IA
PyTorch integra Helion en vLLM para acelerar inferencia FP8
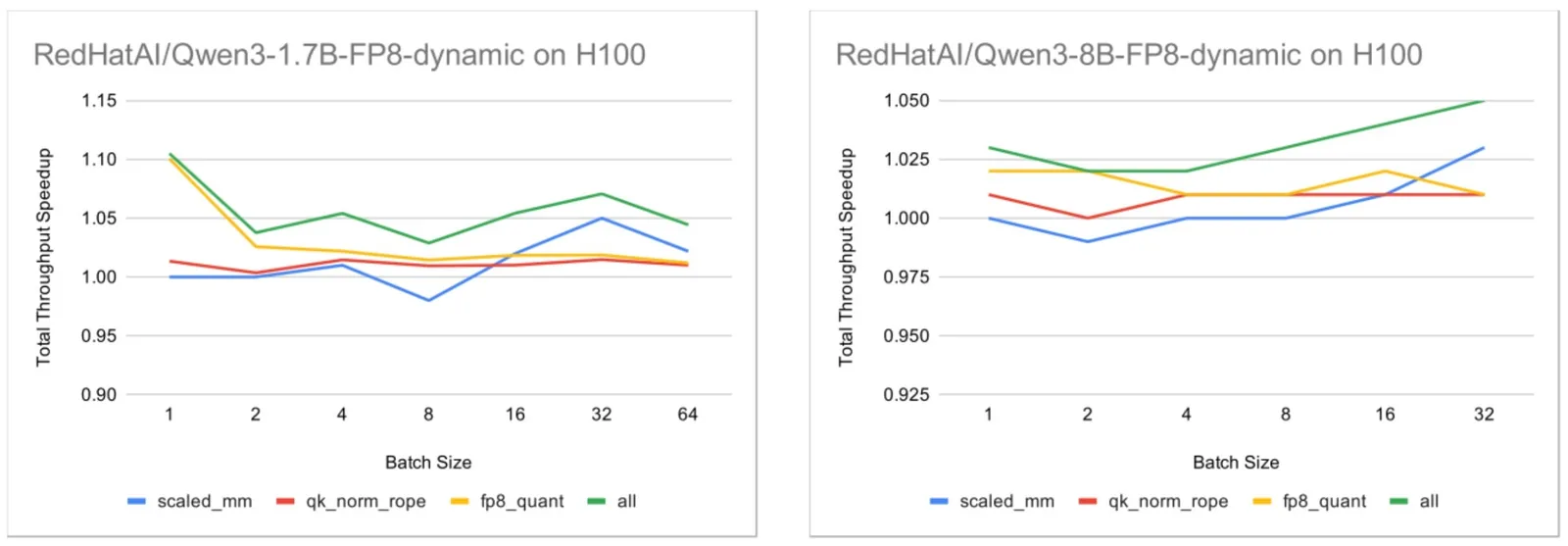
La integración con vLLM aceleró normalización, cuantización fusionada y scaled_mm en H100, mientras que B200 sigue limitado por el backend GEMM de Triton sobre Blackwell.
PyTorch Blog
3 notas publicadas

Hugging Face liberó un PR en TRL que codifica solo los pesos que cambiaron como safetensors disperso y los sube a un Hub Bucket. El trainer y el rollout dejan de necesitar el mismo data center.

El nuevo wheel CUDA para aarch64 ya viaja en el índice por defecto de PyPI, cerrando dos años de --index-url y reinstalaciones silenciosas que rompían vLLM en Grace Hopper.
Otros temas que aparecen junto a #vllm en nuestra cobertura editorial.