Entrena modelos de IA más rápido con JAX y MaxText usando NVFP4 en NVIDIA Blackwell
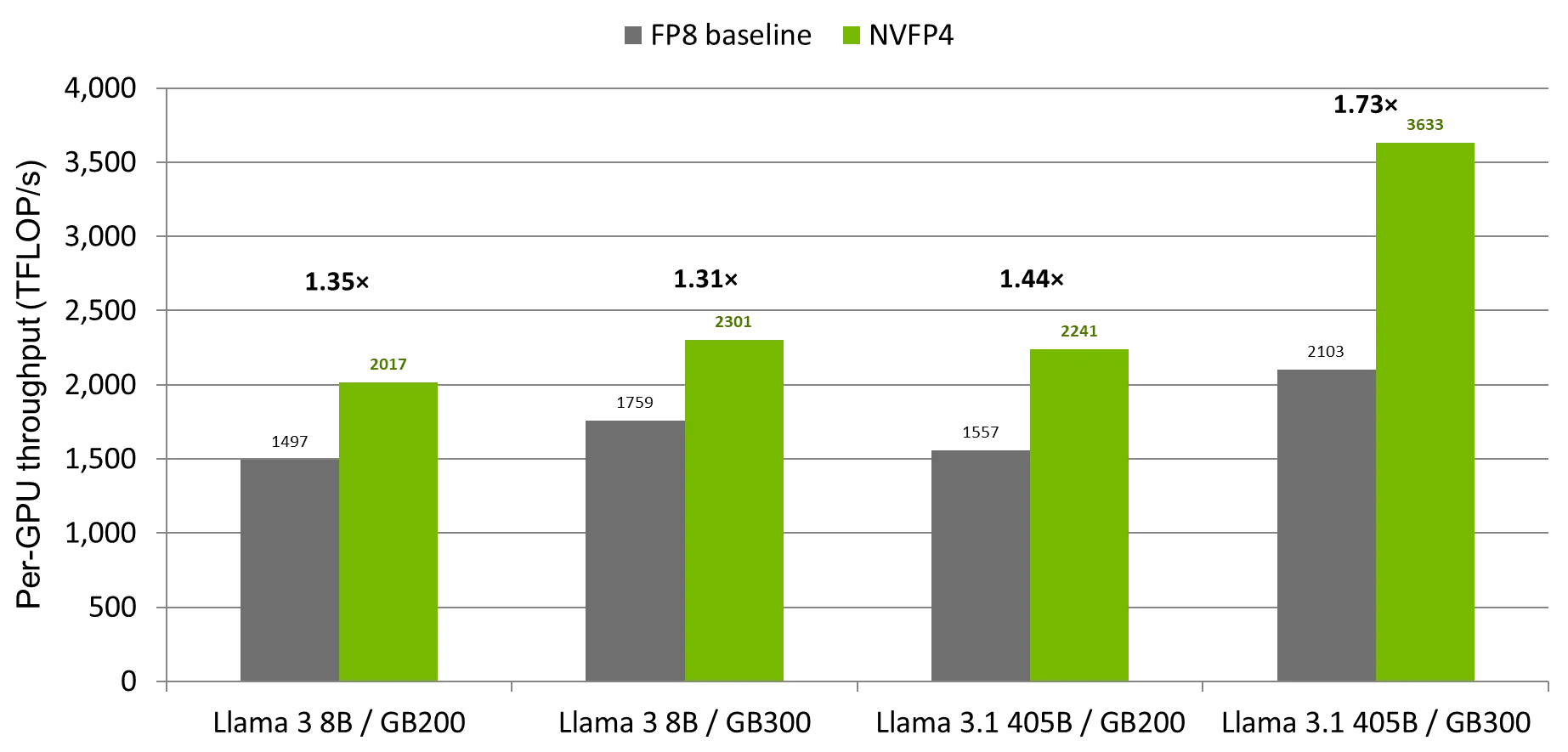
- NVFP4 permite un pre-entrenamiento de alta tasa de transferencia en precisión mixta de 4 bits en las plataformas NVIDIA Blackwell y Rubin, logrando hasta 1.73x de aceleración sobre las líneas base de FP8 con una pérdida de precisión insignificante al aprovechar la precisión subbyte y el soporte nativo de hardware en el NVIDIA GB300 Grace Blackwell Ultra Superchip.
- La receta de entrenamiento NVFP4 para JAX (tal como se implementa en MaxText) preserva la convergencia en el entrenamiento de LLM a gran escala a través de cinco técnicas principales: escalado de microbloques de 16 elementos, factores de escala de bloque E4M3 bajo una escala FP32 por tensor, Transformada de Hadamard Aleatoria selectiva para entradas WGRAD, escalado 2D FP8 por bloque de pesos de 16x16 y redondeo estocástico para una cuantización sin sesgo.
- Las operaciones GEMM en las capas MLP de los transformadores se cuantizan a NVFP4, mientras que los bloques de atención permanecen en una precisión mayor para evitar la amplificación del ruido de cuantización de la softmax; los resultados empíricos en Llama 3 8B y Llama 3.1 405B muestran ganancias significativas de rendimiento en hardware NVIDIA GB200 y GB300 sin degradación medible en la pérdida final del modelo.
El contenido generado por IA puede resumir información de manera incompleta. Verifique la información importante. Aprenda más
El pre-entrenamiento de LLM de frontera se reduce a la tasa de transferencia (throughput). Cuando el entrenamiento abarca billones de tokens a través de miles de aceleradores, cada punto porcentual en el tiempo de paso puede sumarse a días de entrenamiento y costos de cómputo sustanciales. La precisión numérica es uno de los controles de mayor apalancamiento disponibles, pero el pre-entrenamiento de precisión mixta de pocos bits es difícil de lograr correctamente.
Para abordar esto, la receta de entrenamiento NVFP4 en TransformerEngine utiliza precisión subbyte para el pre-entrenamiento en JAX. Para un ejemplo integral, consulte la receta en MaxText, una biblioteca de framework de LLM escalable y de alto rendimiento. El resultado es un pre-entrenamiento de alta tasa de transferencia y precisión mixta de 4 bits en NVIDIA Blackwell sin pérdida de precisión medible en comparación con la línea base FP8.
Esta publicación explica el formato NVFP4 y cómo está diseñado para lograr un alto rendimiento y precisión a una precisión ultra baja. También muestra cómo aplicar una receta de pre-entrenamiento NVFP4 en MaxText y recopilar datos de rendimiento que demuestran las ganancias obtenidas. Para detalles de metodología, consulte el paper de pre-entrenamiento NVFP4.
Formato NVFP4 y beneficios
Esta publicación introductoria sobre NVFP4 explica su formato y cómo el microescalado de dos niveles codifica señales más altas con menos error que otros formatos de microescalado. También explica cómo el soporte de hardware nativo de NVFP4 en el NVIDIA GB300 Grace Blackwell Ultra Superchip ofrece 7 veces el rendimiento GEMM en comparación con la precisión FP8 nativa en NVIDIA Hopper. Ese mayor rendimiento, junto con la receta de pre-entrenamiento NVFP4, acorta el tiempo de paso de entrenamiento con una pérdida de precisión insignificante. Esto permite a las fábricas de IA entrenar más modelos y de mayor tamaño dentro del mismo presupuesto de tiempo, o entrenar modelos más rápido con un presupuesto de tiempo menor.
Receta de pre-entrenamiento NVFP4
La receta NVFP4 combina varios ingredientes que juntos preservan la convergencia mientras desbloquean el rendimiento de NVFP4 en NVIDIA Blackwell y la plataforma NVIDIA Rubin. Para permitir un entrenamiento eficiente de precisión estrecha, la receta de pre-entrenamiento utiliza varias técnicas clave elegidas en función de su rendimiento y precisión.
Cinco ingredientes clave trabajan juntos manteniendo la precisión requerida en el pre-entrenamiento de 4 bits:
- Escalado de microbloques: utiliza bloques de 16 elementos, la mitad del tamaño de los bloques de 32 elementos de MXFP4, por lo que un solo valor atípico tiene menos influencia en la escala compartida.
- Factores de escala de bloque E4M3: utiliza bits de mantisa en lugar del escalado E8M0 de potencia de dos de MXFP4, superpuesto bajo una escala FP32 por tensor. En un experimento de 8 mil millones de parámetros y 1 billón de tokens, MXFP4 requiere ~36% más de tokens para igualar la pérdida final de NVFP4.
- Transformada de Hadamard Aleatoria: se aplica solo a las entradas GEMM WGRAD para gaussificar valores atípicos. La receta omite FPROP y DGRAD porque transformar esas rutas también requeriría transformar el peso, rompiendo la consistencia de escala 2D.
- Escalado de pesos 2D: utiliza una escala FP8 por cada bloque de peso de 16x16, por lo que FPROP y su DGRAD transpuesto usan la misma escala. Las activaciones y gradientes mantienen un escalado de 1x16 de menor sobrecarga.
- Redondeo estocástico: utiliza redondeo sin sesgo para evitar que las actualizaciones diminutas sean aplastadas a cero. Los pesos y activaciones permanecen en redondeo al más cercano-par, donde el redondeo estocástico amplificaría el error en su lugar. Ambos modos son nativos de las instrucciones de conversión FP4 de Blackwell.
La Figura 1 muestra el flujo de datos NVFP4 dentro de una capa lineal.
Los tres GEMM: FPROP (hacia adelante), DGRAD (gradiente de activación) y WGRAD (gradiente de peso) se cuantizan a NVFP4 solo para las capas MLP (feed-forward) del transformador; los GEMM dentro del bloque de atención (proyección QKV, proyección de salida de atención y los matmuls de puntuación/contexto) permanecen en mayor precisión.
NVFP4 se aplica primero a las capas MLP porque la softmax de la atención amplifica exponencialmente el ruido de cuantización en las puntuaciones QK^T. Las activaciones de atención también transportan valores atípicos concentrados que la precisión de 4 bits no puede representar bien. Debido a que los MLP representan la mayoría de los FLOPs de entrenamiento, esto captura la mayor parte de la aceleración sin arriesgar la convergencia.

Los tres GEMM de MLP consumen entradas NVFP4 y emiten salidas BF16, que eventualmente se integran en un peso maestro FP32 en el paso del optimizador. La misma ruta hace visibles las elecciones de preservación de convergencia de la receta: cuantización de bloque 2D en los pesos (valores FPROP/DGRAD consistentes a través de la transposición), una Transformada de Hadamard Aleatoria en las entradas WGRAD (aplana los valores atípicos antes de la cuantización de 4 bits) y redondeo estocástico en los cuantizadores de gradiente (mantiene las pequeñas actualizaciones sin sesgo).
Habilitando NVFP4 en MaxText
La receta NVFP4 de MaxText está disponible en el repositorio de GitHub de JAX-Toolbox. El script de lanzamiento entrena Llama 3 8B con NVFP4 en Blackwell. Para habilitarlo, establezca el flag de cuantización en MaxText para cambiar a la ruta NVFP4. Se exponen dos modos:
- quantization=te_nvfp4: NVFP4 con Transformada de Hadamard Aleatoria. Recomendado cuando la convergencia bajo te_nvfp4_no_rht no es satisfactoria.
- quantization=te_nvfp4_no_rht: NVFP4 sin RHT. Menor sobrecarga, pero puede degradar la calidad de la convergencia.
Ejecute el script de ejemplo desde la raíz del repositorio de MaxText dentro de un contenedor que tenga instalados JAX, NVIDIA Transformer Engine y las bibliotecas NVIDIA CUDA/cuDNN requeridas. Se recomienda el contenedor público NVIDIA MaxText ghcr.io/nvidia/jax:maxtext.
El siguiente es un ejemplo parcial del script de entrenamiento NVFP4 de Llama3 8B en MaxText, que declara el argumento nvfp4 a través de Transformer Engine:
RUN_SETTINGS="-m maxtext.trainers.pre_train.train maxtext/configs/base.yml run_name=debug_run base_output_directory=./debug_logs hardware=gpu dataset_type=synthetic model_name=llama3-8b remat_policy='minimal_with_context_and_quantization' scan_layers=False attention='cudnn_flash_te' steps=50 dtype=bfloat16 max_target_length=8192 per_device_batch_size=4 ici_data_parallelism=${ici_DP} dcn_data_parallelism=${dcn_DP} ici_fsdp_parallelism=${ici_FSDP} dcn_fsdp_parallelism=${dcn_FSDP} profiler=nsys enable_checkpointing=false override_model_config=True gradient_accumulaVía NVIDIA Developer.