Los agentes IA autonomos estan asumiendo todo tipo de tareas para las empresas: rutear flotas de logistica, triagear tickets de soporte, generar codigo y orquestar workflows multi-paso. La pregunta del millon es como se toma un modelo de proposito general y se lo hace excelente en una tarea especifica. La personalizacion le da al agente las capacidades correctas.
NVIDIA publico una guia con nueve tecnicas para personalizar agentes IA, junto con criterios para elegir cual aplica a cada caso.
¿Por que es necesario personalizar un agente IA?
Los modelos foundation vienen con amplias capacidades de lenguaje y razonamiento a partir de los datasets con los que fueron entrenados. Entienden lenguaje y pueden seguir instrucciones, pero los workflows especializados suelen requerir contexto restringido, especializado o propietario.
Personalizar un agente resuelve este desafio modelando como el agente razona bajo restricciones, que herramientas selecciona, como estructura sus outputs y con que confiabilidad ejecuta workflows de dominio.
¿Que tecnicas existen para personalizar un agente?

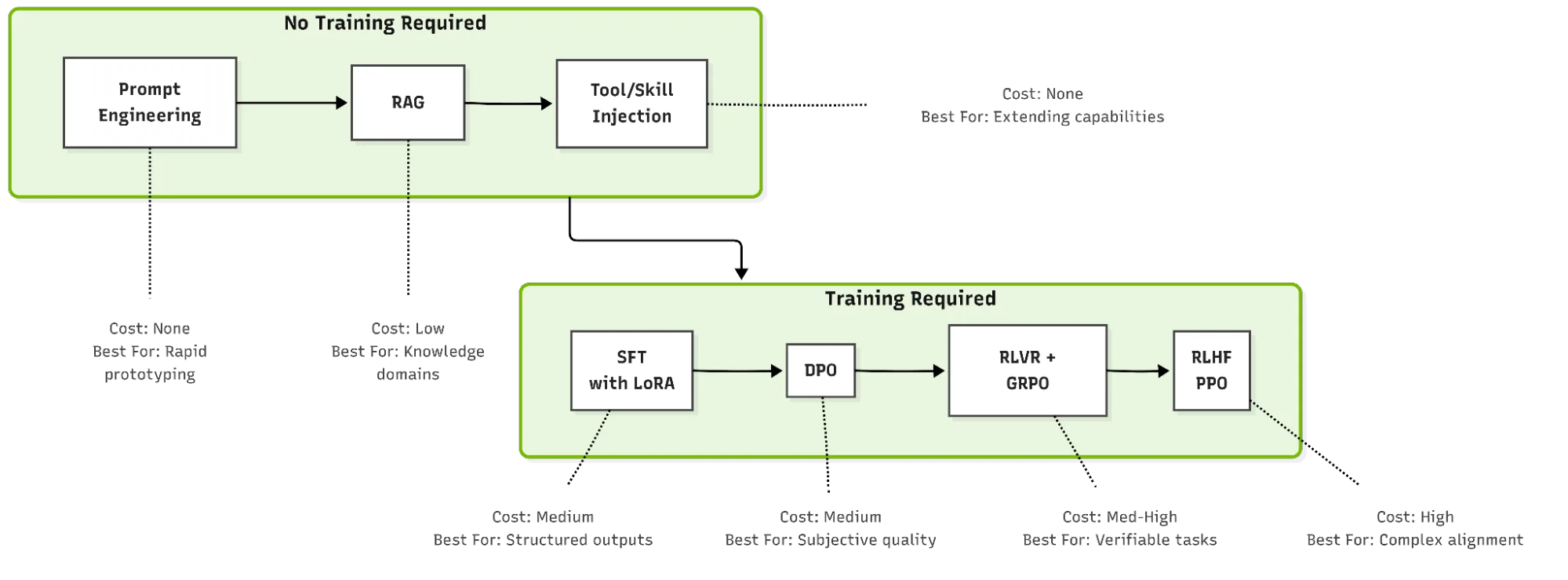
Las tecnicas van desde simples cambios de prompt hasta metodos avanzados como reinforcement learning, cada uno con tradeoffs de costo, complejidad y capacidad. La mejor aproximacion depende de si necesitas mejor informacion, mejores instrucciones o un comportamiento fundamentalmente mas confiable.
Prompt engineering y system prompts
Prompt engineering solo requiere cambiar el prompt al agente en tiempo de inferencia. Es la tecnica mas accesible y tipicamente la primera en aplicarse para personalizar comportamiento. Agentes estandar requieren ajuste humano de system prompts. Agentes avanzados auto-evolutivos como OpenClaw usan prompts que el propio agente actualiza a medida que revisa memoria e instrucciones.
Cuando usarla: iterar rapido sobre comportamiento, prototipar antes de invertir mas, tareas custom descritas claramente en lenguaje natural.
Limitaciones: prompts pueden volverse fragiles para cadenas de razonamiento complejas. Cambiar el modelo que potencia al agente requiere re-testear los prompts. No extiende las capacidades centrales del modelo.
Retrieval-augmented generation (RAG)
RAG resuelve la limitacion de conocimiento de los modelos foundation, recuperando dinamicamente informacion relevante y actualizada desde fuentes externas (por ejemplo, vector databases). Este contenido recuperado se inyecta en el contexto del modelo en tiempo de inferencia, reduce significativamente las alucinaciones y permite responder preguntas sobre dominios propietarios o que cambian rapido, sin reentrenar.
Cuando usarla: dar al agente acceso a conocimiento al dia o propietario, reducir alucinaciones con grounding en fuentes autoritativas, trabajar con knowledge base que cambia frecuentemente.
Limitaciones: agrega latencia por la recuperacion, no suma capacidades de razonamiento nuevas (solo informacion), los limites de ventana de contexto restringen cuanta info recuperada se puede usar.
Inyeccion de herramientas y skills
Tools y skills extienden las capacidades del agente. Tools son funciones invocables que interactuan con software externo (web search, file I/O, shell, API calls). Skills son instrucciones de dominio especifico para completar tareas, organizadas como carpetas con SKILL.md, scripts, templates y ejemplos.
Cuando usarlas: extender lo que el agente puede hacer (no como razona), conectar a software externo o APIs, dar capacidades modulares y reutilizables.
Limitaciones: el modelo necesita tool-calling como capacidad base. Orquestaciones complejas pueden requerir fine-tuning para ser confiables. Las definiciones de skills consumen espacio en la ventana de contexto.
Supervised fine-tuning (SFT)
SFT modifica el comportamiento de un modelo pre-entrenado ajustando los pesos con datasets etiquetados. A diferencia de las tecnicas anteriores que personalizan en inferencia, SFT se hace en tiempo de entrenamiento.
Herramientas de synthetic data generation como NVIDIA NeMo Data Designer aceleran este proceso, especialmente en dominios de bajos recursos donde los ejemplos manualmente etiquetados son escasos. Los equipos definen un schema de datos y usan LLMs para generar pares de entrenamiento diversos y de alta calidad. Luego hacen SFT con ese dataset usando el framework NVIDIA NeMo.
Cuando usarla: trabajar con datos accesibles para tareas bien definidas con ejemplos de output, requerir outputs en formatos especificos (JSON schemas, tool calls).
Limitaciones: la calidad depende enteramente de la calidad del training data. Puede sobre-ajustarse si los datos no son diversos (catastrophic forgetting). Requiere recursos de computo.
Parameter-efficient fine-tuning (PEFT)
Hacer full fine-tuning sobre un modelo de 9.000 millones de parametros requiere recursos de GPU significativos. Los metodos PEFT como Low-Rank Adaptation (LoRA) y Quantized Low-Rank Adaptation (QLoRA) permiten congelar la mayoria de los pesos y modificar solo una fraccion minima de parametros.
LoRA introduce matrices de rango bajo entrenables que se agregan a las capas existentes, lo que reduce drasticamente la huella de entrenamiento. QLoRA agrega cuantizacion para correr el fine-tuning en GPUs de consumo. Para muchos casos de personalizacion de agentes, PEFT ofrece la mejor relacion costo-beneficio.
Direct Preference Optimization (DPO) y RLVR con GRPO
Los metodos avanzados de alineamiento como Direct Preference Optimization (DPO) y reinforcement learning with verifiable rewards (RLVR), frecuentemente combinados con Group Relative Policy Optimization (GRPO), entregan un alineamiento mas matizado y razonamiento mejorado al apalancar señales de preferencia o criterios objetivos de correctitud.
DPO ajusta el modelo directamente sobre pares de respuestas preferidas, sin necesidad de entrenar un modelo de recompensa separado. RLVR usa señales de recompensa verificables (por ejemplo, si un test unitario pasa, si una respuesta matematica es correcta) para guiar el aprendizaje. GRPO compara grupos de respuestas y optimiza relativamente, lo que estabiliza el entrenamiento en tareas donde el reward es esparso.
Tabla resumen: cuando usar cada tecnica
| Tecnica | Cuando aplica | Costo | Modifica pesos |
|---|---|---|---|
| Prompt engineering | Iteracion rapida, prototipos | Bajo | No |
| RAG | Knowledge actualizado o propietario | Medio | No |
| Tools/Skills | Extender capacidades externas | Bajo-Medio | No |
| SFT | Outputs estructurados, dominios definidos | Alto | Si |
| PEFT (LoRA/QLoRA) | Fine-tuning con recursos limitados | Medio | Si (parcial) |
| DPO / RLVR + GRPO | Alineamiento avanzado con preferencias | Muy Alto | Si |
La eleccion no es excluyente: la mayoria de los pipelines productivos combinan prompt engineering + RAG + tools desde el inicio, y agregan SFT o PEFT cuando el comportamiento debe ser mas confiable.