AgentPerf de Artificial Analysis, el primer benchmark de la industria para IA agéntica, entrega a desarrolladores, empresas y proveedores de infraestructura una forma clara de comparar sistemas dedicados a este tipo de cargas. En su primera ronda de resultados publicados, la plataforma NVIDIA Blackwell Ultra NVL72 encabezó el ranking, corriendo 20 veces más agentes por megawatt que NVIDIA Hopper.
La IA agéntica es una carga fundamentalmente distinta a la IA conversacional. Una conversación de chat es un sprint: una llamada al modelo de lenguaje, una respuesta. Un agente, en cambio, funciona más como una posta: divide un objetivo en muchos pasos y avanza hasta terminar la tarea.
Eso resulta en decenas o cientos de llamadas LLM encadenadas, cada una pasando un contexto creciente a la siguiente, con tool calls como compilar y ejecutar código, búsqueda en bases de datos y navegación web en cada handoff. La complejidad no es aditiva, es multiplicativa.
La distinción importa para la medición de rendimiento. Los benchmarks de inferencia existentes miden una sola llamada LLM: cuán rápido responde a una solicitud y cuántas solicitudes simultáneas tolera el sistema. No fueron diseñados para cargas agénticas, donde llamadas LLM encadenadas, demoras de tool calls y contexto creciente estresan los aceleradores de forma muy distinta a una llamada única.
¿Qué hace exactamente AgentPerf?
AgentPerf se construye sobre trayectorias reales de agentes de código: un agente recibe una tarea, lee archivos, escribe y edita código, ejecuta comandos e itera según los resultados, todo extraído de repositorios públicos en más de 12 lenguajes de programación. Las secuencias largas, los patrones de tool calls y los retrasos son representativos de flujos reales.
El benchmark mide cuántas tareas agénticas simultáneas soporta una plataforma cumpliendo dos umbrales de rendimiento: 20 y 60 tokens por segundo por agente para latencia de respuesta. Los tool calls no se ejecutan: se simulan con tiempo representativo de CPU para que las diferencias de resultado reflejen únicamente la performance del compute acelerado.
Los resultados se traducen directo en decisiones de infraestructura: cuántas tareas agénticas concurrentes corren por acelerador y por megawatt de potencia. Para empresas que despliegan agentes a escala, esos números determinan cuánto trabajo productivo entrega realmente una inversión en infraestructura.
GB300 NVL72: 20× más agentes por megawatt
En esta primera ronda, AgentPerf mide rendimiento agéntico con DeepSeek V4 Pro, un gran modelo Mixture-of-Experts (MoE) que representa la clase de modelos de frontera detrás de los agentes más capaces de hoy. Sobre esa carga, NVIDIA GB300 NVL72 entrega el rendimiento más alto del benchmark, corriendo hasta 20 veces más agentes por megawatt que un sistema NVIDIA HGX H200.
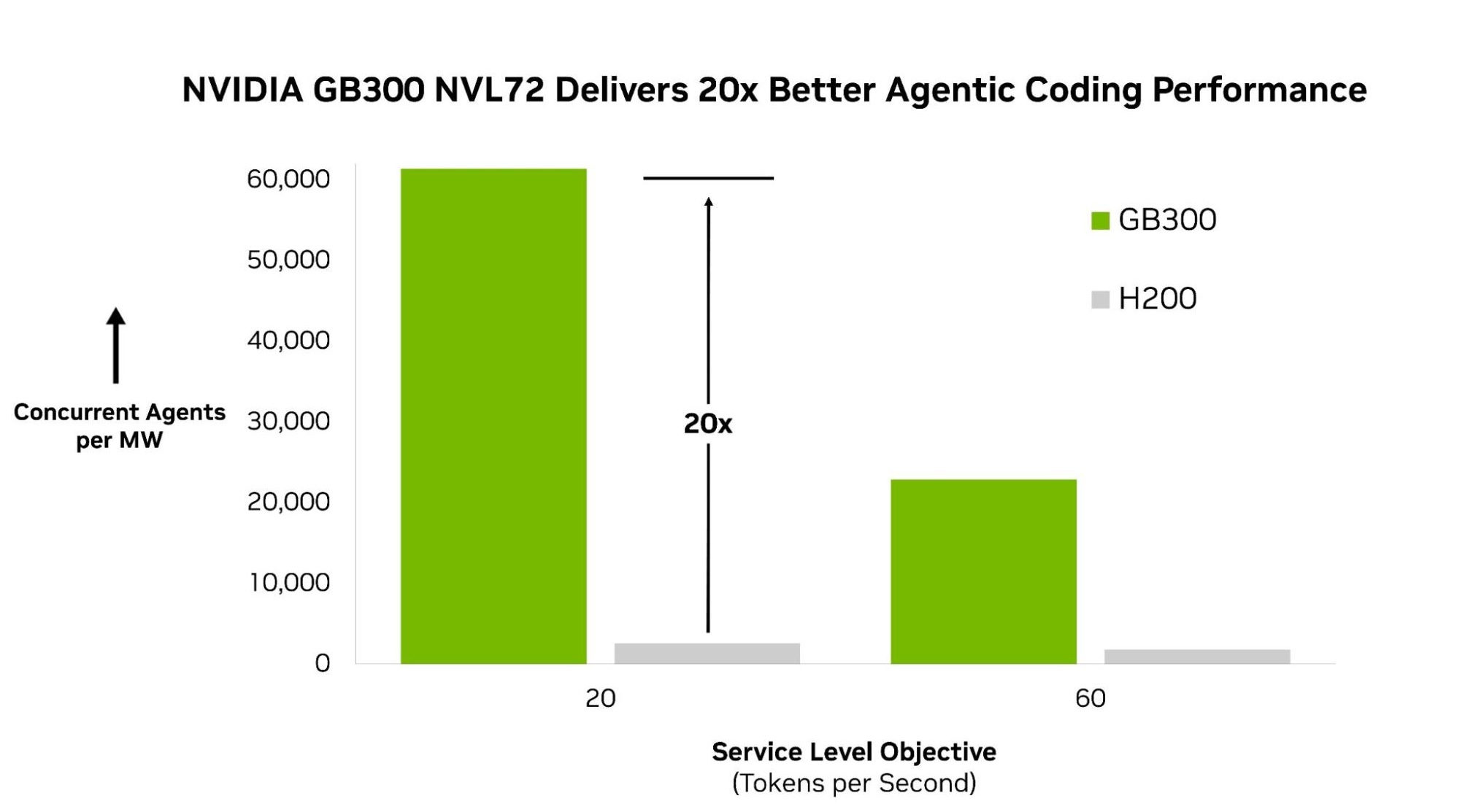
La ventaja de rendimiento viene de codiseño extremo en toda la pila. El GB300 NVL72 conecta 72 GPUs en un único sistema rack-scale, permitiendo que modelos MoE grandes como DeepSeek V4 Pro distribuyan su ejecución eficientemente a escala.
Los kernels CUDA aceleran esto al solapar comunicación y compute, de modo que el costo de coordinar entre expertos se absorbe en lugar de sumarse a la latencia. NVIDIA TensorRT LLM sostiene la eficiencia cuando las sesiones agénticas concurrentes escalan: por ejemplo, separa el procesamiento de entradas de la generación de salidas para optimizar cada uno por separado.
¿Quiénes ya usan esta infraestructura en producción?
Proveedores líderes de inferencia como Baseten, DeepInfra y Together AI ya sirven cargas agénticas sobre modelos de frontera como DeepSeek V4 Pro corriendo en NVIDIA Blackwell, alimentando aplicaciones agénticas en producción hoy.
Together AI provee inferencia en tiempo real a Cursor, la plataforma agéntica de coding, sobre NVIDIA Blackwell. Los agentes de Cursor depuran problemas, generan features y ejecutan refactors mientras los desarrolladores siguen trabajando.
DeepInfra alimenta Pam.ai, una plataforma de fuerza laboral de IA para concesionarios de autos, que despliega agentes para reservar citas de servicio, atender llamadas y correr campañas de venta saliente, todo sobre NVIDIA Blackwell.
A medida que NVIDIA y el ecosistema open source siguen optimizando el software de inferencia, el rendimiento y la eficiencia en cargas agénticas solo van a mejorar. La arquitectura NVIDIA Vera Rubin ya está en producción plena, trayendo la próxima generación de capacidad de infraestructura para responder a las demandas crecientes de la IA agéntica a escala.
Detalles técnicos completos sobre la metodología de AgentPerf y las optimizaciones de NVIDIA en el blog técnico para desarrolladores.