Nathan Lambert publicó un nuevo episodio del podcast Interconnects con Finbarr Timbers (investigador en Ai2), repasando cómo cambió la forma de hacer post-training en los modelos de frontera de los últimos cuatro años. La conversación acompaña el material que Lambert está armando para su RLHF / Post-training book y el curso asociado.
La forma de una receta de post-training cambió más en el último año que en los tres anteriores.
- 2022-2023 (InstructGPT): un solo pipeline: SFT → reward model → RL.
- 2024 (Llama 3, Tülu 3, etc.): las recetas abiertas formalizan SFT → DPO → RL con recompensas verificables. Las cerradas usan muchas etapas de RLHF.
- 2025 (DeepSeek R1): el RL de razonamiento (R1) pone al RL a gran escala en el centro.
- 2026 (MiMo Flash V2): las recetas se fragmentan en muchos modelos especialistas que se fusionan de vuelta en uno solo.
¿Qué es MOPD y por qué emerge en 2026?
La Destilación On-Policy Multi-Profesor (Multi-teacher On-Policy Distillation, MOPD) es el patrón que aparece en toda la frontera 2026:
- Se entrenan N profesores especialistas por dominio (cada uno: SFT, luego RL en los dominios relevantes).
- Se entrena un único estudiante general muestreando sus propias trayectorias (este será el modelo final post-entrenado).
- En cada rollout, se minimiza la divergencia KL inversa contra la distribución de salida del profesor relevante, token a token.
Linaje: MiMo Flash v2 lo introdujo, DeepSeek V4 y Nemotron 3 Ultra lo escalan a más de 10 profesores.
¿Por qué emergió MOPD?
- El RL se puso caro y conflictivo. Mezclar matemáticas, código y RL agéntico en una misma corrida termina sacrificando capacidades entre sí.
- Los especialistas son baratos de armar y escalan organizacionalmente. SFT-luego-RL sobre un solo dominio está bien entendido y paralelizable. Cuando el post-training se vuelve más complejo, escalarlo entre equipos es ganancia limpia.
- La destilación on-policy maduró. La literatura y el know-how siguieron emergiendo durante el renacimiento del RLVR.
Fuentes: DeepSeek V4 §5.1, MiMo-V2-Flash.
¿Cuáles son las recetas históricas clave?
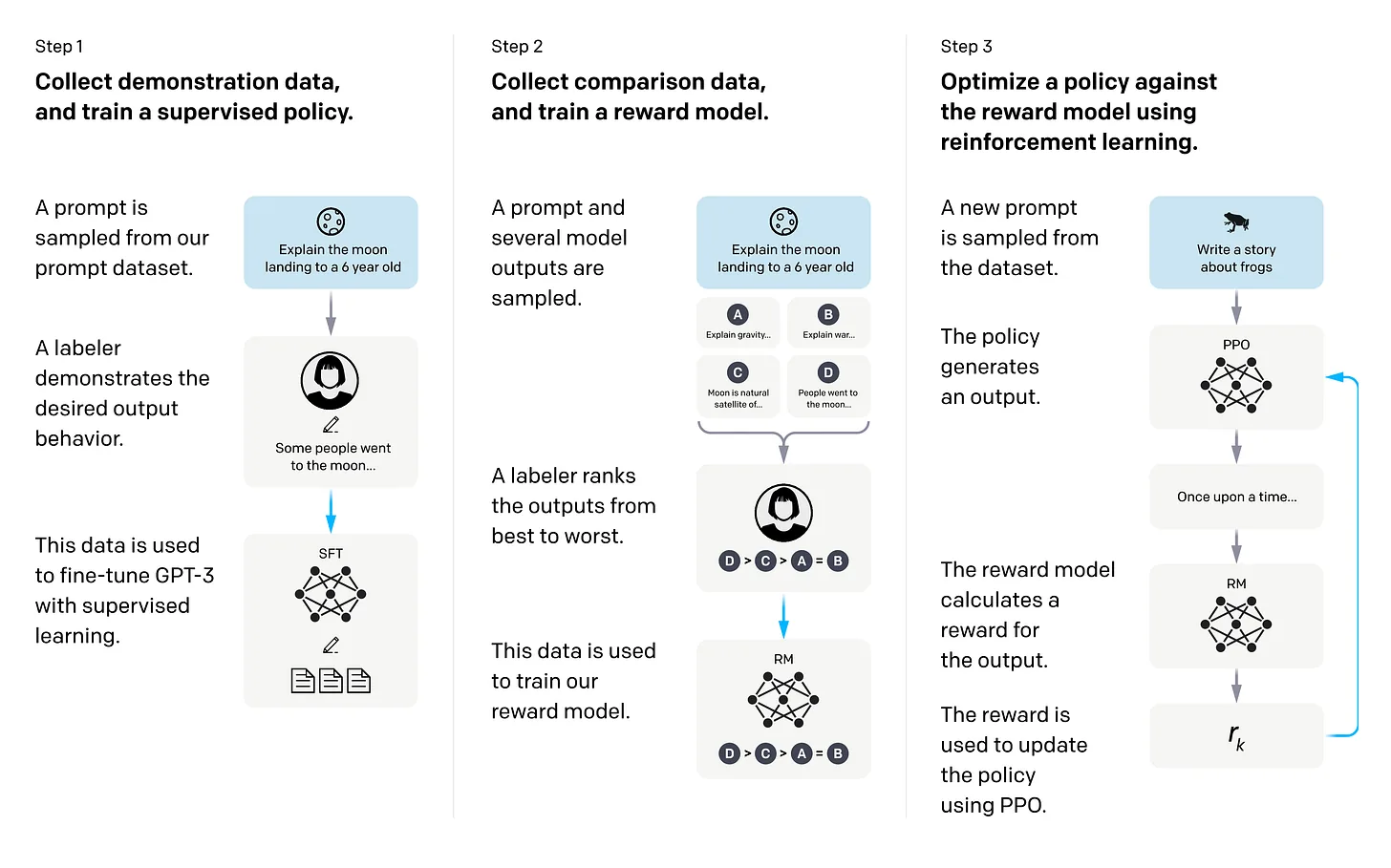
InstructGPT (marzo 2022): los tres pasos canónicos · paper
- SFT sobre demostraciones humanas.
- Reward model entrenado sobre comparaciones humanas.
- PPO contra el reward model.
Llama 2 (julio 2023): RLHF multietapa · paper · recap de Interconnects
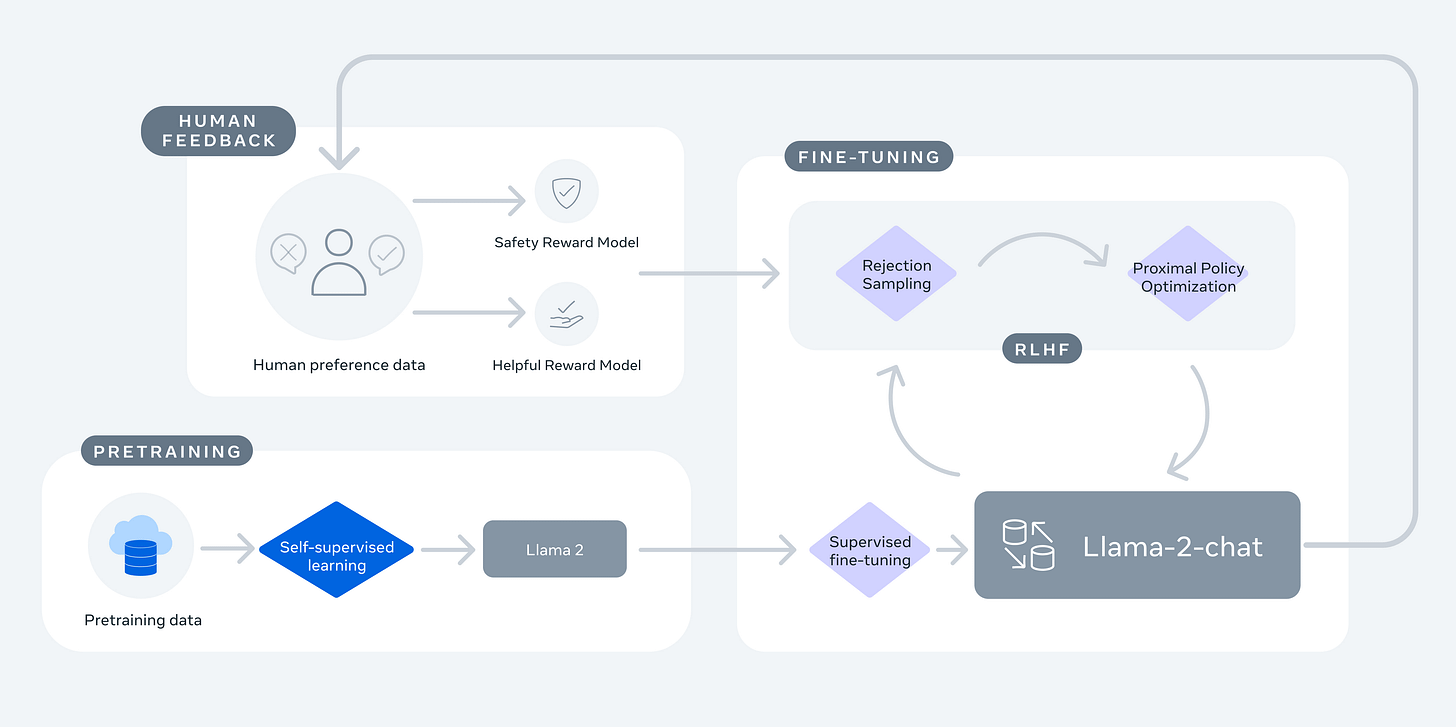
- SFT, luego RLHF iterativo sobre varias rondas.
- Cada ronda: rejection sampling → PPO.
- Dos reward models: helpfulness y seguridad separados.
Llama 3 (julio 2024): receta multietapa compleja con optimizadores simples · paper · recap
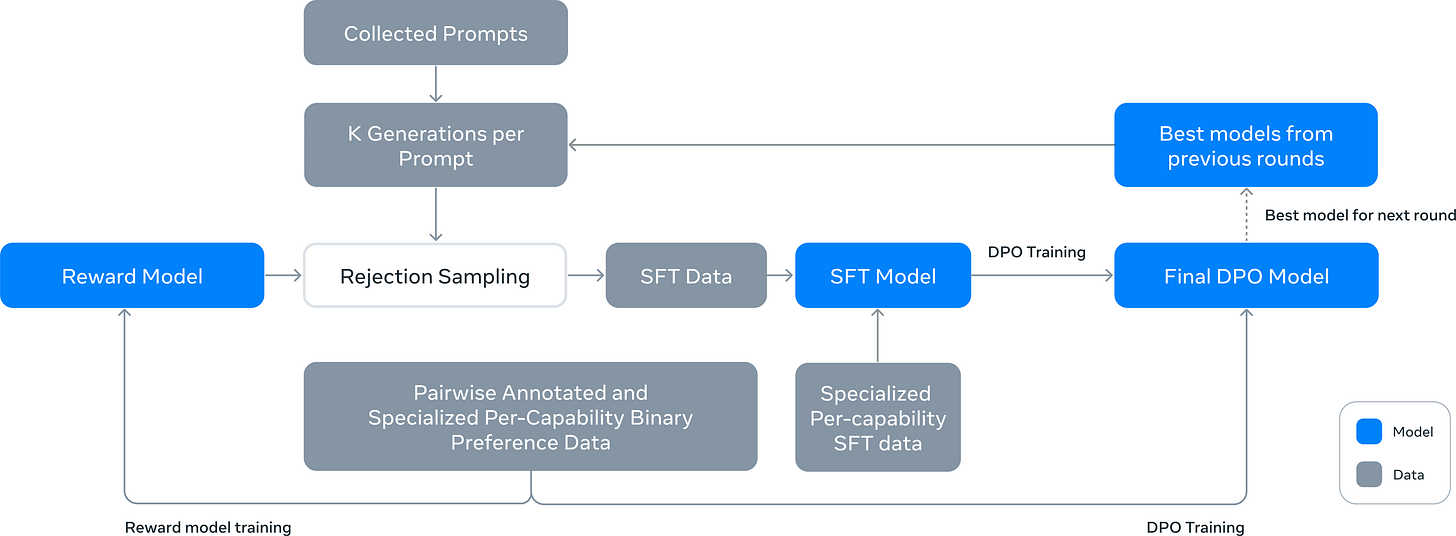
- Por ronda: reward model → muestrear K por prompt → rejection sampling → SFT → DPO.
- Sin RL online: el RM solo filtra; se corre por 6 rondas, los mejores modelos siembran la siguiente.
Tülu 3 (noviembre 2024): post-training simple de tres etapas · paper · recap
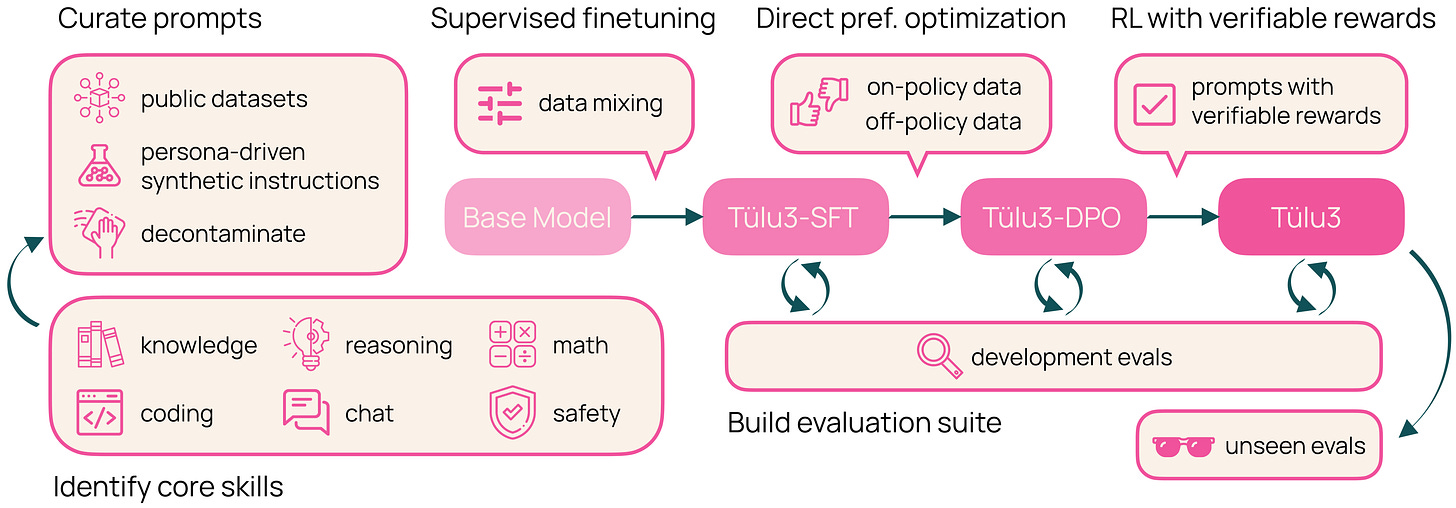
Curar prompts → SFT → DPO → RLVR (RL with verifiable rewards, acrónimo acuñado en este paper).
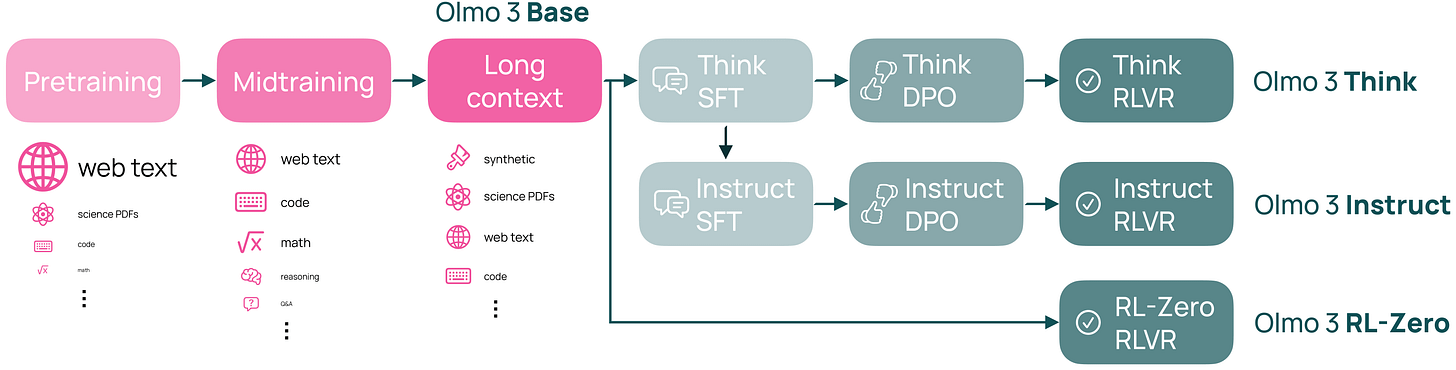
OLMo 3 (diciembre 2025): actualización de razonamiento sobre la receta de Tülu 3 · paper · recap
DeepSeek R1 (enero 2025): el RL como pieza central · paper · recap
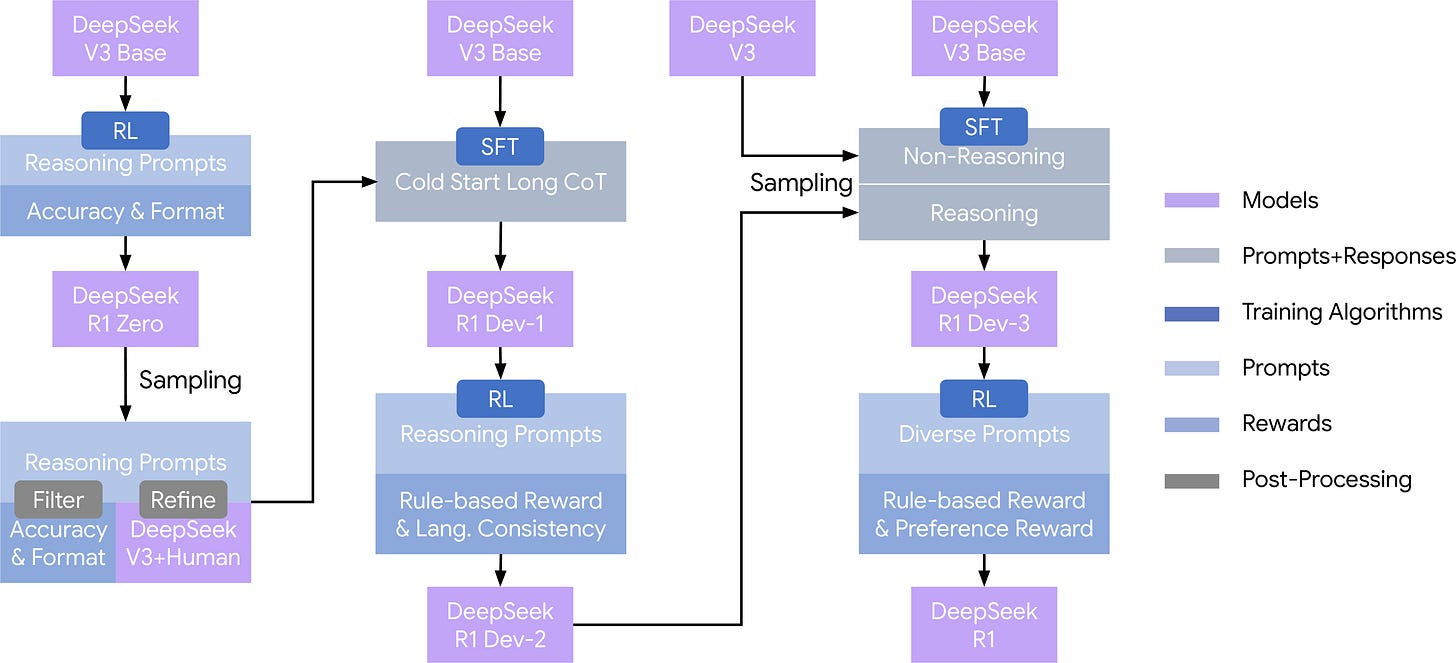
- R1-Zero: RL puro (GRPO) sobre la base, sin SFT; usado para sembrar conductas de razonamiento en la corrida completa, no como producto separado.
- R1: cold-start SFT → RL de razonamiento → rejection-sampling SFT → RL final → destilar a denso.
- Gran cambio en recetas: RLVR a gran escala como driver primario; SFT para destilar y refinar conductas RL.
¿Cómo evolucionó DeepSeek después de V3?
- V3 (diciembre 2024): SFT + GRPO RL.
- R1 (enero 2025): RL multietapa; el razonamiento emerge.
- V3.1 (agosto 2025): híbrido think / non-think en un solo modelo.
- V3.2 (diciembre 2025): 6 especialistas vía RL → destilación SFT → un solo GRPO mezclado.
- V4 (abril 2026): 10+ expertos de dominio → MOPD.
¿Qué recetas marcan el estilo 2026?
MiMo Flash v2 (enero 2026): donde empezó MOPD · paper
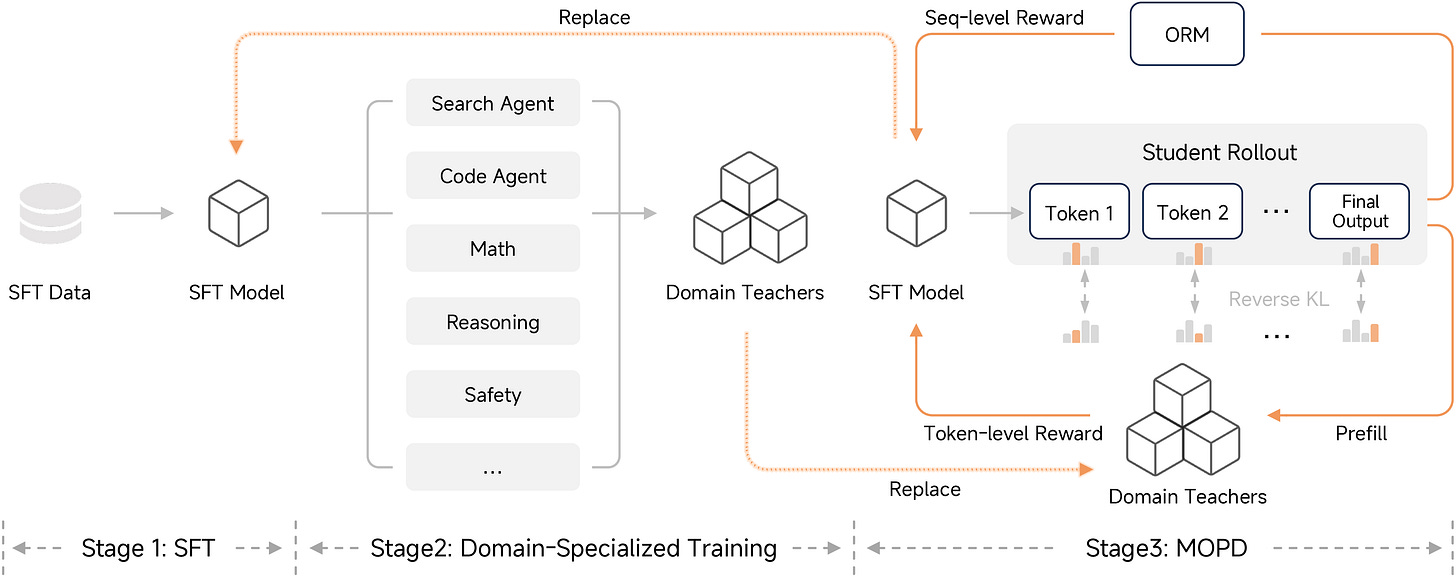
Etapas: Stage 1 SFT → Stage 2 entrenar ~6 profesores especialistas por dominio (con recetas de post-training más viejas) → Stage 3 MOPD hacia un único estudiante.
Primera articulación limpia de la destilación on-policy multi-profesor como paso de consolidación: reemplaza una etapa de RL monolítica por destilar-desde-especialistas.
Nemotron 3 Ultra (junio 2026): dos rondas, muchos profesores · paper
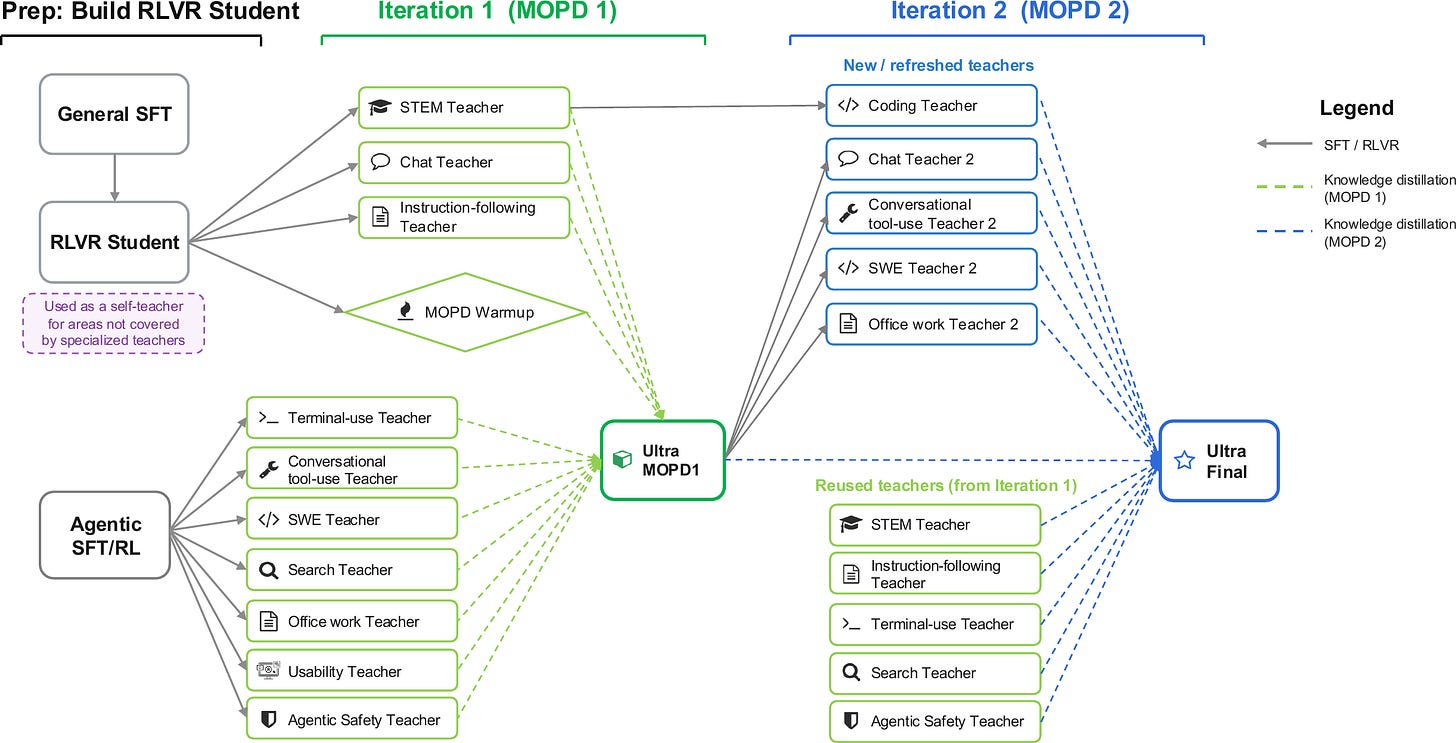
Etapas: SFT → destilación on-policy multi-profesor, corrida en dos iteraciones, con más de 10 profesores cubriendo razonamiento, código, matemáticas y dominios agénticos.
Novedoso: MOPD multironda a través de dominios distintos: destilar y luego re-destilar desde profesores refrescados.
MAI-Thinking-1 (junio 2026): más cerca de R1 que de V4 · anuncio

Etapas: base con mid-training → 3 "subidas" de RL especialistas (ej. STEM) → SFT de destilación de trazas para consolidarlas → subida RL final → MAI-Thinking-1.
Más cercano a DeepSeek R1 que a V4: RL multietapa con SFT de destilación de trazas para consolidar, sin MOPD on-policy. No es el único laboratorio sin MOPD.
Kimi K2.5 (enero 2026): agéntico, multimodal · paper · blog
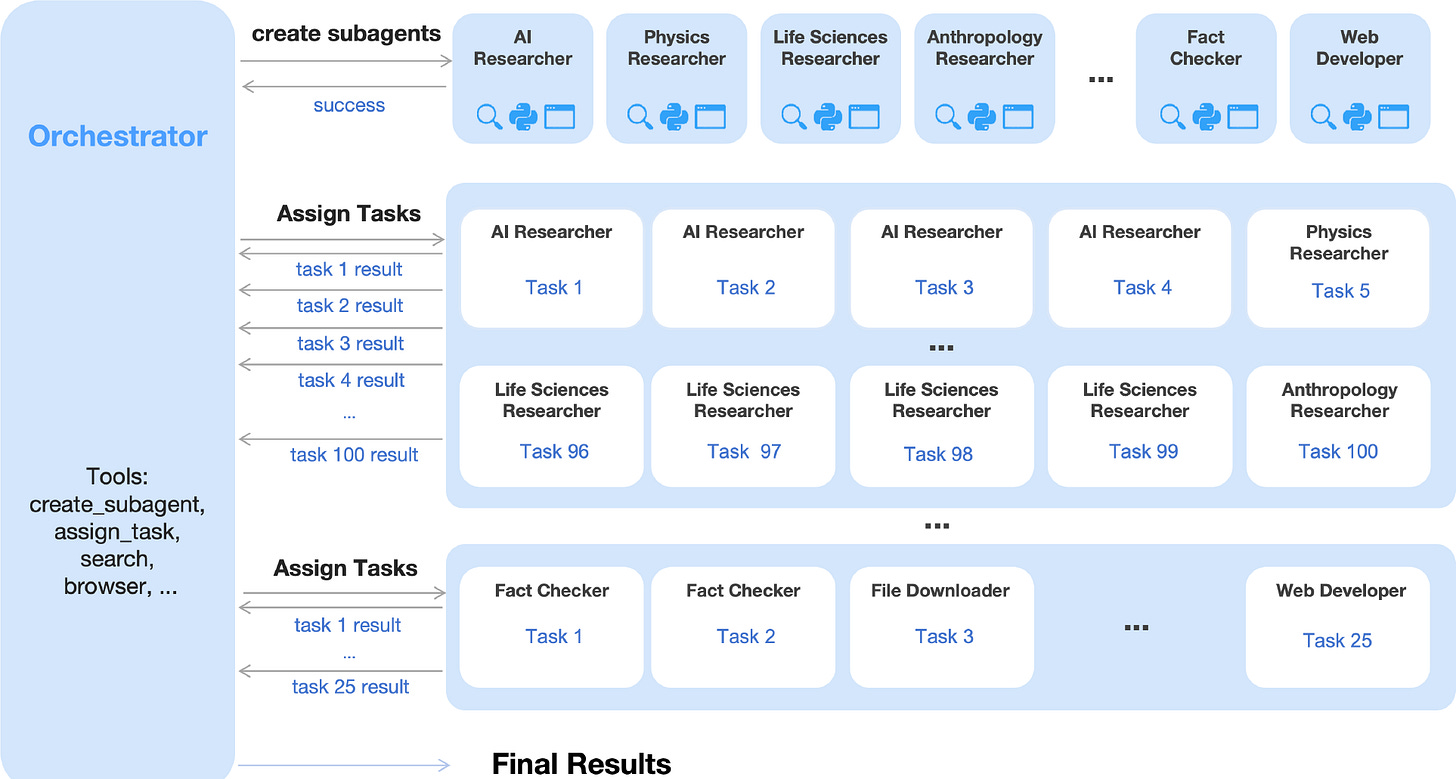
Etapas: SFT solo-texto → RL conjunto texto-visión a través de coding, visión, razonamiento y tareas agénticas. No menciona MOPD.
GLM-5 (febrero 2026): RL escalonado por capacidad · paper
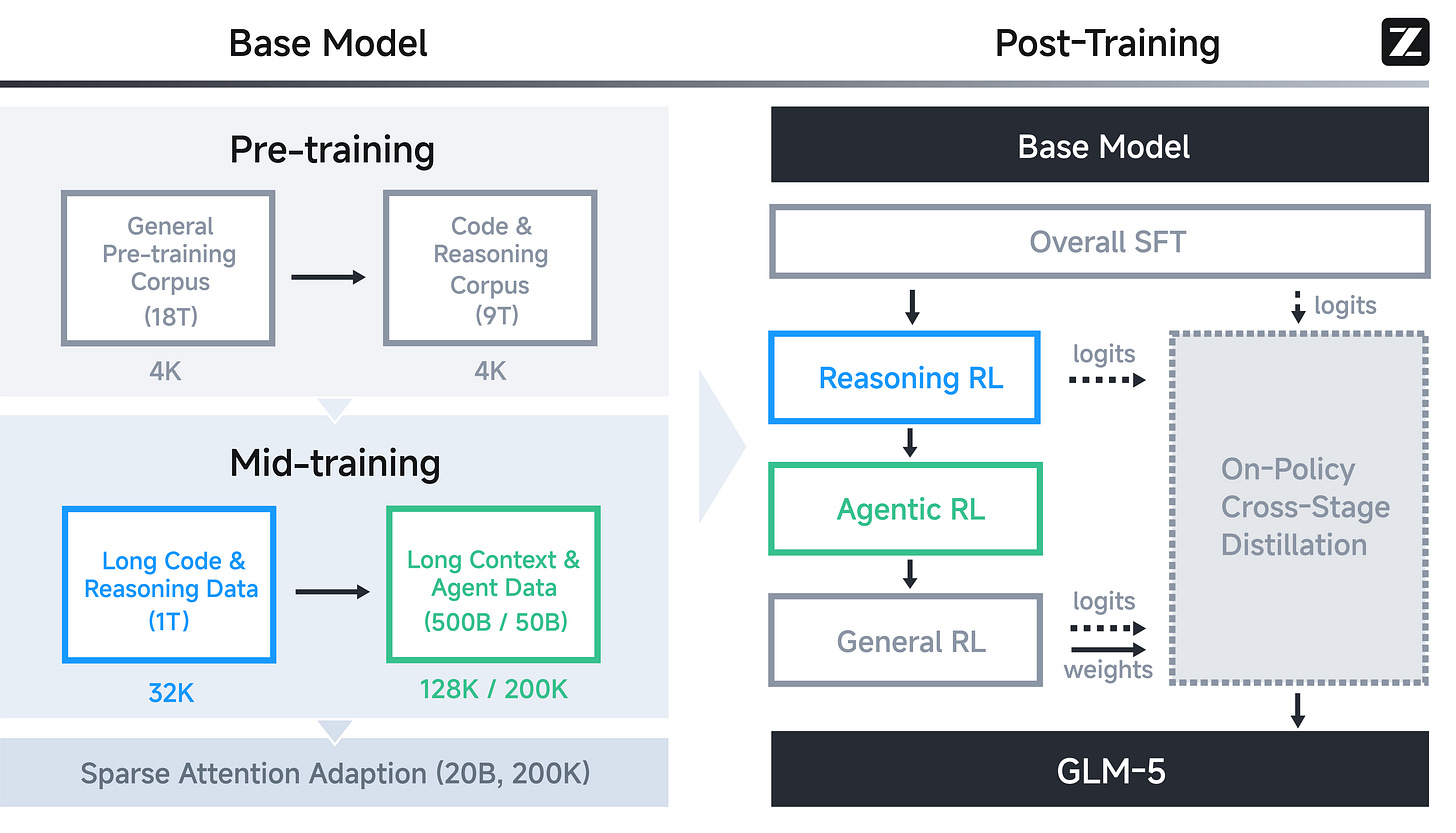
Etapas: Base → SFT → RL de Razonamiento → RL Agéntico → RL General.
¿Qué deja el repaso para equipos open source en Chile y LatAm?
El mensaje práctico para grupos de investigación regional (Ai2-Chile, equipos de la UTFSM, UDP, PUC, U. de Chile, o startups que quieren cocinar su propio modelo desde un Llama o Qwen base) es claro: el camino de receta única SFT-DPO-RL todavía rinde, pero la frontera ya se movió a particionar el problema. La buena noticia: MOPD es organizacionalmente más barato que un RL monolítico, porque cada profesor especialista cabe en un equipo chico y se pueden entrenar en paralelo. Lo malo: necesitás múltiples corridas de RL bien ejecutadas antes de la consolidación, y la consolidación en sí requiere cómputo no trivial para muestrear trayectorias on-policy.
El episodio cubre además los capítulos de carrera profesional en la "carrera LLM" (minuto 48:22), un tema relevante para investigadores latinoamericanos que están decidiendo entre quedarse en academia regional, sumarse a laboratorios open source como Ai2, o moverse a frontier labs cerrados. Disponible en Apple Podcasts, Spotify y YouTube.