IA
PyTorch integra Helion en vLLM para acelerar inferencia FP8
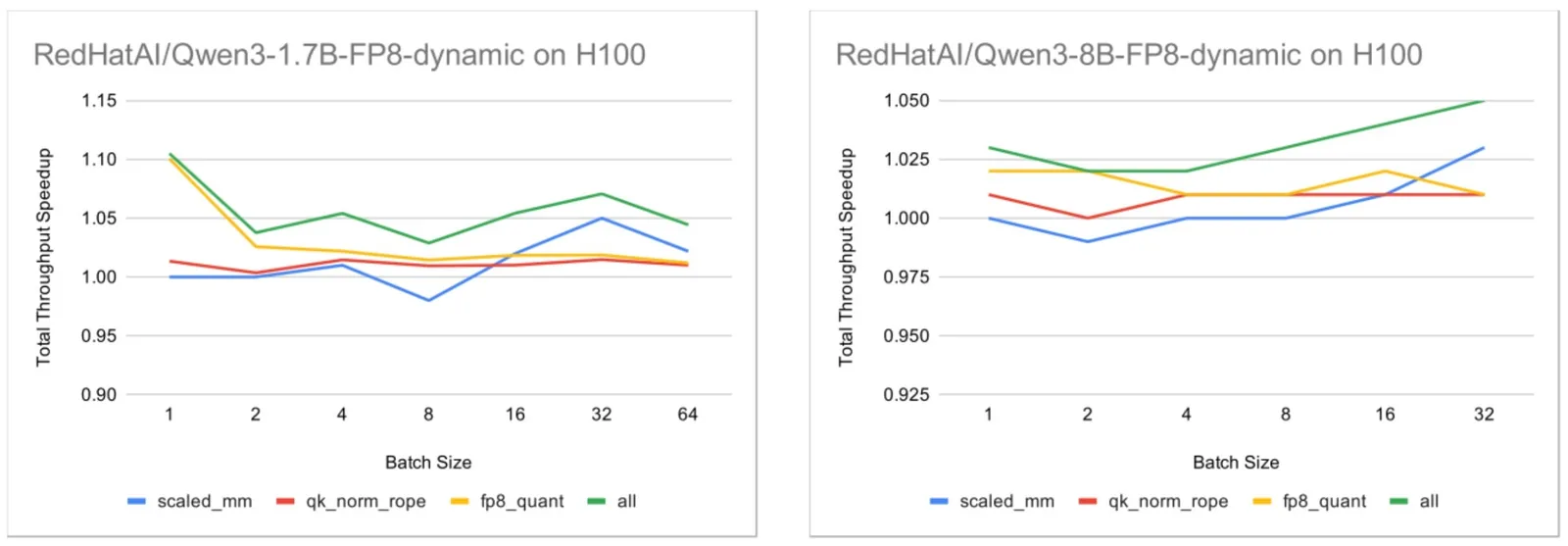
La integración con vLLM aceleró normalización, cuantización fusionada y scaled_mm en H100, mientras que B200 sigue limitado por el backend GEMM de Triton sobre Blackwell.
PyTorch Blog
1 nota publicada