TL;DR: los kernels Helion se integraron a vLLM para inferencia FP8 con la familia de modelos Qwen3, evaluados sobre GPUs NVIDIA H100 y B200. La conclusión del equipo de PyTorch es que Helion entrega un flujo PyTorch-nativo productivo para desarrollar kernels GPU fusionados, con mejoras de rendimiento en muchos kernels de cuantización, normalización y fusión. Los benchmarks de extremo a extremo mostraron ganancias de throughput en varios escenarios de serving, mientras siguen las optimizaciones para GEMM en GPUs Blackwell.
¿Qué son vLLM y Helion?

vLLM es un framework de inferencia y serving de alto rendimiento para large language models (LLMs). Se usa ampliamente para servir LLMs en producción por su throughput, manejo eficiente del KV-cache, arquitectura de continuous batching y soporte para características avanzadas como speculative decoding, cuantización y serving distribuido. Internamente, vLLM depende fuertemente de kernels GPU custom, la fusión de TorchInductor y backends GEMM optimizados como CUTLASS y DeepGEMM para alcanzar alta eficiencia en distintas plataformas de hardware.
Helion es un DSL de kernels PyTorch-native, agnóstico al hardware, diseñado para escribir kernels de alto rendimiento usando un modelo de programación por tiles. A diferencia de la programación CUDA pura de bajo nivel, Helion entrega una experiencia más cercana a la sintaxis PyTorch, manteniendo control sobre el layout de memoria, la estrategia de tiling y el scheduling del kernel. La idea es "PyTorch con tiles". Otro punto fuerte de Helion es su infraestructura de autotuning ahead-of-time (AOT), que explora un espacio grande de configuraciones y selecciona automáticamente la implementación óptima para cada workload y hardware.
Inferencia de vLLM con kernels Helion
El equipo de PyTorch partió enfocando inferencia sin tensor-parallel sobre la familia de modelos Qwen3, con cuantización FP8 de activaciones habilitada. El objetivo era evaluar si los kernels Helion podían mejorar el rendimiento de inferencia frente a las implementaciones actuales de vLLM. Para este experimento reemplazaron casi todos los kernels del forward pass involucrados en la inferencia cuantizada por implementaciones Helion, y los midieron a nivel de kernel y a nivel de serving completo.
Patrón de fusión del forward pass
Para los modelos Qwen3, el forward pass sin fusionar en vLLM ejecuta esta secuencia: scaled_mm (qkv_proj), scaled_mm (out_proj), post_attention_norm, scaled_mm (gate_up), silu_and_mul y scaled_mm (down_proj).
Tras aplicar torch.compile y los pases de fusión de TorchInductor con cuantización dinámica por token, el patrón colapsa en pares fusionados: rms_norm + fp8_quant, seguidos por las multiplicaciones de matrices y la fusión silu_and_mul + fp8_quant. Tanto scaled_mm como la atención están registrados como PyTorch Custom Operators, por lo que actúan como bordes opacos para TorchInductor y bloquean fusiones adicionales del compilador.
Cuando se usa cuantización por grupo con DeepGEMM (que internamente usa UE8M0), los pases fuse_act_quant y fuse_norm_quant no están soportados en la implementación actual de vLLM, lo que limita las fusiones disponibles. Si DeepGEMM no está disponible y se cae a kernels CUTLASS, el patrón se parece al caso de cuantización por token.
Kernels Helion implementados
Para este trabajo se implementaron los siguientes kernels Helion: dynamic_per_token_scaled_fp8_quant, rms_norm_dynamic_per_token_quant, silu_and_mul_dynamic_per_token_quant, fused_qk_norm_rope, per_token_group_fp8_quant, rms_norm_per_block_quant, silu_and_mul_per_block_quant y scaled_mm_blockwise. Los kernels scaled_mm y scaled_mm_blockwise siguen las implementaciones Triton existentes en vLLM (triton_scaled_mm, w8a8_triton_block_scaled_mm). El kernel silu_and_mul_dynamic_per_token_quant es nuevo y combina silu_and_mul y dynamic_per_token_quant en un solo launch. El resto son reimplementaciones Helion de los kernels CUDA existentes en torch.ops._C que usa vLLM.
Integración y autotuning
La integración usó el framework de integración Helion-vLLM, que provee infraestructura de autotuning, gestión de config, registro de kernels y runtime dispatching. El equipo actualizó manualmente los pases de fusión de vLLM para reemplazar cada kernel por su contraparte Helion fusionada.
Para autotunear, usaron el algoritmo por defecto de Helion (LFBOTreeSearch) con initial_population=FROM_RANDOM, copies=5, max_generations=20, similarity_penalty=1.0. Los kernels fueron tuneados usando las dimensiones estáticas exactas de cada modelo Qwen3 (hidden size, intermediate size). Para la dimensión dinámica num_tokens se autotuneó sobre potencias de dos desde 1 hasta 8192. En scaled_mm, las dimensiones M cubren ese mismo rango y los pares (K, N) corresponden a los proyectores de cada modelo Qwen3. Todos los kernels fueron autotuneados de forma independiente para cada plataforma de hardware.
¿Qué tan rápidos son los kernels Helion?
El benchmark a nivel de kernel evalúa la aceleración local de cada kernel Helion contra su baseline. Para scaled_mm y scaled_mm_blockwise se usó CUTLASS como baseline. Para el resto, el baseline fue la implementación vLLM compilada con torch.compile y los kernels existentes en torch.ops._C. La razón: la cuantización por token en vLLM usa torch.compile por defecto, mientras que la cuantización por grupo cae a las implementaciones CUDA en torch.ops._C por un problema de rendimiento conocido.
El baseline torch.compile se configuró replicando exactamente el setup de vLLM:
torch.compile(
native_torch_impl,
fullgraph=True,
dynamic=False,
backend="inductor",
options={
"enable_auto_functionalized_v2": False,
"size_asserts": False,
"alignment_asserts": False,
"scalar_asserts": False,
"combo_kernels": True,
"benchmark_combo_kernel": True,
},
)Activar combo_kernels: True es importante porque permite que TorchInductor fusione varios kernels independientes en un solo launch. Para el benchmark a nivel de kernel se habilitó el modo CudaGraph vía triton.testing.do_bench_cudagraph con warmup y repetición para eliminar ruido por dispatch overhead, cold cache y variaciones de timing.
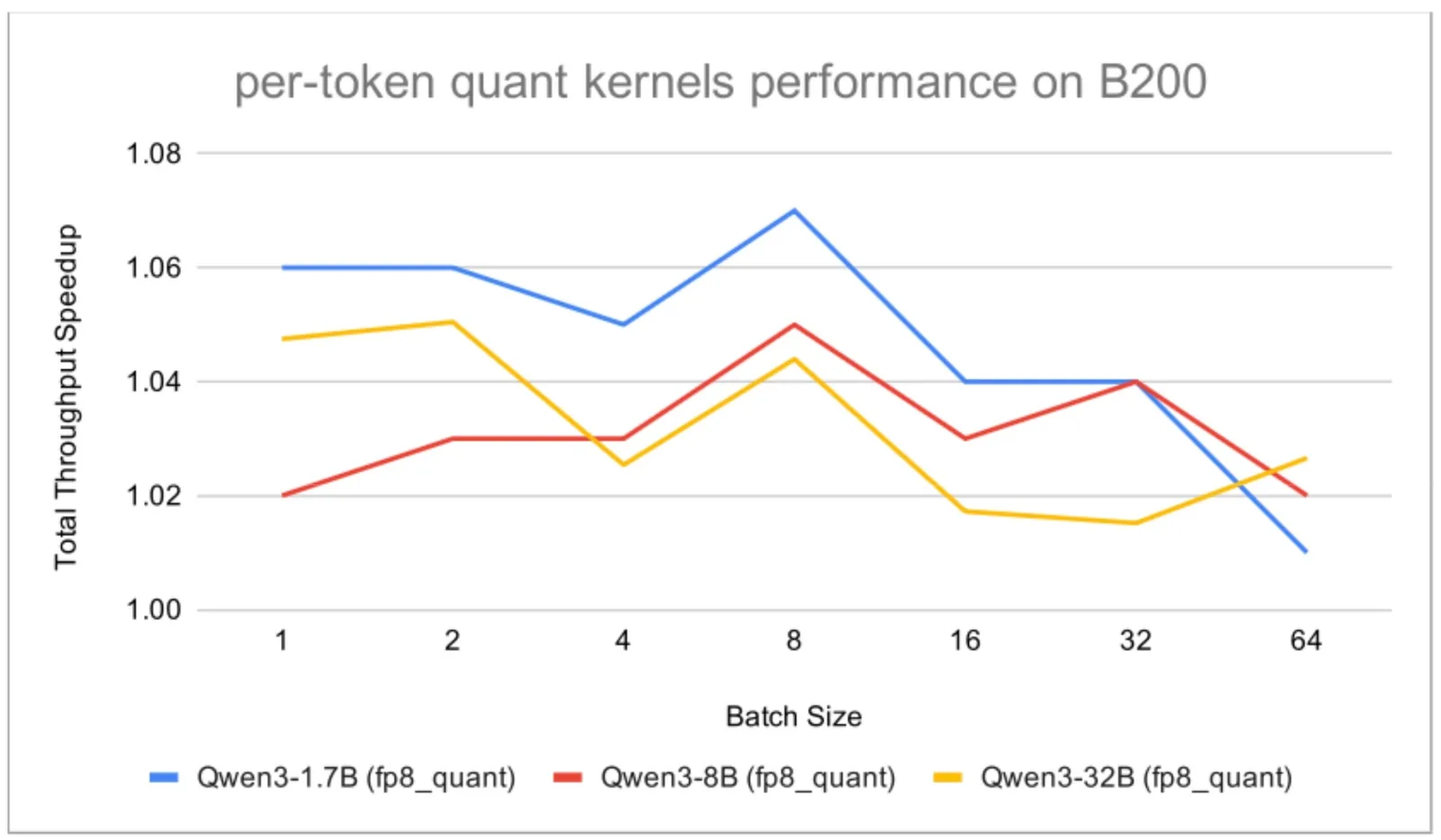
En los kernels no-GEMM, Helion mostró consistentemente buen rendimiento y superó tanto a los kernels generados por TorchInductor como a las implementaciones CUDA existentes en vLLM. En workloads GEMM (scaled_mm y scaled_mm_blockwise) los resultados fueron mixtos: en H100, scaled_mm superó a CUTLASS; en B200, ambos kernels GEMM quedaron por debajo de CUTLASS.
¿Por qué B200 se queda atrás?
Según el equipo de PyTorch, el factor limitante en B200 es el rendimiento de los kernels GEMM generados por Triton sobre las GPUs Blackwell, no el modelo de programación Helion en sí. Helion depende actualmente de la generación de código de Triton para esos kernels, y la brecha refleja el estado actual del backend GEMM de Triton sobre hardware Blackwell. El trabajo en curso sobre el backend CuteDSL de Helion debería mejorar el rendimiento GEMM en Blackwell más adelante.
Benchmarks de extremo a extremo
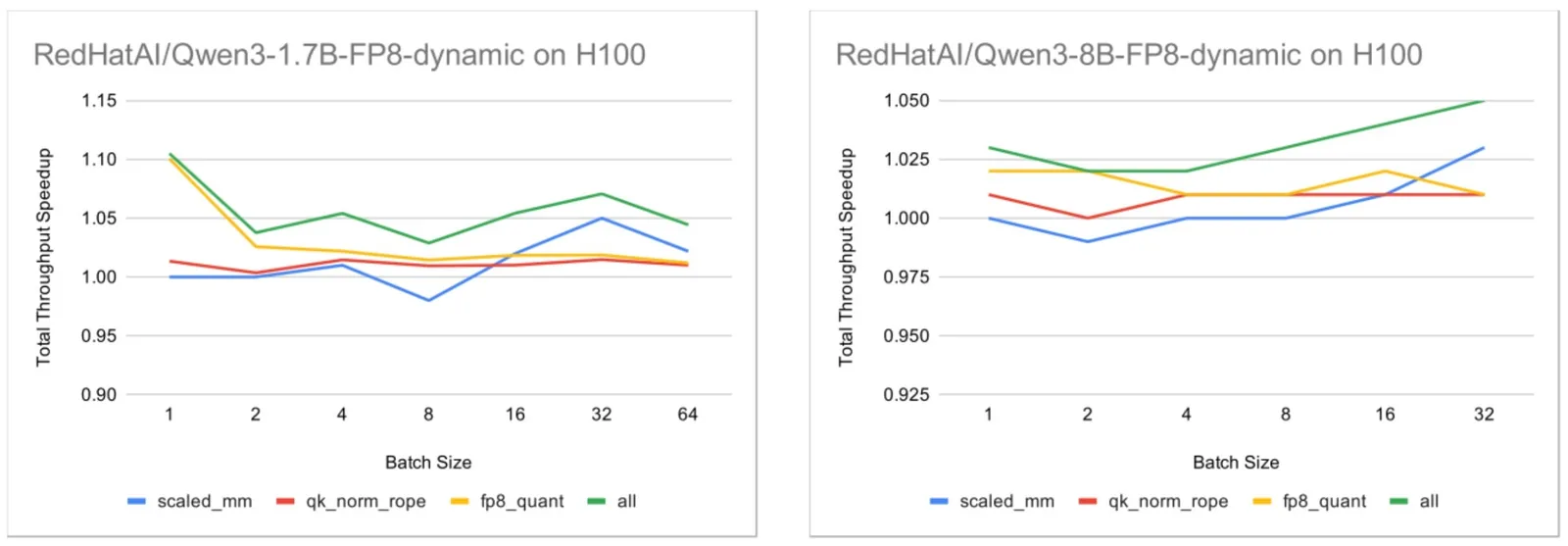
El benchmark a nivel de modelo busca medir el impacto visible para el usuario. El equipo eligió tres variantes de modelos Qwen3 para el experimento. CudaGraph quedó habilitado para todo el tráfico de benchmarking, con num_tokens variando entre 1 y 8192 a intervalos de potencias de dos para los tres modelos. Para construir el patrón de tráfico se usó el benchmark de serving incluido en vLLM con datos aleatorios. Para minimizar el ruido por prefix caching, deshabilitaron el shuffling de prompts y reiniciaron el servidor de vLLM antes de cada corrida.
Un ejemplo del comando usado:
vllm serve --model $MODEL --max-num-seqs $BATCH_SIZE --tensor-parallel-size 1 \
--compilation-config '{"max_cudagraph_capture_size": 8192, "custom_ops": ["+quant_fp8"], "pass_config": {"fuse_norm_quant": true, "fuse_act_quant": true, "enable_qk_norm_rope_fusion": true}}'
vllm bench serve \
--backend vllm \
--model $MODEL \
--endpoint /v1/completions \
--dataset-name random \
--num-prompts $NUM_PROMPTS \
--max-concurrency $BATCH_SIZE \
--input-len 512 \
--output-len 600 \
--num-warmups $NUM_WARMUPS \
--disable-shuffleEl valor max_cudagraph_capture_size se fijó en 8192 para igualar el max_num_batched_tokens por defecto, asegurando que todos los caminos de ejecución quedaran capturados con CUDA Graphs. Las cargas de trabajo se evaluaron en NVIDIA H100 y NVIDIA B200. Para entender de dónde vienen las mejoras, los kernels Helion se agruparon en tres categorías y se midieron tanto de forma independiente como en combinación.
¿Qué cambia para un equipo que ya usa vLLM?
La promesa práctica de Helion es bajar el costo de escribir y mantener kernels custom para serving FP8 sin renunciar al patrón PyTorch. Para equipos que hoy mezclan CUTLASS, DeepGEMM y kernels CUDA propios, la posibilidad de prototipar fusiones en una sintaxis cercana a PyTorch y dejar que el autotuner barra el espacio de configuración acorta el ciclo de iteración. Los resultados publicados son específicos a Qwen3 y FP8, pero la metodología debería transferirse a otros modelos con patrones de forward pass similares.



