Spark →
Paso 2: Acceda a su agente
Una vez que se completa la instalación, está listo para personalizar sus agentes. Primero, interactúe usando la interfaz WebUI:
nemoclaw <nombre del sandbox> gateway-token --quietLuego abra la URL con token en un navegador: http://127.0.0.1:18789/#token=<WEBUI_TOKEN>. Utilice 127.0.0.1 exactamente; la verificación de origen de la puerta de enlace lo requiere (no localhost). Envíe un mensaje de prueba rápido — "hello" o "what can you do?" — para confirmar que toda la pila está activa. El modelo Ollama local ya está seleccionado; NemoClaw configura esto automáticamente durante la incorporación.
Paso 3: Construya su primer agente
Con su sandbox en ejecución, el NemoClaw Applications playbook ofrece cuatro agentes listos para ejecutar para comenzar, cada uno con configuración de políticas, un prompt de inicio y guía de personalización:
- Resumen diario de noticias personales — una sesión informativa matutina programada que rastrea sus temas y publica un resumen estructurado en Telegram.
- Agente de desarrollo de software — lee un directorio de proyecto local, construye un plan, escribe y revisa su propio código, todo sin red externa más allá de la inferencia local.
- Revisor de presentaciones y documentos — analiza un archivo antes de enviarlo, devolviendo una lista de inconsistencias, afirmaciones sin fuente y problemas de accesibilidad.
- Negociador de calendario — un jefe de gabinete de programación que convierte hilos de "¿cuándo podemos reunirnos?" en un evento de calendario confirmado.
Paso 4: Personalizaciones adicionales
Con el sandbox en ejecución, las palancas principales para dar forma al comportamiento del agente son:
- Prompt del sistema — Edite las instrucciones del agente desde el panel para moldear cómo responde y qué debe preguntar antes de actuar. Prompts más específicos producen agentes más confiables.
- Permisos de herramientas — Las políticas de red de OpenShell controlan a qué destinos externos puede llamar el agente. Permisos más restringidos reducen comportamientos inesperados.
- Integraciones — Si habilitó un canal de mensajería durante la incorporación, el agente ya es accesible allí. Envíele un mensaje desde su teléfono y responderá usando el mismo modelo local.
Los desarrolladores pueden personalizar aún más intercambiando diferentes modelos, ajustando los permisos de OpenShell y conectando el agente a flujos de trabajo locales. Para iniciar un nuevo sandbox con un modelo diferente, ejecute nemoclaw onboard --fresh --gpu y seleccione un modelo distinto durante el asistente. Tenga en cuenta que --fresh destruye y recrea el sandbox existente; use --name <nuevo-nombre> para crear un sandbox adicional sin afectar los existentes. Las instrucciones completas de instalación de NemoClaw y el catálogo de modelos están disponibles en NVIDIA NGC.
Consejo: Comience con algo limitado. Dé al agente una tarea única y bien definida en su primera ejecución, como "resumir un archivo" o "responder una pregunta" desde un documento local. Verifique que la respuesta y las llamadas a herramientas sean correctas antes de ampliar sus permisos.
Agentes en DGX Spark usando Qwen3.6-35B
Los desarrolladores pueden experimentar una inferencia hasta 2.6 veces más rápida con modelos agenticos de primer nivel como Qwen 3.6 35B en vLLM con el checkpoint cuantizado NVFP4 de NVIDIA usando optimizaciones MTP. Existen mejoras adicionales en el soporte de vLLM CUDA Graph para MTP con FlashInfer, autotuning BF16 en kernels FlashInfer MoE, TinyGEMM y rutas cuBLAS BF16.

Vía NVIDIA Developer.