Hasta ahora los agentes de programación con IA se han evaluado por un único indicador: ¿el agente arregló el bug, sí o no? Esa métrica esconde lo que realmente falló. Tal vez el agente nunca leyó el código relevante. Tal vez lo leyó y aun así escribió el parche equivocado. El resultado se ve igual desde afuera.
Un equipo internacional con participación de la Universidad Jiao Tong de Shanghái propone SWE-Explore, un benchmark que evalúa solo la primera fase del proceso. El agente recibe una descripción del bug y un proyecto de software, y devuelve una lista priorizada de las secciones de código que considera relevantes. Sin reparar nada todavía.
¿Qué mide exactamente SWE-Explore?
El dataset cubre 848 problemas en 203 proyectos open source y diez lenguajes de programación. Python domina con 547 de las 848 tareas, seguido por Go, JavaScript y Rust. Para cada problema existen al menos dos soluciones exitosas previas de modelos como GPT-5.4, Gemini 3 Pro, Claude Sonnet 4.6 o Kimi K2.6. De esas corridas, los investigadores extraen qué archivos y líneas el modelo realmente examinó antes de corregir el error, y los pasajes en los que dos rutas independientes convergen cuentan como contexto útil. Un paso de verificación adicional rellena pasajes clave individuales y el equipo revisa manualmente cada región otra vez.
¿Por qué la búsqueda por palabra clave fracasa?
La comparación enfrenta los métodos clásicos de búsqueda contra cinco agentes generalistas (entre ellos Claude Code, Codex y OpenHands) y cuatro sistemas de investigación diseñados específicamente para búsqueda de código.
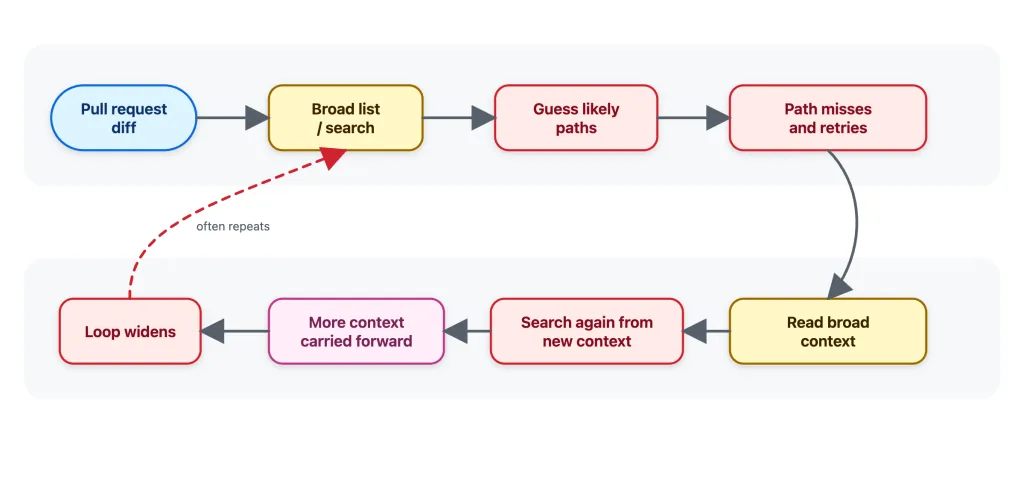
La búsqueda tradicional por palabras clave apenas supera al azar. Un mensaje de bug como "RuntimeWarning on Overflow" contiene términos que aparecen mucho más en plantillas y documentación que en el código fuente real. Los agentes IA toman ventaja porque navegan el proyecto paso a paso en vez de ordenar todos los resultados de una sola pasada.
¿Dónde se rompe la cadena: archivo o línea?
A nivel de archivo, los agentes funcionan bien. Encuentran el fichero correcto, lo rankean entre los primeros y mantienen la selección compacta. Pero el momento en que el test baja al nivel de líneas de código, el sistema se desarma. Los agentes generales cubren entre 14% y 19% de las líneas que de verdad importan.
Subir el tamaño del modelo no resuelve el problema. El equipo corrió el mismo agente con seis modelos distintos de OpenAI, Anthropic, Google, Moonshot y Zhipu. La familia GPT lidera, pero el patrón se repite: la tasa de acierto a nivel archivo se mantiene consistentemente más alta que la cobertura real de líneas. Y las arquitecturas de agentes terminan asombrosamente cerca entre sí: Claude Code, Codex, OpenHands, Mini-SWE-Agent y AweAgent registran puntajes casi idénticos en todas las métricas.
El sistema CoSIL es la excepción. Escanea el código como una red de bloques interconectados y consigue una cobertura de líneas mucho más alta. Entre los localizadores especializados, AutoCodeRover trabaja con precisión pero se queda corto, y OrcaLoca produce poco ruido pero pierde muchos lugares relevantes.
¿Cuánto contexto necesita el modelo para arreglar el bug?
En un experimento de ablación controlado, el equipo varió el contexto artificialmente. El modelo de reparación veía 0%, 25%, 50%, 75% o 100% de las regiones núcleo, a veces rellenado con código no esencial. Para las tareas más simples del dataset apareció un umbral claro: mientras menos de la mitad de las regiones núcleo estén visibles, las reparaciones fracasan en la mayoría de los casos.
La tasa de éxito recién salta entre el 50% y el 75% de cobertura. Las correcciones no mejoran gradualmente: necesitan un mínimo de pistas antes de que algo encaje. Para tareas más difíciles, el efecto es mucho más estrecho. Si el problema ya excede la capacidad del modelo, ni siquiera mejor contexto ayuda demasiado.
El cuello de botella que la industria ignoró
El hallazgo de SWE-Explore no es que los agentes "no sirven". Es que el cuello de botella está en una fase distinta a la que mide la industria. Mientras los benchmarks tradicionales solo registran si el bug se arregló, este trabajo demuestra que al menos la mitad del fracaso ocurre antes de que el agente escriba una sola línea de código: en la fase de localización.
Para equipos que integran Claude Code o Codex en sus flujos de CI/CD, la lectura práctica es directa. Mejorar el prompt o subir a un modelo más capaz no resolverá el problema si el sistema sigue alimentando al agente con archivos enteros donde solo 1 de cada 5 líneas relevantes está marcada. El siguiente salto de productividad pasa por herramientas de indexación semántica que recorten el contexto antes de pedirle al modelo que decida.