BEVPoolV3 introduce cuatro cambios algorítmicos al pooling bird's-eye-view en GPUs NVIDIA: reduce las cargas duplicadas de profundidad, usa un mapa scatter INT32 de cinco arreglos, precomputa índices para eliminar divisiones enteras en tiempo de ejecución y asigna escrituras de salida por intervalo. El resultado, según NVIDIA Developer, es una reducción significativa de latencia en distintos regímenes de memoria GPU.
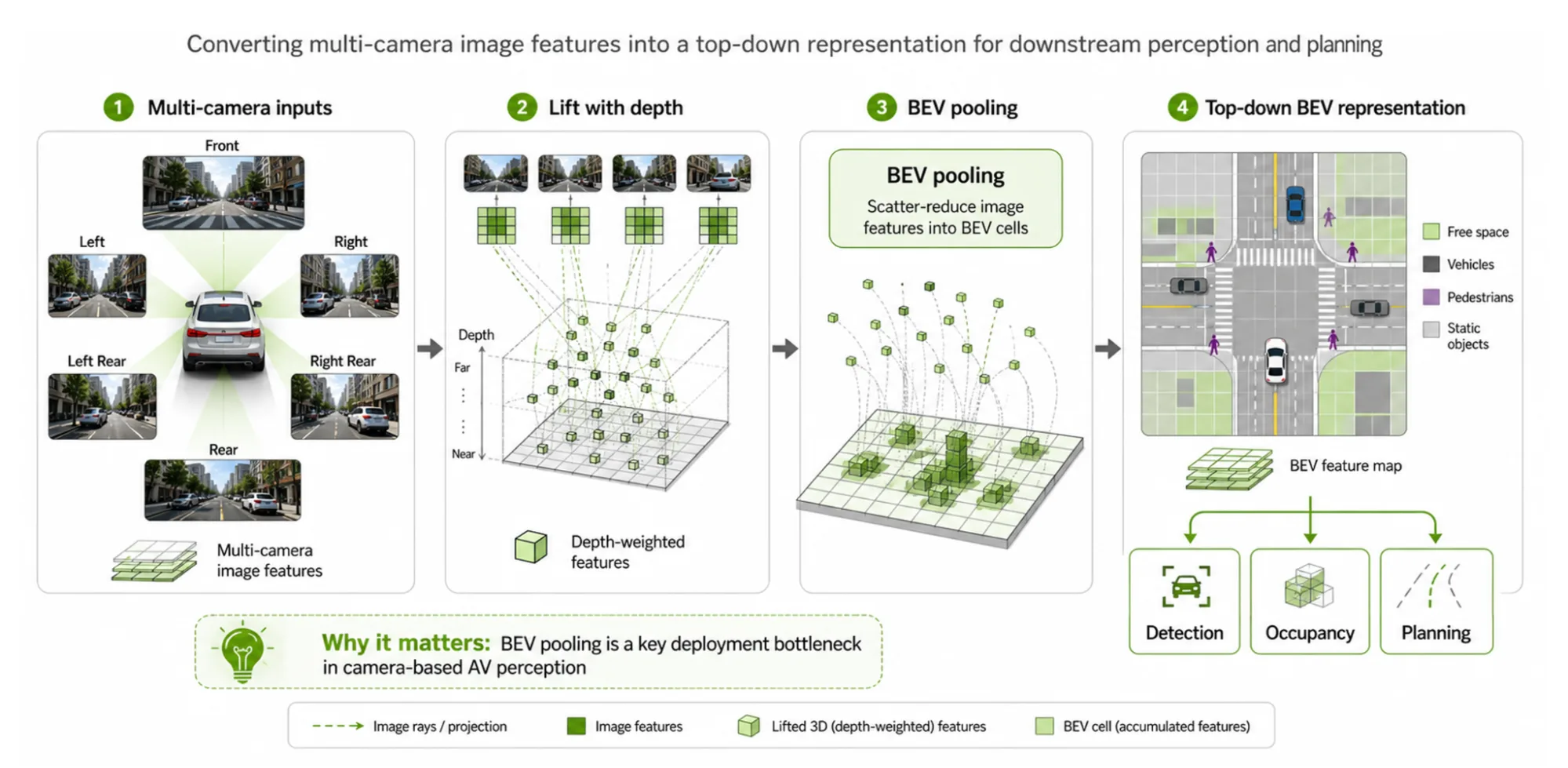
El operador BEV pooling proyecta las features de imágenes multicámara sobre una grilla compartida en vista cenital. Esa representación unificada alimenta los módulos de detección, predicción de ocupación, planificación de trayectoria y mapeo de vehículos autónomos y robots. En la práctica, BEV pooling se convierte en cuello de botella porque combina accesos irregulares a memoria, lecturas repetidas de índices, comportamiento scatter-reduce y efectos de caché propios de cada GPU.
¿Qué cambia BEVPoolV3 frente a la versión anterior?
NVIDIA evaluó el kernel sobre dos arquitecturas con perfiles de memoria opuestos. La RTX A6000 es Ampere SM86, con 6 MB de caché L2 y sin instrucciones FP8 nativas. La RTX PRO 6000 Blackwell Max-Q Workstation Edition es Blackwell SM120, con 128 MB de L2 y FP8 nativo. La configuración de referencia, derivada de muestras reales del dataset nuScenes, define 209 mil puntos de scatter, 80 canales de features y un working set de 49 MB para BEV pooling. Ese tamaño excede la L2 de la A6000 pero entra completo en la L2 de la RTX PRO 6000, lo que hace que la primera quede limitada por DRAM y la segunda quede mayormente residente en caché L2 tras el llenado inicial.
En esa configuración, el camino histórico del plugin NVIDIA TensorRT estilo V2 tarda 274,0 µs en la RTX PRO 6000 Blackwell Max-Q. BEVPoolV3 baja ese número a 17,3 µs en FP16 y a 16,4 µs en FP8. En la RTX A6000, el camino adaptado a DRAM con BEVPoolV3 FP16 alcanza 90,0 µs.
¿Cuánto speedup se logra y en qué precisión?
Los benchmarks publicados por NVIDIA muestran que V3 supera al plugin V2 FP16 por 19,31x en la RTX A6000 y por 15,84x en la RTX PRO 6000 Blackwell Max-Q. Sobre el camino L2-residente, FP8 ofrece una ganancia adicional: V3 FP8 alcanza 16,71x sobre V2 FP16 en Blackwell. En el camino DRAM-bound, la versión FP16 puede superar a V2 por hasta 22x; en el camino L2-resident, FP8 escala hasta 42x sobre V2.
NVIDIA aclara que las plataformas edge-class requieren evaluación específica para decidir si conviene adoptar FP8, porque la ganancia depende de la arquitectura del SM y de la disponibilidad de la ISA FP8 nativa.
¿Cómo se decide la estrategia de optimización?
El flujo de trabajo que propone NVIDIA tiene cuatro pasos. Primero, clasificar el working set según si entra o no en la L2 de la GPU objetivo. Segundo, eliminar tráfico scatter redundante. Tercero, mapear la implementación del kernel a la arquitectura GPU concreta. Cuarto, validar el cuello de botella activo con NVIDIA Nsight Compute.
La elección entre optimizaciones cambia según el régimen. Si el workload es DRAM-bound, importa más reducir el tráfico de memoria global y vectorizar las cargas. Si el workload es L2-residente, importan más las decisiones de mapping warp/SM y la adopción de FP8 para reducir el ancho de banda interno.
Prerequisitos técnicos
El post original detalla conocimientos previos útiles para reproducir el ejercicio: conceptos de kernel CUDA como warp scheduling, atomics, cargas globales vectorizadas y comportamiento de DRAM/L2/L1; integración de plugins TensorRT bajo la interfaz IPluginV3; profiling con Nsight Compute para validar memoria, ocupación y cuellos de botella en emisión de instrucciones; y la implementación previa del kernel BEV-pooling en CUDA-BEVFusion, que sirve como referencia depth-outer.
Los recursos de referencia incluyen la Guía de Programación CUDA C++, la documentación de plugins TensorRT, los samples de TensorRT y la Profiling Guide de Nsight Compute. El paper original de BEVPoolV2 sigue siendo el punto de partida formal de la línea de optimización.
Implicancia para hardware accesible
La línea entre regímenes DRAM y L2 explica por qué un mismo modelo BEV puede comportarse muy distinto en una GPU de estación de trabajo de 6 MB de L2 versus una de 128 MB. Para equipos integrando percepción en plataformas edge tipo NVIDIA Jetson Orin o AGX Thor, esto implica que el costo real del pipeline depende menos del modelo y más de la fracción del working set que entra en caché. La recomendación de NVIDIA es perfilar caso a caso, no asumir que el speedup reportado en RTX se trasladará linealmente al hardware embarcado.