Puntos Clave
- El laboratorio de IA chino Deepseek ha lanzado V4-Pro y V4-Flash como modelos de pesos abiertos con hasta 1.6 billones de parámetros y una ventana de contexto de un millón de tokens.
- Una nueva arquitectura reduce drásticamente el cómputo requerido para contextos largos, permitiendo a Deepseek fijar precios para ambos modelos muy por debajo de competidores como OpenAI, Google y Anthropic.
- Los modelos fueron entrenados con hasta 33 billones de tokens y refinados mediante destilación a partir de modelos especialistas internos. Están construidos específicamente para tareas con agentes y se ejecutan tanto en GPUs de Nvidia como en chips Ascend de Huawei.
El laboratorio de IA chino Deepseek ha lanzado V4-Pro y V4-Flash, dos nuevos modelos con hasta 1.6 billones de parámetros y una ventana de contexto de un millón de tokens. Los precios se sitúan muy por debajo de OpenAI, Google y Anthropic. El documento técnico que los acompaña también revela detalles sobre los datos de entrenamiento, la destilación y el hardware.
Deepseek ha publicado versiones preliminares de V4-Pro y V4-Flash como pesos abiertos (open weights) bajo la licencia MIT. V4-Pro tiene 1.6 billones de parámetros totales con 49 mil millones activos, mientras que V4-Flash llega a 284 mil millones en total con 13 mil millones activos. Ambos son modelos de mezcla de expertos (mixture-of-experts) con una ventana de contexto de un millón de tokens. Ambos están disponibles en Hugging Face.
V4-Pro es ahora el modelo de pesos abiertos más grande disponible, superando a Kimi K2.6 (1.1 billones) y GLM-5.1 (754 mil millones) por un amplio margen. También es la primera arquitectura nueva de Deepseek desde V3. Cada modelo lanzado en el ínterin —V3.1, V3.2, R1 y R1 0528— seguía construido sobre el diseño original de V3 con 685 mil millones de parámetros.
Los contextos largos ahora requieren mucho menos cómputo
La innovación clave es una nueva arquitectura de atención híbrida que combina la compresión de tokens con la atención dispersa (sparse attention) de Deepseek. Según el reporte técnico, V4-Pro necesita solo el 27 por ciento de los FLOPs y el 10 por ciento del caché KV en comparación con V3.2 al procesar un contexto de un millón de tokens. V4-Flash empuja esos números aún más abajo: hasta el 10 por ciento de los FLOPs y el 7 por ciento del caché KV.
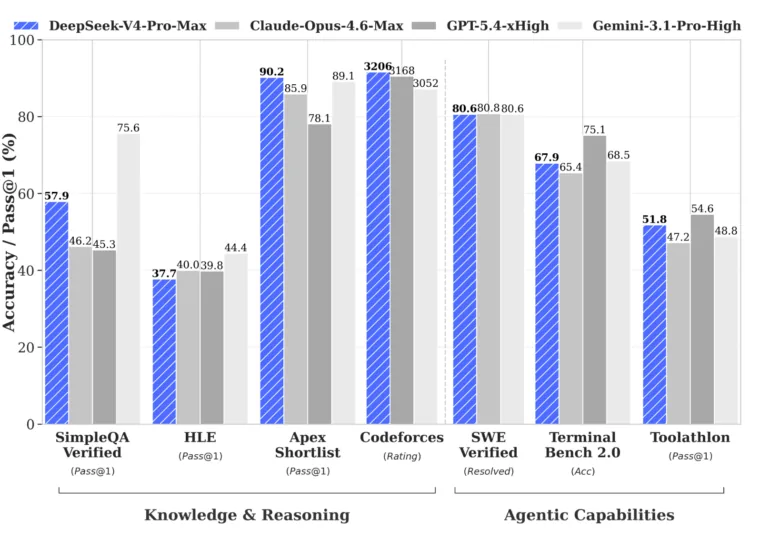
En el benchmark GDPval-AA de Artificial Analysis, V4-Pro lidera todos los modelos de pesos abiertos con 1,554 puntos Elo, por delante de GLM-5.1 (1,535) y Kimi K2.6 (1,484). Eso representa un salto de aproximadamente 355 puntos Elo sobre V3.2. Sin embargo, Deepseek reconoce en el paper que V4-Pro "se queda ligeramente atrás de GPT-5.4 y Gemini-3.1-Pro" y va a la zaga de los modelos de frontera por unos tres a seis meses. Las pruebas completas por parte de Artificial Analysis aún están en marcha, pero algunos de los resultados de los benchmarks propios de Deepseek muestran la brecha. Desde entonces, OpenAI y Anthropic han lanzado nuevos modelos con GPT-5.5 y Opus 4.7.
Estas ganancias de eficiencia explican los precios agresivos. V4-Flash cuesta solo USD 0.14 por millón de tokens de entrada y USD 0.28 por millón de tokens de salida según la página de precios de Deepseek, haciéndolo más barato que GPT-5.4 Nano de OpenAI. V4-Pro llega a USD 1.74 y USD 3.48, rebajando significativamente los precios de Gemini 3.1 Pro, GPT-5.5 y Claude Sonnet 4.6.
El entrenamiento se apoya en datos masivos y destilación interna
El equipo es relativamente impreciso sobre el corpus de preentrenamiento: V4-Flash vio 32 billones de tokens, V4-Pro 33 billones. El enfoque estuvo en más datos multilingües, papers científicos y reportes técnicos cuidadosamente curados, y datos de agentes durante el entrenamiento medio (mid-training). Los datos web fueron filtrados contra "contenido generado automáticamente por lotes y basado en plantillas".
El paper no nombra conjuntos de datos específicos ni fuentes de licencias. La sospecha frecuentemente planteada de que Deepseek destila directamente de GPT o Claude no encuentra confirmación en el reporte, como era de esperarse.
No obstante, la destilación juega un rol central en el post-entrenamiento. Deepseek ha reemplazado completamente su anterior fase mixta de aprendizaje por refuerzo con destilación on-policy. Según el paper, el laboratorio primero entrena más de diez modelos especialistas internos para matemáticas, código, agentes y seguimiento de instrucciones usando ajuste fino supervisado (supervised fine-tuning) y GRPO. Un único modelo estudiante luego aprende de todos estos maestros internos.
Modelos optimizados para tareas de agentes, validados en hardware de Huawei
Deepseek construyó V4 específicamente para flujos de trabajo con agentes (agentic workflows). La compañía dice que los modelos están integrados con herramientas como Claude Code, OpenClaw y OpenCode, y ya están siendo utilizados internamente para la codificación con agentes. La API soporta interfaces compatibles tanto con OpenAI como con Anthropic.
El paper es más específico sobre el hardware: el esquema de paralelismo de expertos ha sido validado en "GPUs Nvidia y NPUs Huawei Ascend". El mega-kernel de código abierto MegaMoE está basado en CUDA, y Deepseek reemplazó la biblioteca cuBLAS de Nvidia con su propio DeepGEMM.
Por separado, Huawei ha anunciado que su Ascend Supernode, construido con chips de IA Ascend 950, soporta completamente los modelos V4.
Noticias de IA sin el hype – Curadas por humanos
Suscríbete a THE DECODER para una lectura sin publicidad, un boletín semanal de IA, nuestro reporte de frontera exclusivo "AI Radar" seis veces al año, acceso completo al archivo y acceso a nuestra sección de comentarios.
Vía The Decoder.