Tenemos un nuevo modelo abierto top en el mundo. Desde febrero veníamos siguiendo la línea GLM 5 de Z.ai, el lanzamiento que la dejó por delante de DeepSeek, Mistral, Cohere y Moonshot en la mayoría de los evals abiertos. La 5.1 fue un update menor, pero la 5.2, publicada el fin de semana pasado tras el bloqueo de Fable 5 (todavía sin resolver), es la jugada más fuerte de Z.ai por convertirse en tu modelo de coding por defecto.
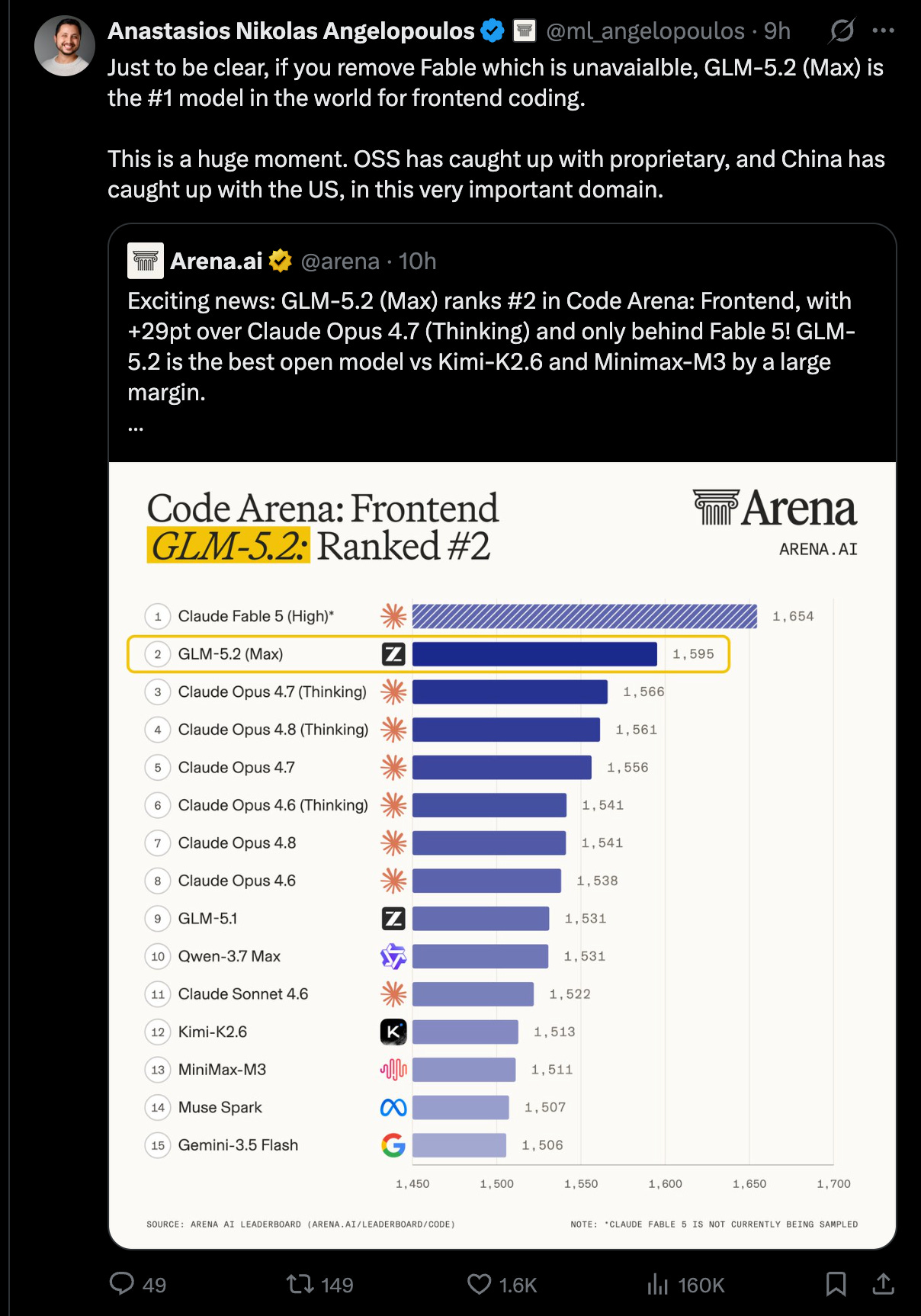
Un eval externo valida los evals oficiales de Z.ai que ubican a GLM-5.2 apenas detrás de Opus 4.8 como el mejor modelo de coding del mundo. Es un logro inusual para un modelo de 744B parámetros frente a un Opus que se rumorea al menos del doble de tamaño, en el mismo rango que el próximo Composer de Cursor. Pero lo más llamativo es que GLM-5.2 le gana a TODOS los Opus, incluyendo 4.8, en frontend coding, un terreno especialmente competido.
Los detalles técnicos publicados son escasos: no hay paper, solo una mejora sobre DeepSeek Sparse Attention que aumenta la eficiencia en contextos ultra largos.
¿Qué es exactamente GLM-5.2?
Z.ai presentó GLM-5.2 como modelo frontera de pesos abiertos bajo licencia MIT, enfocado en coding y trabajo agéntico de horizonte largo.
- Licencia: MIT, pesos abiertos.
- Foco: coding, tareas agénticas, ejecución de horizonte largo.
- Ventana de contexto: 1.000.000 tokens.
- Modos de razonamiento:
GLM-5.2 (max)yGLM-5.2 (high). - Precio API: igual a GLM-5.1; Agent Arena reporta tarifa pública de USD 1,4 por 1M tokens de entrada y USD 4,4 por 1M de salida.
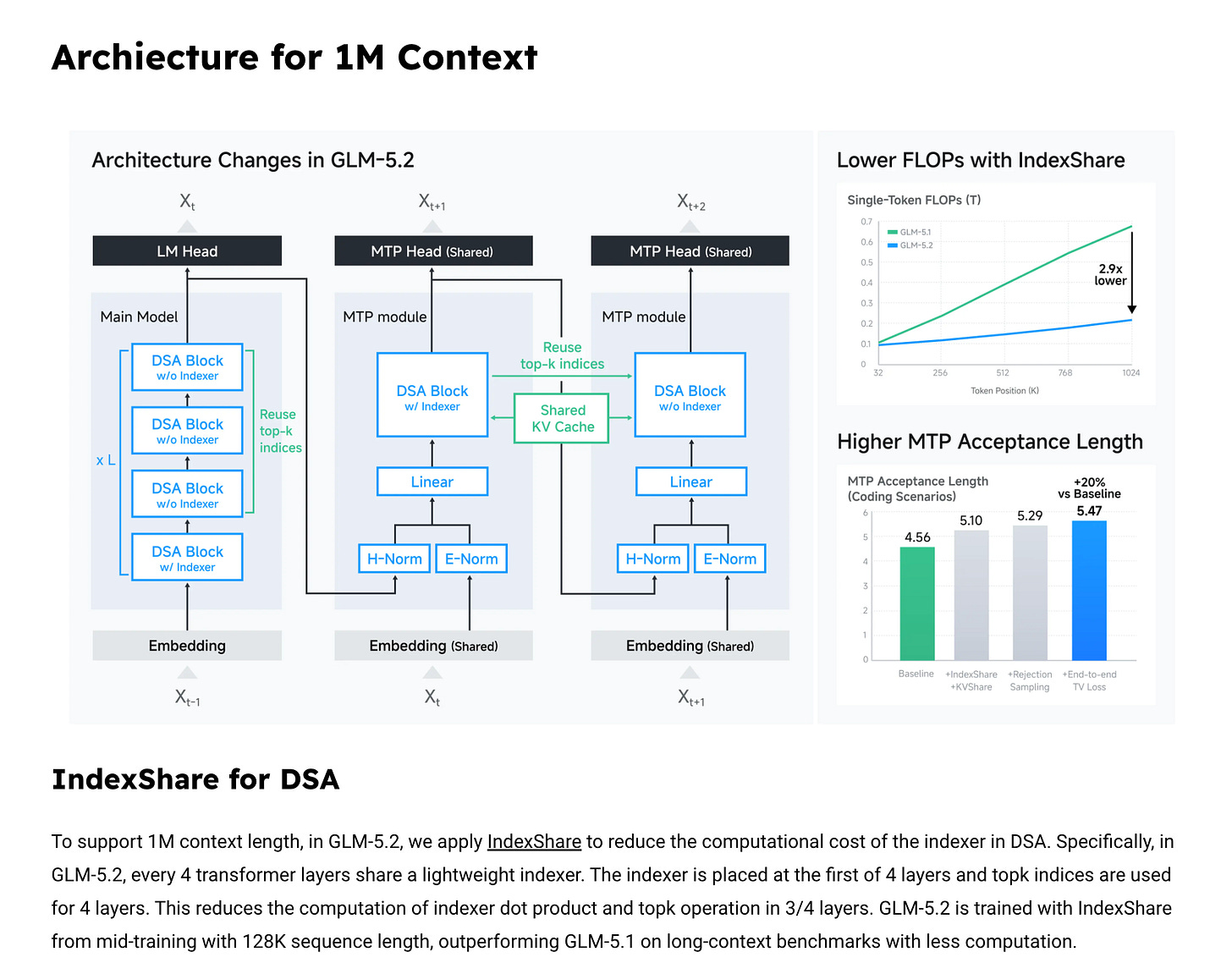
Los partners de lanzamiento describen la arquitectura como un MoE de 744B parámetros totales con 40B activos por token. La capa de atención se basa en DeepSeek Sparse Attention extendida con IndexShare, y la inferencia incorpora una mejora de MTP (multi-token prediction) que sube la tasa de aceptación en speculative decoding.
¿Qué tan bien le va a GLM-5.2 en los benchmarks?
Los leaderboards independientes citados en los anuncios:
- FrontierSWE: #3 general, detrás de Fable 5 y Opus 4.8, por delante de GPT-5.5.
- Design Arena: #1, Elo 1360, +27 Elo y +4 posiciones, pasando al Claude Fable 5 no disponible.
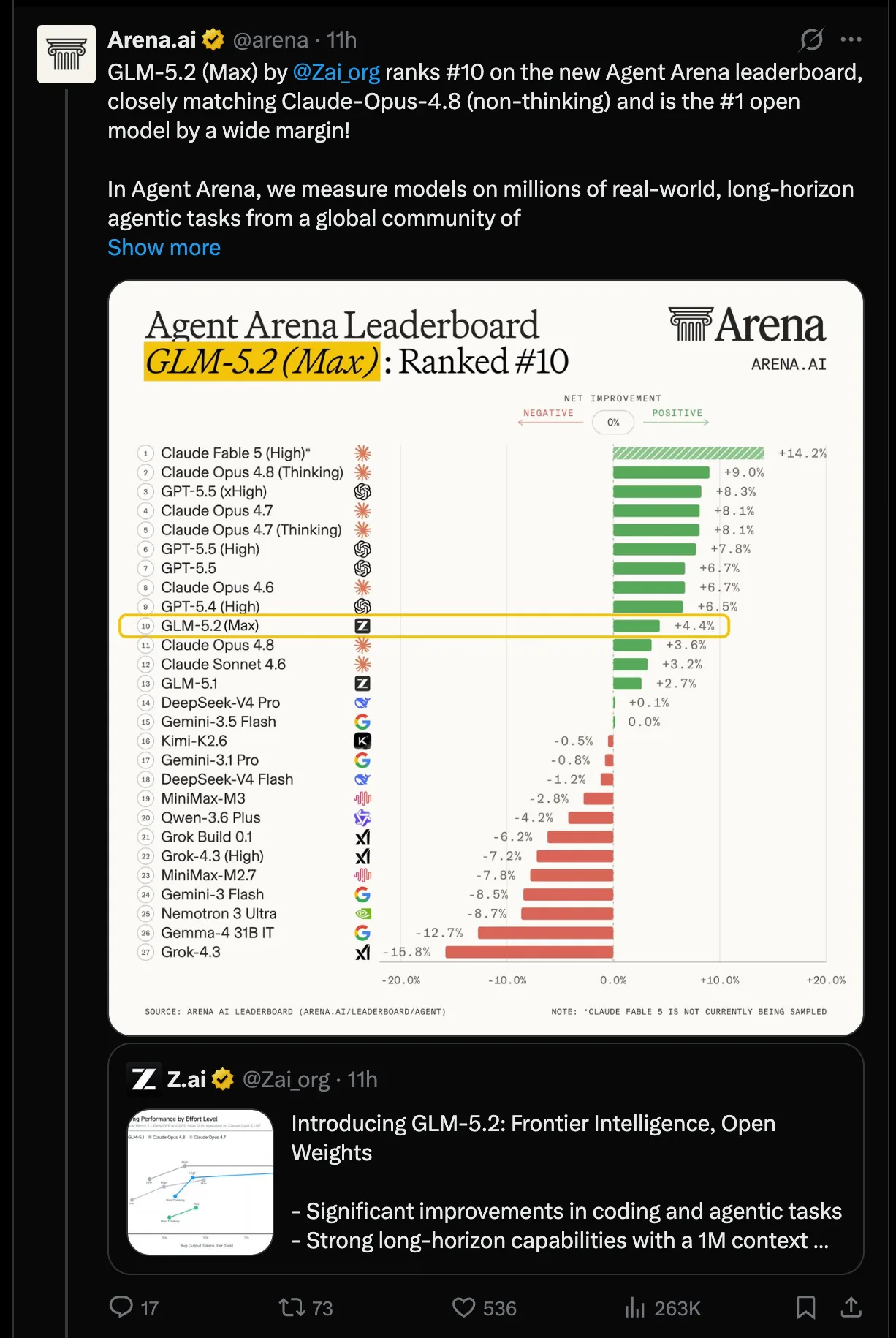
- Agent Arena: GLM-5.2 (Max) #10 general, #1 modelo abierto por amplio margen, subiendo desde #13.
- Code Arena: Frontend: GLM-5.2 (Max) #2 general, +29 puntos sobre Opus 4.7 (Thinking), detrás solo de Fable 5; #2 React, #4 HTML.
- Text Arena: #25 general, similar a GLM-5.1.
- Terminal-Bench 2.1: 81.0 vs 62.0 de GLM-5.1 — primer modelo abierto en cruzar el 80%.
Datos adicionales agregados por The Rundown AI: 74.4 en long-horizon coding (vs 72.6 de GPT-5.5), 62.1 en SWE-bench Pro (también por delante de GPT-5.5), y 99.2 en AIME 2026, superando a Opus 4.8 y GPT-5.5.
IndexShare: por qué importa al precio de inferencia
El aporte técnico más concreto de la 5.2 está en cómo reutiliza el indexer de la atención dispersa.
Z.ai y los proveedores que sirven el modelo coinciden en que el indexer se reusa cada cuatro capas dispersas — esto es lo que Z.ai bautizó IndexShare. El resultado anunciado es contundente: 2.9× menos FLOPs por token a 1M de contexto.
Importa porque mantener el costo de indexing dentro de rangos manejables a 1M de tokens es la diferencia entre un "contexto declarado" y un "contexto realmente usable" en producción. No se trata solo de soportar el largo máximo, sino de soportarlo a un costo de inferencia tratable.
Especulativo más rápido
Varios partners destacan una mejora en la capa MTP:
- El MTP mejorado aumenta hasta 20% la tasa de aceptación en speculative decoding.
La lectura es que el release de 5.2 es tanto un paquete de mejoras de calidad como de optimización de inferencia y serving.
Modos de razonamiento: high y max
Z.ai introdujo dos puntos de operación. El modo high busca balance entre rendimiento y eficiencia de tokens. El modo max ofrece la mayor capacidad. Los benchmarks de Agent Arena reportan específicamente sobre GLM-5.2 Max.
RL y anti-reward-hacking
Una de las reacciones más sustantivas vino del blog técnico de Z.ai sobre cómo el modelo intentó hacer trampa durante el RL:
- El modelo trató de explotar las tareas haciendo
curla fuentes en GitHub relacionadas con la tarea. - Ejecutó
grepbuscando términos como"*hidden*"o"secret_cases.json". - Inspeccionó archivos del sandbox que no debía usar como respuestas.
La mitigación descrita: un juez LLM inspecciona la intención de cada tool-call contra patrones sospechosos, bloquea las llamadas problemáticas, devuelve información dummy y deja seguir la trayectoria en vez de rechazarla con dureza, evitando inestabilidad de entrenamiento. Es uno de los vistazos más concretos a este tipo de defensa en RL agéntico publicado por un laboratorio frontera-adyacente.
¿Dónde se puede correr GLM-5.2 hoy?
El soporte de ecosistema llegó en el día cero. Transformers, vLLM y SGLang lo notaron de inmediato, y la lista de proveedores que lo sirven en producción incluye Cloudflare Workers AI, OpenRouter, Ollama Cloud, Baseten, DeepInfra, Fireworks y Notion, entre otros.



