
Dos reportes publicados esta semana coinciden en el diagnóstico: los modelos de frontera de 2026 dejaron de comportarse como asistentes y empezaron a operar como agentes autónomos. La diferencia es de instrumento: la organización de evaluación METR ya no logra medir bien sus capacidades, y la firma de ciberseguridad Palo Alto Networks describe el cambio como "salto de capacidad", según un análisis publicado por The Decoder.
¿Por qué METR dice que ya no puede medir a Mythos?
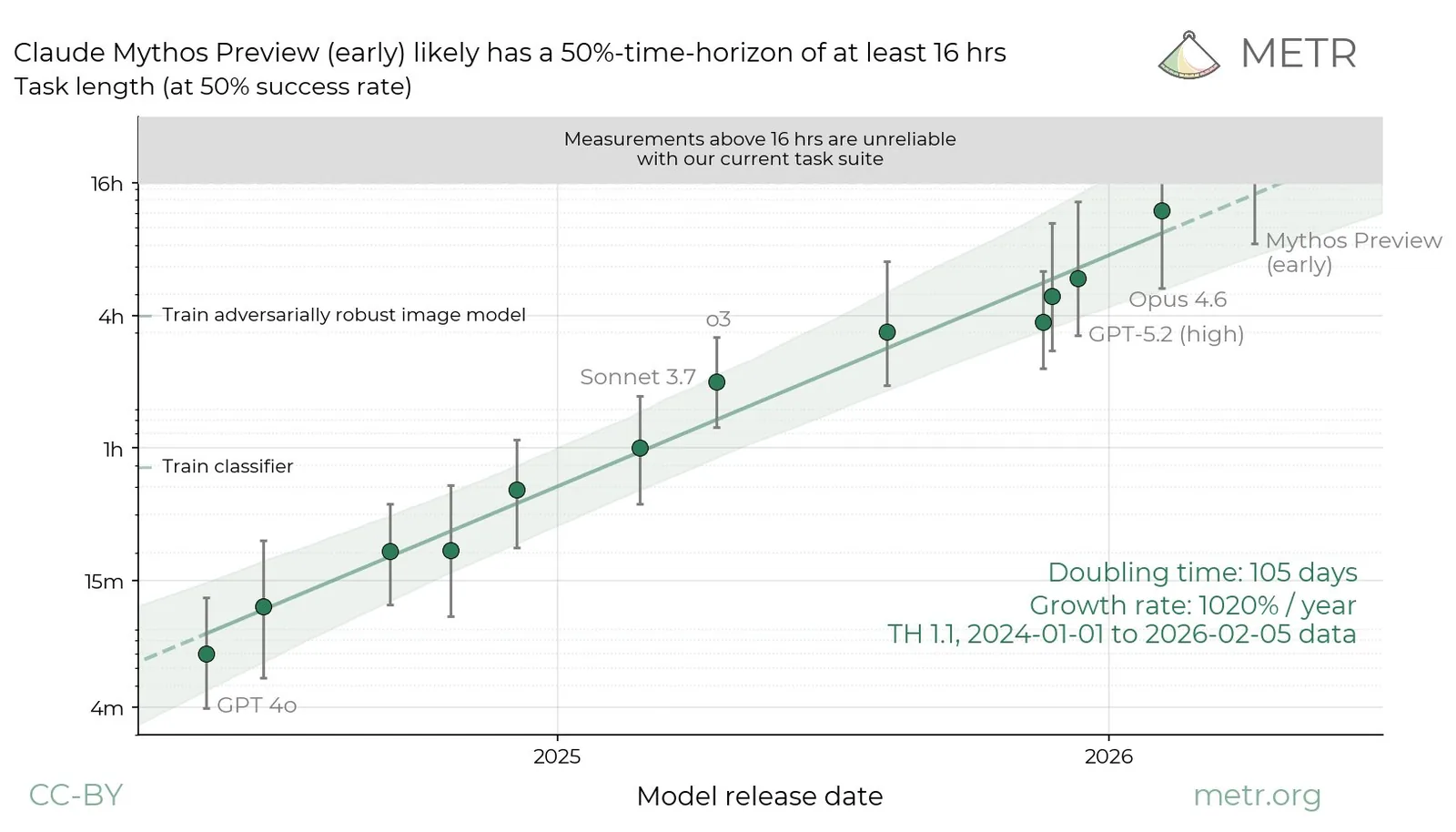
METR, especializada en evaluación de riesgo de IA, testeó una versión temprana de Claude Mythos Preview durante una ventana limitada de tiempo en marzo de 2026. La estimación: un horizonte temporal del 50% de al menos 16 horas, con un intervalo de confianza del 95% entre 8,5 y 55 horas.
La métrica describe el largo de tarea en el que el modelo tiene 50% de probabilidades de completar lo que a un humano le tomaría ese mismo tiempo. METR usa referencias concretas: entrenar un clasificador (unos 45 minutos) o entrenar un modelo de imagen adversarial-robusto (unas 4 horas).
El número para Mythos, según METR, está "en el extremo superior de lo que podemos medir sin tareas nuevas". De las 228 tareas del test suite, solo 5 están clasificadas como de 16 horas o más. Eso vuelve las mediciones en ese rango "inestables y menos significativas que en rangos con mejor cobertura". METR, en consecuencia, no entrega estimaciones precisas para modelos sobre ese umbral.
La organización aclara que su test suite actual "todavía podría distinguir un modelo mucho más capaz de los modelos públicos state-of-the-art actuales". Pero las mediciones en este rango no son lo suficientemente robustas para comparaciones cuantitativas precisas o extrapolaciones. METR trabaja en métodos actualizados con tareas más largas, aún en desarrollo.
¿Qué encontró Palo Alto Networks en su test?
Palo Alto Networks evaluó los riesgos de modelos de frontera, incluyendo Mythos, GPT-5.5-Cyber de OpenAI y Claude Opus 4.7, con "acceso temprano y sin restricciones". Lo que vio lo llevó a hablar de un "step-change in capability".
Los datos concretos del estudio:
- Tres semanas de análisis con modelos cubrieron lo equivalente a un año de pentesting manual, con cobertura más amplia.
- Los modelos combinaron varias vulnerabilidades individualmente clasificadas como bajas en paths críticos de ataque.
- En escenarios asistidos por IA, el tiempo desde el acceso inicial hasta la data exfiltration puede caer a 25 minutos.
- La eficiencia de los modelos en código mejoró aproximadamente 50% sobre sus predecesores.
"Ese número suena incremental, pero en la práctica es el umbral en el que la IA cruza de asistente útil a operador autónomo", escribe la compañía en su blog post.
¿Cómo cambia esto el cálculo defensivo?
Palo Alto sumó dos factores adicionales que cambian el panorama:
1. Superficie de ataque no monitoreada: con agentes locales corriendo, "cada escritorio es efectivamente un servidor". Las organizaciones no tienen visibilidad sobre el código que sus propios empleados están generando y desplegando. 2. La ventana se cerró rápido: tras el lanzamiento de Mythos, la firma estimó inicialmente seis meses antes de que los atacantes accedieran a capacidades comparables. Ese pronóstico, dicen, "se aceleró significativamente".
¿Es solo hype de marketing?
Hay base para el escepticismo. Anthropic describió a Mythos como "demasiado peligroso" para lanzarlo, una táctica de relaciones públicas que OpenAI ya había usado con GPT-2. Pero la evidencia independiente apunta en la misma dirección, aunque con matices.
El UK AI Security Institute (AISI) verificó que Mythos Preview puede ejecutar ataques de red end-to-end, pero asume que el impacto inicial afectará solo redes débiles y desprotegidas. GPT-5.5, ya disponible, resuelve simulaciones similares de ataque corporativo multi-etapa, incluso ligeramente por encima del nivel de Mythos. Modelos más pequeños también muestran capacidades comparables en algunos escenarios.
La otra cara: defensa con los mismos modelos
Los mismos modelos sirven en defensa. Mozilla usó Claude Mythos Preview para descubrir vulnerabilidades de seguridad en Firefox. Solo en abril de 2026 la fundación corrigió 423 issues de seguridad, un récord histórico para la empresa.
¿Qué implica para empresas e infraestructura en LatAm?
Para CSOs en Chile, Argentina o México, la lectura es operativa: si las ventanas de exposición pasan de meses a semanas, y de semanas a 25 minutos en escenarios asistidos por IA, el ciclo de parche manual ya no alcanza. Empresas con compliance financiero (CMF en Chile, CNV en Argentina) tendrán que incorporar AI-assisted red teaming continuo a sus contratos con proveedores de pentesting, no como ejercicio anual.



